自从 Ian Goodfellow 在 14 年发表了 论文 Generative Adversarial Nets 以来,生成式对抗网络 GAN 广受关注,加上学界大牛 Yann Lecun 在 Quora 答题时曾说,他最激动的深度学习进展是生成式对抗网络,使得 GAN 成为近年来在机器学习领域的新宠,可以说,研究机器学习的人,不懂 GAN,简直都不好意思出门。
下面我们来简单介绍一下生成式对抗网络,主要介绍三篇论文:1)Generative Adversarial Networks;2)Conditional Generative Adversarial Nets;3)Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks。
首先来看下第一篇论文,了解一下 GAN 的过程和原理:
GAN 启发自博弈论中的二人零和博弈(two-player game),GAN 模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。可以做如下类比:生成网络 G 好比假币制造团伙,专门制造假币,判别网络 D 好比警察,专门检测使用的货币是真币还是假币,G 的目标是想方设法生成和真币一样的货币,使得 D 判别不出来,D 的目标是想方设法检测出来 G 生成的假币。如图所示:
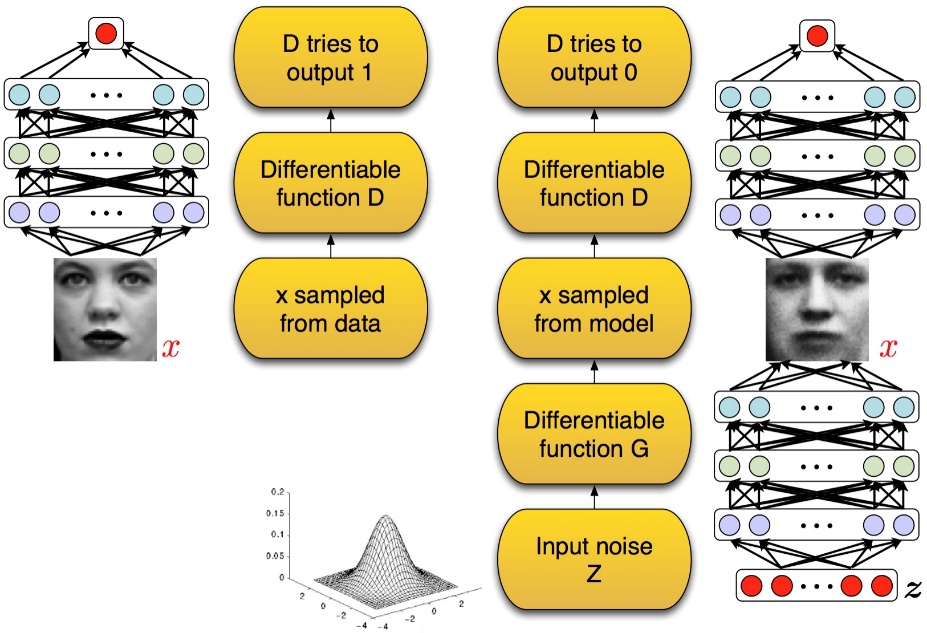
在训练的过程中固定一方,更新另一方的网络权重,交替迭代,在这个过程中,双方都极力优化自己的网络,从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡),此时生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。
上述过程可以表述为如下公式:
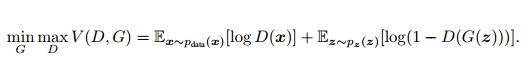
当固定生成网络 G 的时候,对于判别网络 D 的优化,可以这样理解:输入来自于真实数据,D 优化网络结构使自己输出 1,输入来自于生成数据,D 优化网络结构使自己输出 0;当固定判别网络 D 的时候,G 优化自己的网络使自己输出尽可能和真实数据一样的样本,并且使得生成的样本经过 D 的判别之后,D 输出高概率。
第一篇文章,在 MNIST 手写数据集上生成的结果如下图:

最右边的一列是真实样本的图像,前面五列是生成网络生成的样本图像,可以看到生成的样本还是很像真实样本的,只是和真实样本属于不同的类,类别是随机的。
第二篇文章想法很简单,就是给 GAN 加上条件,让生成的样本符合我们的预期,这个条件可以是类别标签(例如 MNIST 手写数据集的类别标签),也可以是其他的多模态信息(例如对图像的描述语言)等。用公式表示就是:
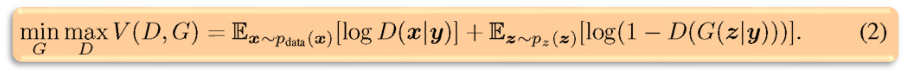
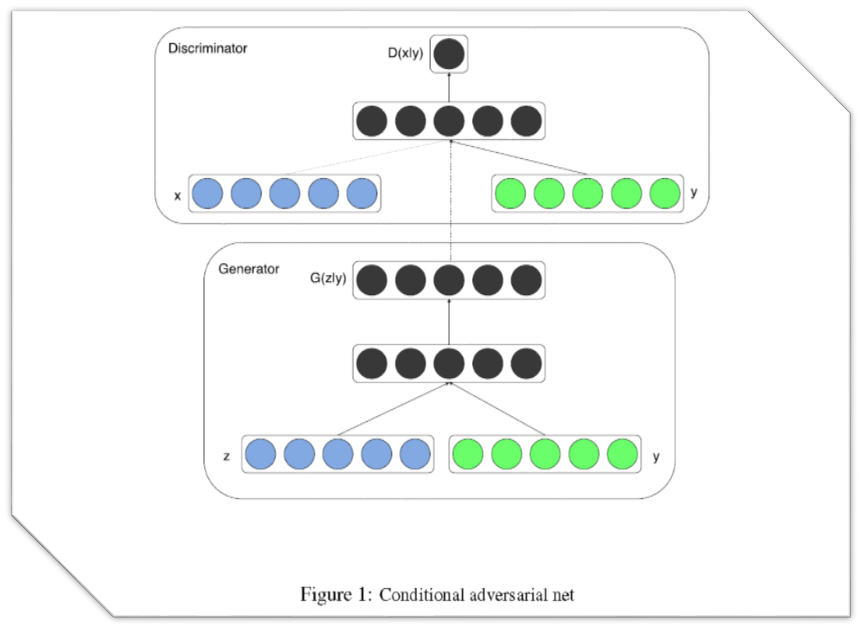
式子中的 y 是所加的条件,结构图如下:
 生成结果如下图:
生成结果如下图:

图中所加的条件 y 是类别标签。
第三篇文章,简称(DCGAN),在实际中是代码使用率最高的一篇文章,本系列文的代码也是这篇文章代码的初级版本,它优化了网络结构,加入了 conv,batch_norm 等层,使得网络更容易训练,网络结构如下:
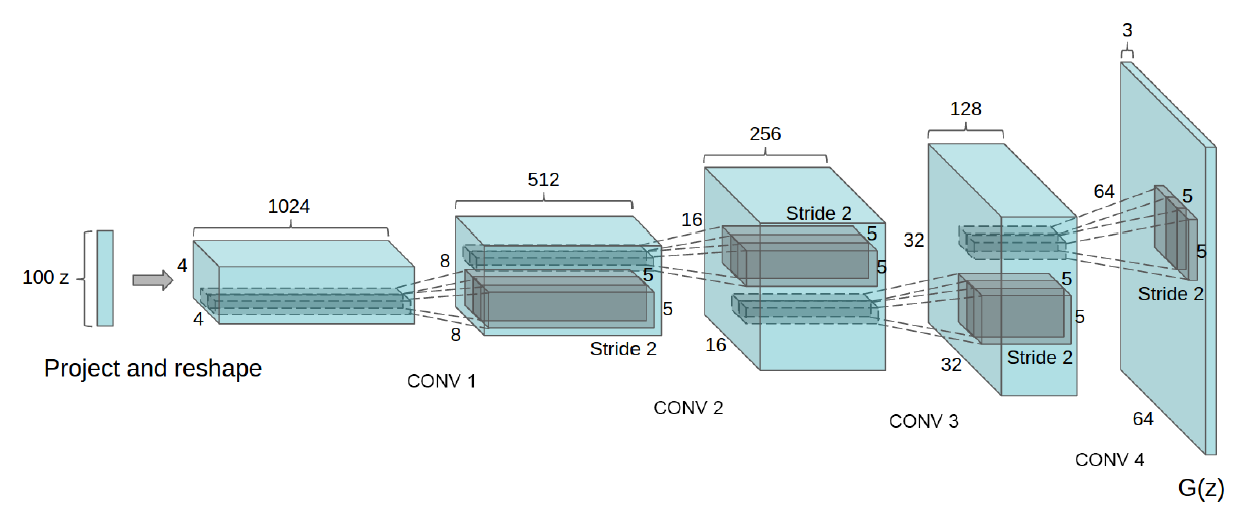
可以有加条件和不加条件两种网络,论文还做了好多试验,展示了这个网络在各种数据集上的结果。有兴趣同学可以去看论文,此文我们只从代码的角度理解去理解它。