最近一直在琢磨Generative Adversarial Imitation Learning这篇文章的内容和实现,也自己实现了几个GAN,但是效果都不是很理想,因此找到了一篇专门讲提升GAN表现的文章,用几个小时的时间把这篇文章翻译一下。
原文链接:GAN — Ways to improve GAN performance
相较于其他的神经网络,GAN在下面几个方面遇到的问题更为严重:
(1)不收敛:模型永不收敛,甚至,模型及其不稳定(unstable)
(2)模式坍塌(mode collapse):生成器只生成有限的几种模式。
(3)训练速度慢:会遇到梯度消失的问题。
这篇文章主要讲提升GAN表现的方法,重点放在以下几个方面:
(1)为一个更好的优化目标改变cost function
(2)为cost function添加额外的惩罚
(3)避免overconfidence和overfitting
(4)优化模型的更好方法
(5)添加标签
特征匹配
生成器为了欺骗识别器而去生成最好的照片。在生成器和识别器在不断尝试去战胜他们的对手的时候,这“最好的”照片是在不断改变的。然而,有的时候这个优化过程可能会变得太贪心,这个对抗的过程变成了永不停息的猫捉老鼠的游戏。在这种情况下,不收敛和模式坍塌的问题便出现了。
特征匹配改变了生成器的cost function,以最小化真实图像和所生成图像的特征之间的统计差异。通常,我们测量其特征向量的均值之间的L2距离。在这种情况下,优化的目标由打败对手变成了匹配真实图片的特征。这是新的目标函数:
f(x)是从识别器的immediate layer中直接提取的特征向量。
(当训练结果不稳定的时候考虑特征匹配的方法)
小批量歧视(minibatch discrimination)
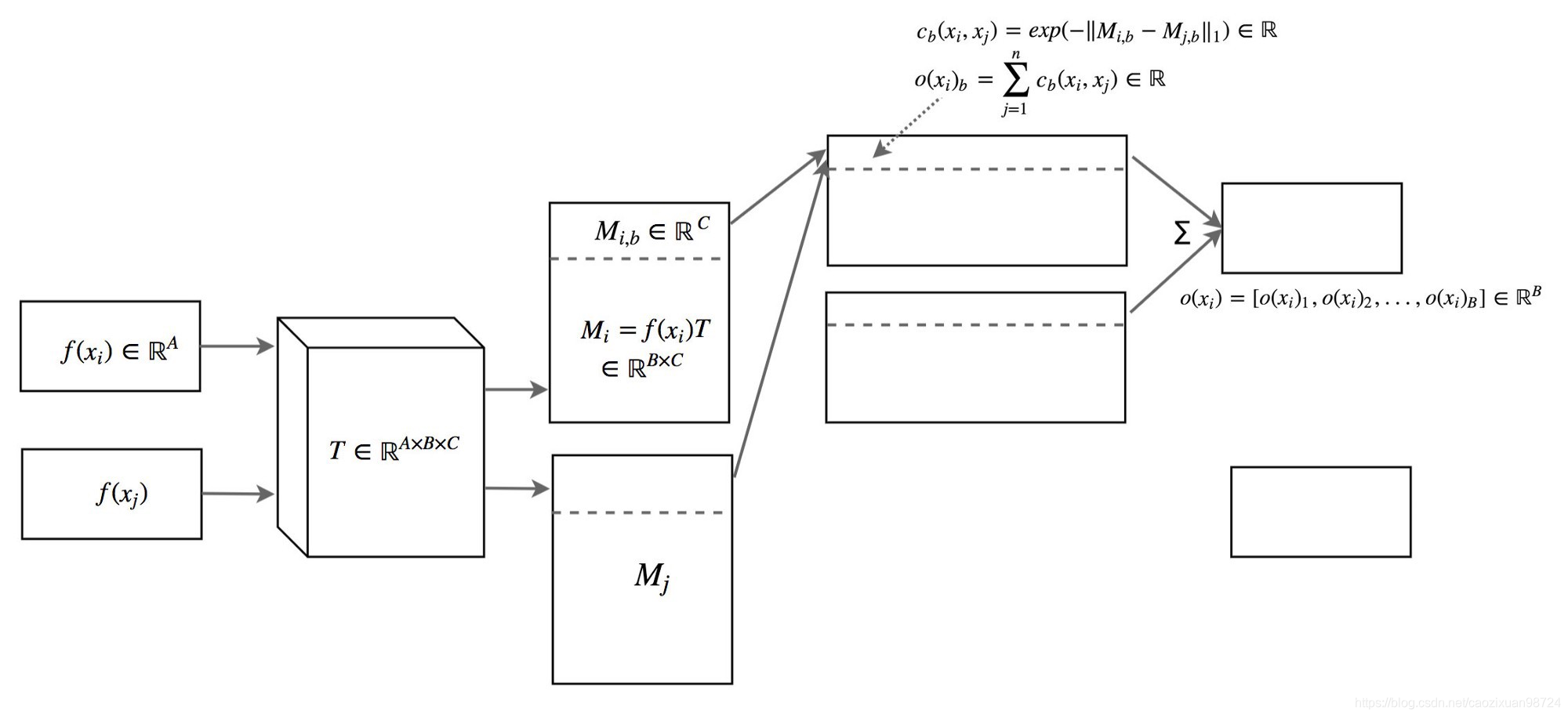
模式坍塌时,所有创建的图像看起来都相似。为了缓解该问题,我们将不同批次的真实图像和生成的图像分别输入到鉴别器中,并计算图像x与同一批次中图像的相似度。我们将相似度o(x)附加到鉴别器的密集层(dense layers)之一中,以对该图像是真实图像还是生成图像进行分类。

如果模式开始崩溃,则生成图像的相似度会增加。因此,如果模式坍塌,识别器可以使用该分数检测生成的图像并惩罚生成器。
图片xi与其他图片的的相似度o(xi)可以通过一个转置矩阵T求解。这个式子比较难以追溯,但是概念比较好理解。你可以跳过下节关于这个式子的解释。(式子的解释我就不翻译了,hhh)
 单面标签平滑( onesided label smooth)
单面标签平滑( onesided label smooth)
深度神经网络可能变得过度自信,只用很少的特征就进行分类。针对这种情况我们使用regulation和dropout来缓解。
在GAN中,如果辨别器只依赖于少部分特征进行识别,就有可能导致生成器仅仅生成这一小部分特征,如果这种优化变得过于贪婪,那么我们就要考虑惩罚辨器超过0.9的预测。如下伪代码所示,我们对于目标标签不标记1.0,而是标记0.9:
p = tf.placeholder(tf.float32, shape=[None, 10])
# Use 0.9 instead of 1.0.
feed_dict = {
p: [[0, 0, 0, 0.9, 0, 0, 0, 0, 0, 0]] # Image with label "3"
}
# logits_real_image is the logits calculated by
# the discriminator for real images.
d_real_loss = tf.nn.sigmoid_cross_entropy_with_logits(
labels=p, logits=logits_real_image)历史平均
在历史平均中,我们跟踪最后t个模型的模型参数。或者,如果需要保持较长的模型序列,则可以更新模型参数的运行平均值。
我们在成本函数下方添加一个L2成本,以惩罚与历史平均值不同的模型。
经验回放(experience replay)
使用标签
cost function
使用一些技巧
- 在-1和1之间缩放图像像素值。将tanh用作生成器的输出层。
- 对具有高斯分布的z进行实验采样。
- 批量标准化通常可以稳定训练。
- 使用PixelShuffle并转置卷积进行上采样。
- 避免最大池化以进行下采样。使用卷积步幅。
- Adam优化器通常比其他方法更好。
- 在将真实和生成的图像馈入鉴别器之前,请对其添加噪声。
Virtual batch normalization (VBN)
批量标准化BM已经成为许多神经网络事实上的标准,BM的均值和方差是从当前的最小批量得出的。但是,它会在样本之间产生依赖性。生成的图像彼此不独立。这反映在实验中,会导致相同批次实验生成的图像显示相同的色彩。
最初,我们从随机分布中采样z,从而获得独立的采样。但是,批次归一化所产生的偏差使z的随机性不堪重负。
虚拟批次归一化(VBN)在训练之前对参考批次进行采样。在前向遍历中,我们可以预选参考批次以计算BN 的归一化参数(μ和σ)。但是,由于我们在整个训练过程中使用相同的批次,因此我们将对此参考批次过度拟合模型。为了减轻这种情况,我们可以将参考批次与当前批次结合起来以计算归一化参数。
随机种子
用于初始化模型参数的随机种子会影响GAN的性能。如下所示,在测量GAN性能时,FID分数在50次单独训练中有所不同。但是范围相对较小,可能仅在以后的微调中才能完成。
批量标准化
DGCAN强烈建议在网络设计中添加BM。BM的使用也已成为许多深度网络模型中的通用做法。但是,会有例外。下图展示了BN对不同数据集的影响。y轴是FID得分,得分越低越好。根据WGAN-GP论文的建议,使用BN时应将其关闭。我们建议读者检查使用的成本函数和BN上相应的FID性能,并通过实验验证设置。
多个GAN
模式崩溃可能并不都是坏事。模式崩溃时,图像质量通常会提高。实际上,我们可能会为每种模式收集最佳模型,并使用它们来重建图像的不同模式。
鉴别器与生成器之间的平衡
鉴别器和生成器总是在拉锯战中互相削弱。模态崩溃和梯度消失通常被解释为鉴别器和发生器之间的不平衡。我们可以通过集中精力平衡生成器和鉴别器之间的损耗来改善GAN。不幸的是,该解决方案似乎难以捉摸。我们可以在鉴别器和生成器上的梯度下降迭代次数之间保持静态比率。即使这似乎很吸引人,但许多人怀疑它的好处。通常,我们保持一对一的比例。但是一些研究人员还测试了每个生成器更新的5个鉴别器迭代的比率。还提出了用动态力学平衡两个网络。但是直到最近几年,我们才对此有所关注。
另一方面,一些研究人员对平衡这些网络的可行性和可取性提出了挑战。无论如何,训练有素的鉴别器会向发生器提供质量反馈。而且,训练发电机总是赶上鉴别器并不容易。取而代之的是,当发电机运行不佳时,我们可能会将注意力转移到寻找一个没有接近零梯度的成本函数。
