python爬取新浪热搜排名并导入数据库
上一篇文章简单介绍了如何使用python爬取新浪微博的热搜排名:
爬虫实例:爬取新浪微博热搜排名
如果了解清楚原理的话是非常容易懂的,但是这样单纯的进行查询结果显示显然没有意义
学习了数据库之后,就尝试做了以下改进:
- 将热搜信息导入数据库
- 加了个日志函数,方便在服务器自动执行时保存运行数据
数据库我用的是mysql
目前只设计了一个名为hotsou-db的table来简单地存放内容:
CREATE TABLE hotsou-db(
hs_name VARCHAR(100),
hs_rank INT(3),
hs_number INT(20),
hs_time TIMESTAMP
);
-- 四个属性都是主键感觉有点不太合理。
ALTER TABLE `hotsou-db` ADD PRIMARY KEY(hs_name, hs_rank, hs_number, hs_time);
在上篇文章的基础上,添加如下内容:
import pymysql
import time
def CommitDB(ranklist, num, tt):
DB_name = "`hotsou-db`"
try:
# 连接mysql
conn = pymysql.connect(
host="",
user="", password="",
port=,
database="",
charset="utf8")
except:
Logs(tt, 1, 'DB Connection Failed');
try:
cursor = conn.cursor()
for i in range(num):
if i is 0:
continue
else:
rank = int(ranklist[i][0])
name =ranklist[i][1]
number = int(ranklist[i][2])
sql = "INSERT INTO {0} VALUES('{1}', {2}, {3}, {4})".format(DB_name, name, rank, number, eval(tt))
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
Logs(tt, 0, 'Commit Done');
except:
Logs(tt, 1, 'Commit Failed');
def Logs(tt, number, text):
f = open("./weibo.log", "a")
# 用于生成日志 - 0是正确运行日志, 1是错误日志
if number is 0:
f.write('[' + tt + '] -- ' + text + '\n')
else:
f.write('[' + tt + '] -- ' + text + '\n')
f.close()
在main中做如下更改即可:
tt = time.strftime("%Y%m%d%H%M%S", time.localtime())
soup = HTMLTextconvert(text)
HTMLSearch(soup, rank)
CommitDB(rank, 51, tt)
# 每隔五分钟记录一次
time.sleep(600)
可以看到主要是用到了pymysql这个库来实现与数据库的交互操作
最终效果:
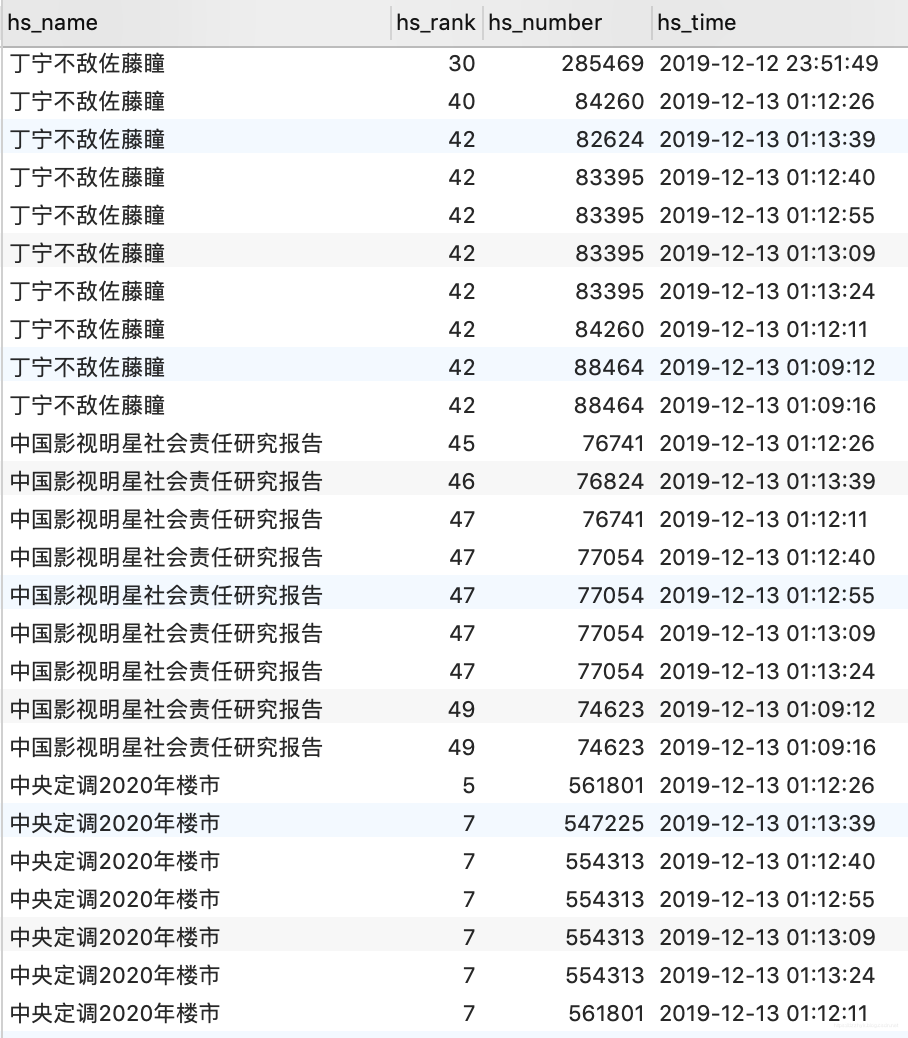
导入数据库之后就可以做些有趣的事情了
