HashMap的底层数据结构
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
Entry 存储Key——value 映射
HashMap底层数据结构是有数组+链表的形式,初始化HashMap的时候创建一个固定大小的Entry数组,数组中每个元素的又是有个链表数据结构
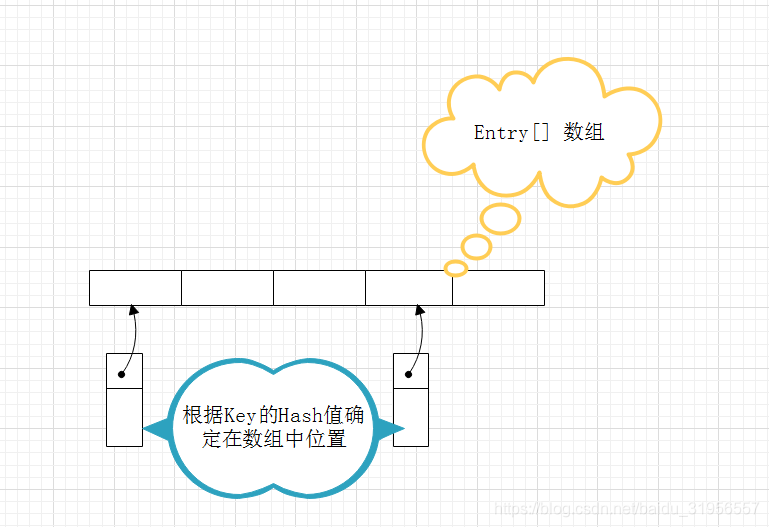
HashMap 数据添加和获取底层实现原理
HashMap初始化
通过以上我们知道HashMap其实底层就是一个链表形式的数组,那么这个数组的长度是多少呢?我们可以通过构造方法来看下:
/**
初始化一个 长度为16的数组,加载因子是 0.75 ,当数组长度达到 16*0.75=12 的时候就开始扩容
**/
public HashMap()
/**
初始化一个 长度为initialCapacity 的数组,加载因子是 0.75 ,当数组长度达到
initialCapacity*0.75 的时候就开始扩容
**/
public HashMap(int initialCapacity)
/**
初始化一个 长度为initialCapacity 的数组,加载因子是 loadFactor ,当数组长度达到
initialCapacity*loadFactor 的时候就开始扩容
**/
public HashMap(int initialCapacity, float loadFactor)
HashMap put 数据
当我们put(key,value) key-value键值对放到HashMap的时候,首先会根据key的hash值去得到数组中的下标,决定该 Entry 的存储位置,如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry的 value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部,如果hash值不同
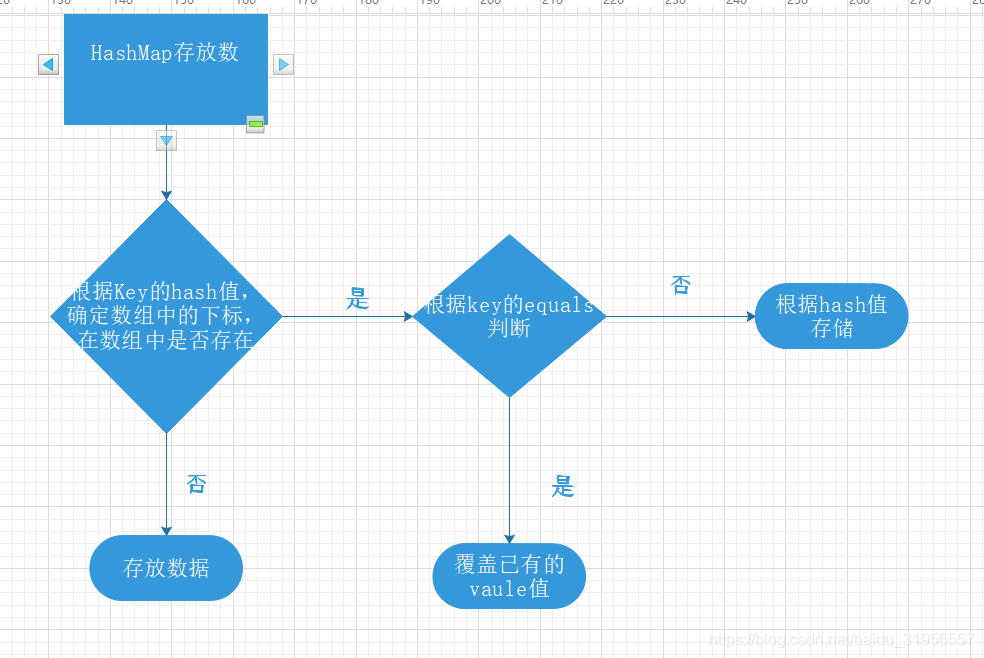
HashMap get 数据
首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
HashMap 实现原理总结:
HashMap底层采用数组+链表的数据结构,根据Key的hashCode方法计算 hash值确定在数组中的下标,如果 两个key的hash值相同,则根据key的equals的返回值,返回false则 存储到链表中,如果返回true 则覆盖之前的value,如果两个key的hash值不相同,则正常存储,取出数据的时候也是根据key的Hash值和key的equals去取出数据元素。
