我们知道,tfidf和embedding都是将文本表示成包含文本信息的高维向量的方法。tfidf关注的是单词在文档中的频率,最终计算出的向量包含的信息是一种单词出现频率的tradeoff。而embedding则关注的是单词的语义。两者包含的信息不同,因此将两者结合起来表示文本是对文本信息的丰富和扩充。
但是在实际操作中,两者的结合不是简单的concatenate这个简单就可以的。因为两者计算结果的维度是不同的,比如一个长度为n句子,我们对其进行tfidf,也就是每一个单词会获得一个标量的TFIDF值,这样一个句子就被表示成了一个1 n维的矩阵。但是对这个句子进行embedding后,假设每个单词被映射成了一个m维的向量,那么整个句子最终就被表示成了m n维的矩阵。一般来说,m的值在几百的大小,因此这两个矩阵直接串联的话,tfidf矩阵站的比重就非常小,其表示的意义和信息就不能很好的被利用。
我的想法是这样的:因为tfidf值表示的是一种频率的权衡,也可以看做是一种权重,所以我们可以用tfidf去给句中的每个单词的embedding向量做一种加权,这样可以得到一个句子的tfidf+embedding的向量表示形式。这个向量表示的维度是1 m的,其中包含了tfidf和embedding的信息,可以拿来放到机器学习的分类器中进行分类了,比如xgboost等等。
到这里我们可以进一步想一下,这个得到的向量包含了tfidf和embedding的信息,维度是1 m的,从形状上和直观理解上,这个向量是tfidf和embedding信息的压缩,也就是说虽然包含了两者的信息,但实际上是有信息损失的。特别是对于embedding来说,由一个m n维的矩阵变成1 m的,必定减少了很多信息。而且现在对于文本转换为向量用的最多的就是embedding,所以到上一步就停止我们的操作不是最优解。
所以我们继续,我们想要扩充上一步得到的维度是1 m的向量,最好是可以得到一个和embedding矩阵相同形状的矩阵,这样后面我们可以将两个矩阵连接起来,得到一个信息更加完整丰富的矩阵。怎么得到这个矩阵呢?我们前面还有一个tfidf的矩阵,是一个一个1 n维的矩阵,如果把这两个矩阵做乘积,那么得到矩阵恰好就是与embedding矩阵形状相同了。然后我们将其与embedding矩阵连接起来,得到一个m 2n维的矩阵,就是最终的结果了。
上面的过程可以表示成下面的图:
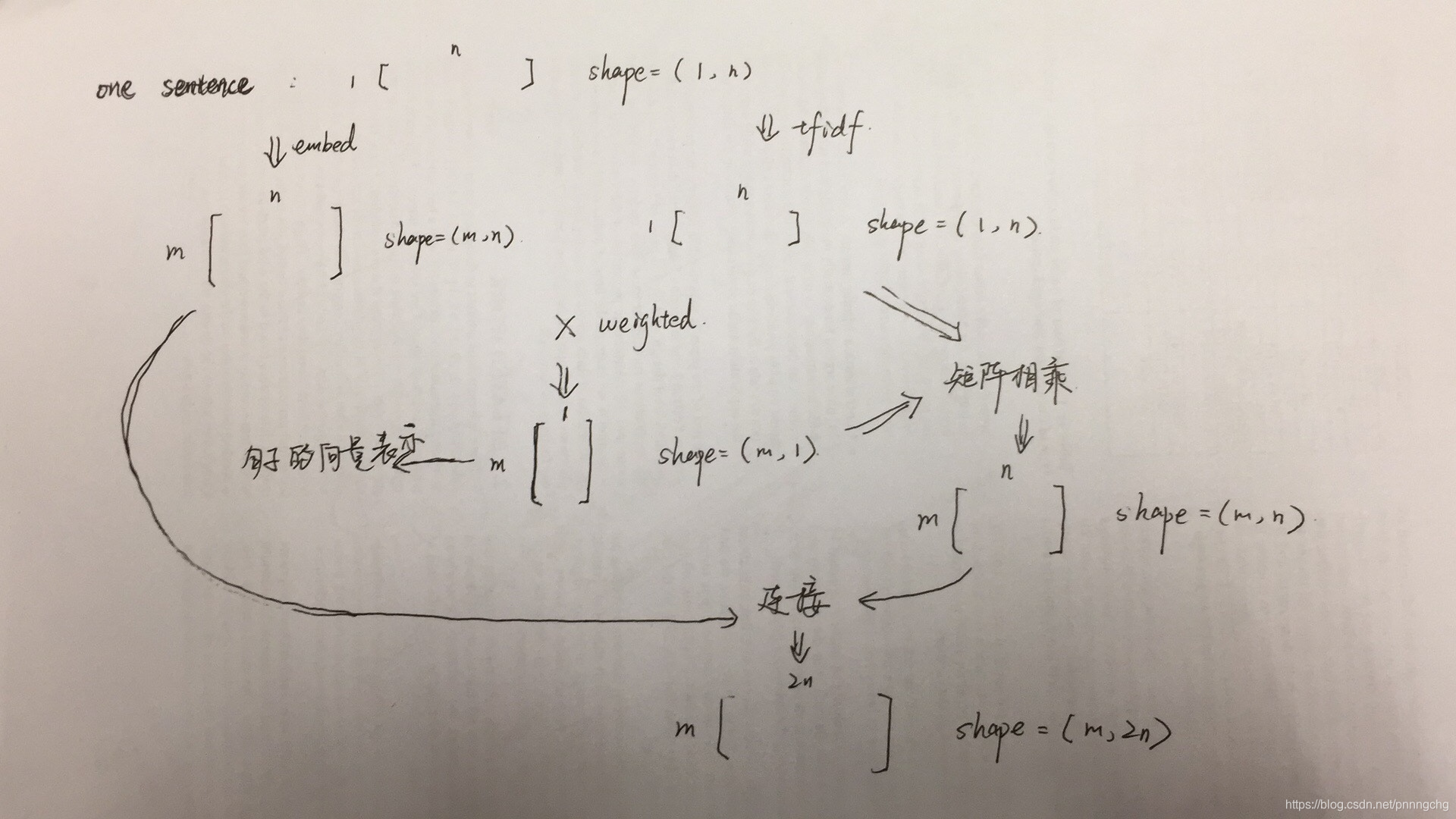
在做的一个分类比赛里,使用上面的方法将文本表示成向量输入模型中,最终f1值比单纯使用embedding提高了一个百分点。
注:在实际计算tfidf的时候,有三种方法可以选择,使用sklearn或者gensim的接口,自己计算。三种方法各有利弊,我们下一篇单独讲一下三种方法分别怎么用。