一、LRU Cache
LRU Cache(最近最少使用缓存机制):当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间
LRU Cache工作示例:
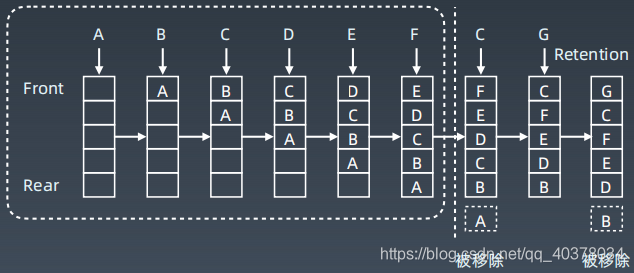
LRU Cache一般使用哈希表+双向链表来实现,支持时间复杂度为 的查询、修改、更新操作
二、LinkedHashMap源码分析2.0
LinkedHashMap源码分析1.0:https://blog.csdn.net/qq_40378034/article/details/102730778
LinkedHashMap支持两种访问访问顺序,这主要取决于accessOrder这个参数的值,当accessOrder为false时按照插入顺序访问(默认),当accessOrder为true时按照LRU Cache的机制进行访问
//initialCapacity:初始化容量 loadFactor:负载因子 accessOrder:访问顺序(true代表使用LRU/false代表使用插入的顺序)
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
当某个位置的数据被命中,通过调整该数据的位置,将其移动至尾部。新插入的元素也是直接放入尾部(尾插法)。这样一来,最近被命中的元素就向尾部移动,那么链表的头部就是最近最少使用的元素所在的位置
LinkedHashMap中并没有覆写任何关于HashMap的put方法,所以调用LinkedHashMap的put方法实际上调用了父类HashMap的方法
HashMap中put方法源码如下:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断当前桶是否为空,空的就需要初始化(resize中会判断是否需要初始化)
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据当前key的hashcode定位到具体的桶中并判断是否为空,为空表明没有Hash冲突就直接在当前位置创建一个新桶即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果当前桶有值(Hash冲突),那么就要比较当前桶中的key、key的hashcode与写入的key是否相等,相等就赋值给e,后面统一进行赋值及返回
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果当前桶为红黑树,按照红黑树的方式写入数据
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果是个链表,就需要将当前的key、value封装成一个新节点写入当前桶的后面(采用尾插法)
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果在遍历链表的过程中,找到key相同时直接退出遍历
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果e!=null就相当于存在相同的key,那就需要将值覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//最后判断是否需要进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
在putVal方法中如果map中存在相同的key时,会调用void afterNodeAccess(Node<K,V> p)方法,该方法在HashMap中是空实现,但是在LinkedHasMap中重写了该方法实现了将被访问节点移动到链表最后
//将被访问节点移动到链表最后
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//accessOrder为true时才支持LRU Cache
if (accessOrder && (last = tail) != e) {
//三个临时变量:p为当前被访问节点,b为其前驱结点,a为其后继节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//访问节点的后驱节点置为null
p.after = null;
//如果访问节点的前驱为null,则说明p=head,由于这时p要移动到链表最后,所以a设置为head
if (b == null)
head = a;
//否则b的后继设置为a
else
b.after = a;
//如果p不为尾节点,那么将a的前驱设置为b
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
//将p接在双向链表的最后
tail = p;
++modCount;
}
}
举个例子,比如该次操作访问的是13这个节点,而14是其后驱,11是其前驱,且tail=14。在通过get访问13节点后,13变成了tail节点,而14变成了其前驱节点,相应的14的前驱变成11,11的后驱变成了14,14的后驱变成了13


而在putVal方法的最后会调用一个void afterNodeInsertion(boolean evict)方法,,该方法在HashMap中是空实现,但是在LinkedHasMap中重写了该方法实现了删除头节点(最近最少使用的元素)
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {//(1)
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
代码(1)处:evict在put方法调用putVal时传参即为true,所以当map不为空且removeEldestEntry返回true时就会删除头节点,但是在LinkedHasMap中removeEldestEntry方法始终返回true,所以如果要基于LinkedHashMap实现LRU则需要重写removeEldestEntry方法,当map的size大于初始化容量时返回true
参考:https://juejin.im/post/5ace2bde6fb9a028e25deca8
三、LeetCode146:LRU缓存机制
运用你所掌握的数据结构,设计和实现一个LRU(最近最少使用)缓存机制。它应该支持以下操作:获取数据get和写入数据put
获取数据get(key):如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回-1
写入数据put(key, value):如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
题解1:
public class LRUCache extends LinkedHashMap<Integer, Integer> {
private int capacity;
public LRUCache(int capacity) {
//initialCapacity:初始化容量 loadFactor:负载因子 accessOrder:访问顺序(true代表使用LRU/false代表使用插入的顺序)
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
题解2:
解题思路:哈希表+双向链表(头尾虚节点)
public class LRUCache {
//key -> Node(key, val)
private HashMap<Integer, Node> map;
//Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
//最大容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
public int get(int key) {
if (!map.containsKey(key))
return -1;
int val = map.get(key).val;
//利用put方法把该数据提前
put(key, val);
return val;
}
public void put(int key, int val) {
//新节点node
Node node = new Node(key, val);
if (map.containsKey(key)) {
//删除旧的节点,新的插到头部
cache.remove(map.get(key));
cache.addFirst(node);
//更新map中对应的数据
map.put(key, node);
} else {
if (cap == cache.size()) {
//删除链表最后一个数据
Node last = cache.removeLast();
map.remove(last.key);
}
//直接添加到头部
cache.addFirst(node);
map.put(key, node);
}
}
class Node {
public int key, val;
public Node prev, next;
public Node(int k, int v) {
this.key = k;
this.val = v;
}
}
class DoubleList {
private Node head, tail; //头尾虚节点
private int size; //链表元素数
public DoubleList() {
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0;
}
//在链表头部添加节点node
public void addFirst(Node node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
size++;
}
//删除链表中的node节点(node一定存在)
public void remove(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
size--;
}
//删除链表中最后一个节点,并返回该节点
public Node removeLast() {
if (tail.prev == head)
return null;
Node last = tail.prev;
remove(last);
return last;
}
//返回链表长度
public int size() {
return size;
}
}
}
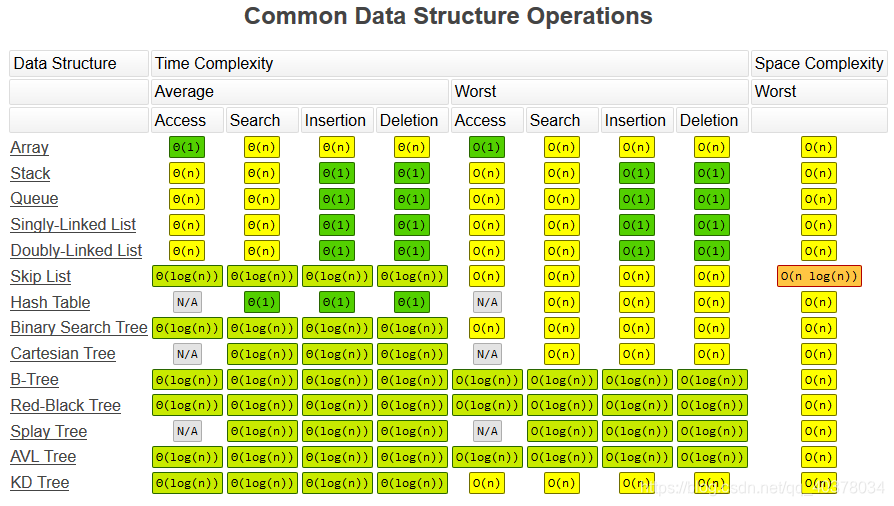
常用数据结构的时间、空间复杂度:
https://www.bigocheatsheet.com/
