文本分类(二)专栏主要是对Github优秀文本分类项目的解析,该文本分类项目,主要基于深度学习模型,包括TextCNN、TextRNN、FastText、TextRCNN、BiLSTM_Attention、DPCNN、Transformer,使用PyTorch实现。
目录
1. 项目特点
相比于文本分类(一),它主要有以下几个不同:
1)提供了一种不同的数据预处理方式。文本分类(一)中我们使用的是THUCNews完整数据集,每条数据都是完整的新闻,属于篇章分类;文本分类(二),我们使用的是THUCNews的一个子集,每条数据都是从新闻中抽取的标题,属于标题(短文本)分类。之前我们是提前把数据预处理好,存储为数组或tensor的格式,训练时再从文件中加载,适合数据量比较大的情况;现在我们预处理和训练同时进行,将数据预处理完接着进行训练,不需要存储为中间文件,适合数据量比较小的情况。
2)数据生成器:当数据比较大时,没办法一次性把数据全部加载到内存或显存中,此时我们可以使用数据生成器。训练时,不是把全部数据都加载到内存或显存中,而是用到哪一部分数据(某个batch),就用数据生成器生成该部分数据,只把这部分数据加载到内存或显存中,避免溢出。在文本分类(一)中,我们把预处理好的数据想封装为Dataset对象,再使用DataLoader进行加载(PyTorch内置);在文本分类(二)中,我们自定义数据生成/迭代器。
3)词典/字典构造方式:处理文本时,我们需要先基于数据构造一个词典/字典(可以先去除低频词/字、停用词/字)。文本分类(一)中我们使用TorchText的Vocab函数帮助我们构建词典/字典;达观杯中我们使用Keras内置的Tokenizer等函数帮助我们构建词典/字典;文本分类(二)中我们自定义一种构建词典/字典的方式。然后把文本中的词或字转变为词典或字典中的索引。
4)文本分类(二)中主要是基于character-level,文本以字为间隔进行分割,当然也提供了word-level的版本;文本分类(一)中主要基于word-level,文本以词为间隔进行分割(需要使用一些分词工具,如jieba)。
5)命令行工具:文本分类(一)把项目所有相关的超参数都集中在一个文件中,若要修改配置,可以利用fire工具在命令行进行覆盖;文本分类(二)使用的是argparse工具,每个模块都有一个对应的配置类,包含该模块的超参数(超参定义和模型定义在一个文件中)。
6)使用模型:文本分类(一)和文本分类(二)所使用的模型差不多,都是一些基于深度学习的模型。不同在于,文本分类(二)的FastText模型增加了bi-gram、tri-gram特征,且增加了Transformer模型(利用transformer encoder进行分类)。
上述是两个项目主要的不同,当然还有一些编码风格和一些具体细节的差异,之后的几篇博客,我会详细介绍。多解析一些相关项目,不仅可以加深我们对该领域的理解,还可以掌握一些不同的编码风格,可以让我们在编程时根据不同的情况有更多选择、更灵活,而且可以更容易的看懂别人优秀的开源代码。
2. 数据集
在THUCNews中抽取20w新闻标题,文本长度在20-30之间,一共10个类别,每个类别2万条。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集划分:训练集18w(每个类别18,000条),验证集和测试集各1w(每个类别1000条)。
3. 项目组织结构
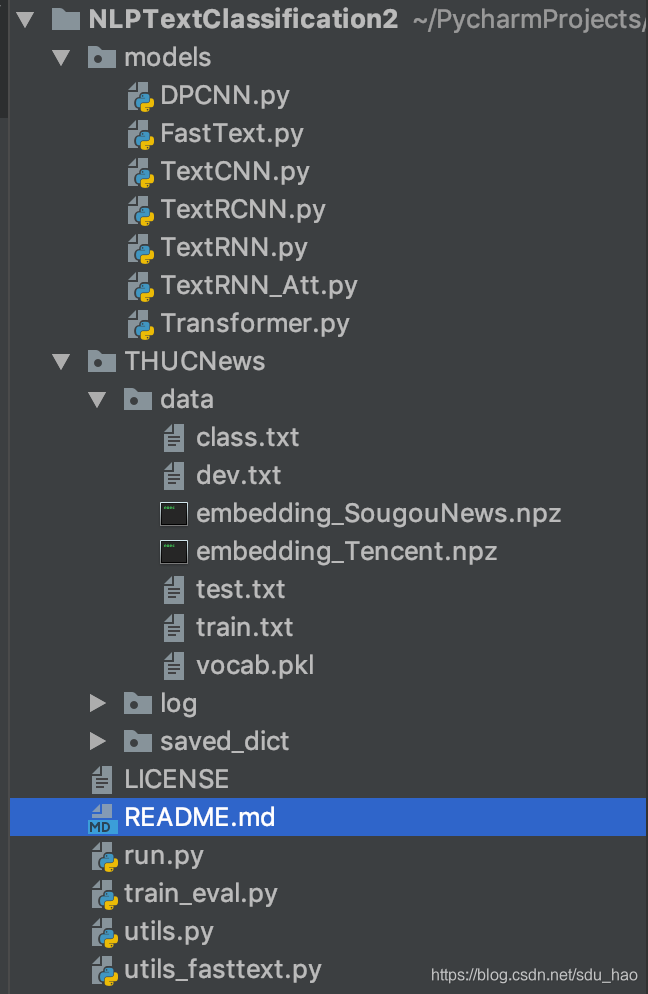
1)models:各个模型的定义以及各自超参数定义
2)THUCnews/data:存储训练集、验证集、测试集(处理成txt格式,每条数据一行,格式:文本<tab>标签);构建好的字典/词典;预训练词向量/字向量(可以使用开源的词向量/字向量(推荐),也可以自己基于数据集训练(word2vec,glove,fasttext)).
3) THUCnews/log:日志
4) THUCnews/saved_dict:训练好的参数文件
5)run.py:程序入口
6)train_eval.py:定义训练、验证、测试函数
7)utils.py:定义数据预处理和加载的函数
8)utils_fasttext.py:定义数据预处理和加载的函数(fasttext增加了bi-gram、tri-gram特征)
4. 使用方式
训练并测试:
python --model ModelName(必填,如TextCNN、DPCNN等) --embedding pre_trained(默认)/random --word False(默认 character-level)/True其他各个模型相关的超参数,可以在各个模型对应的配置类中手动设置。

如果想以词为间隔,首先对文本进行分词,将数据集保存为.txt,每行为一条数据,格式:文本(分词,空格隔开)<tab>标签。
python run.py --model TextCNN --word True
