《猫眼电影实时票房》这个网页是通过动态加载的数据,大约4秒钟就要请求一次服务器,上面的数据每次请求都会产生变化,如果直接用requests请求它的html源代码,并获取不了它的数据。
网页地址: https://piaofang.maoyan.com/dashboard?movieId=1211270
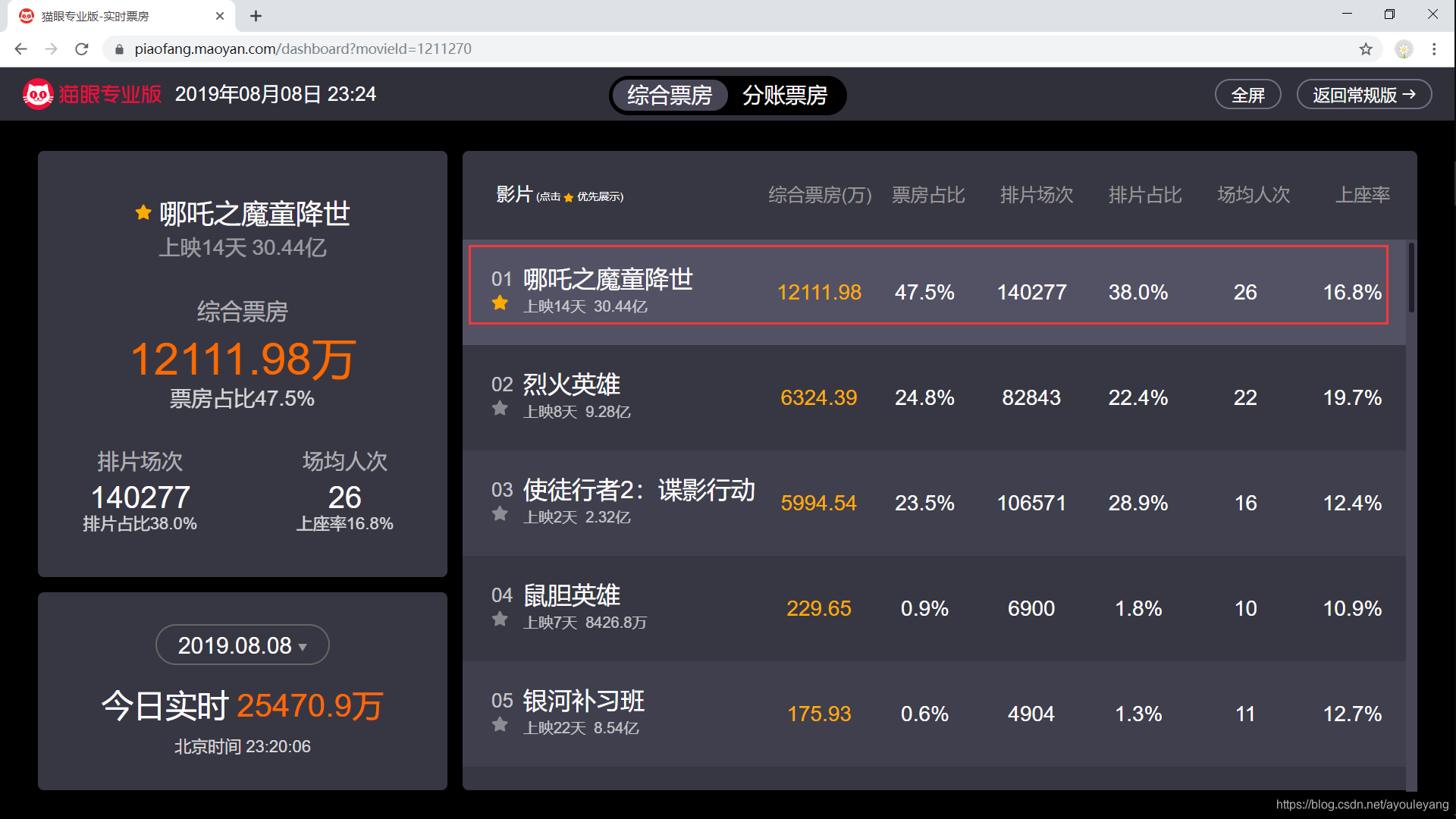
需要爬取的内容有:
猫眼排名,电影名称,综合票房,票房占比,排片场次,排片占比,场均人次,上座率,上映天数
直接通过这个url请求网页:
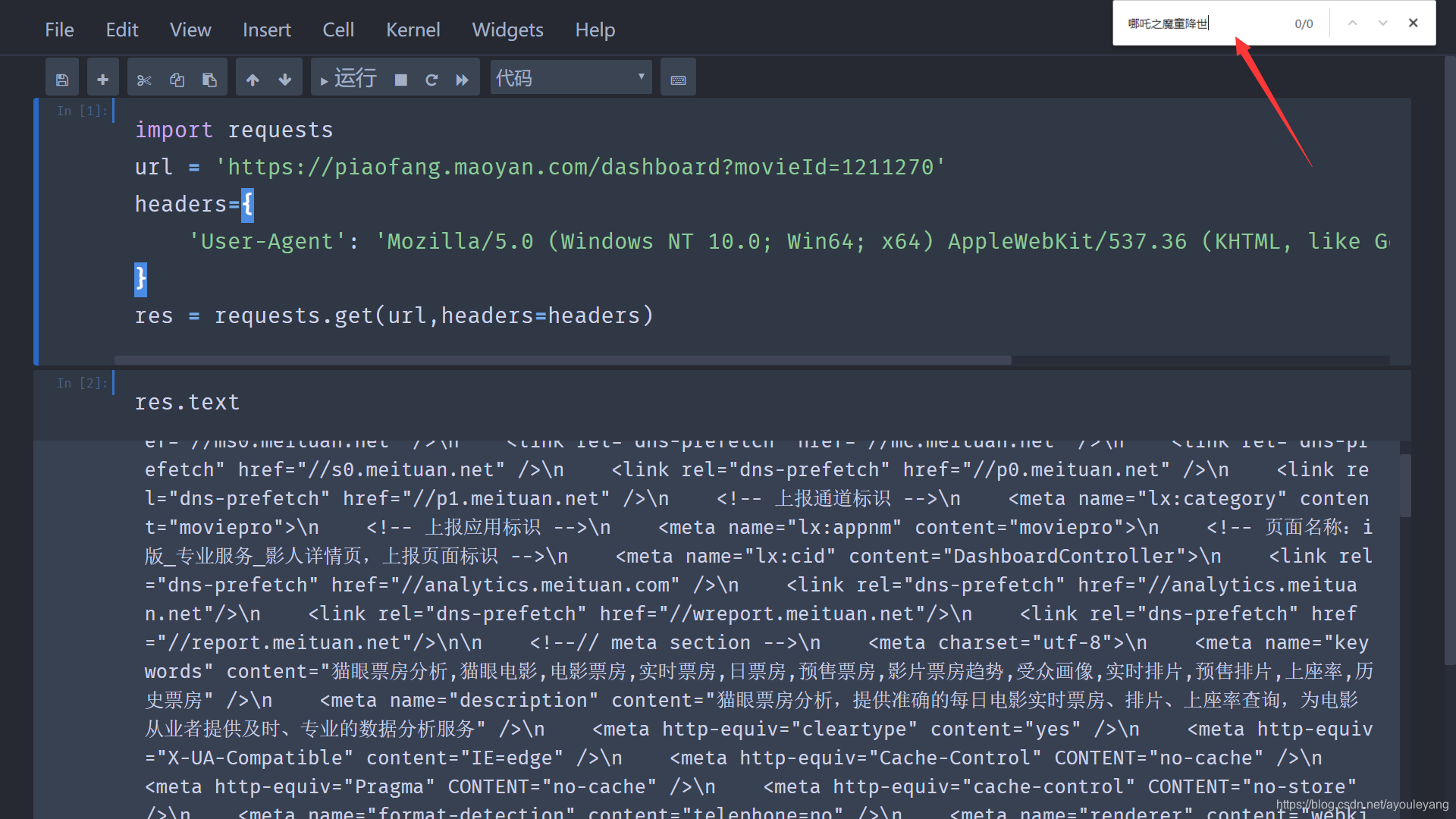
结果: 在输出的结果中并没有找到需要得数据,所以这个方法并行不通
怎么获取动态加载的数据?
1、在网页中找到传输数据的URL
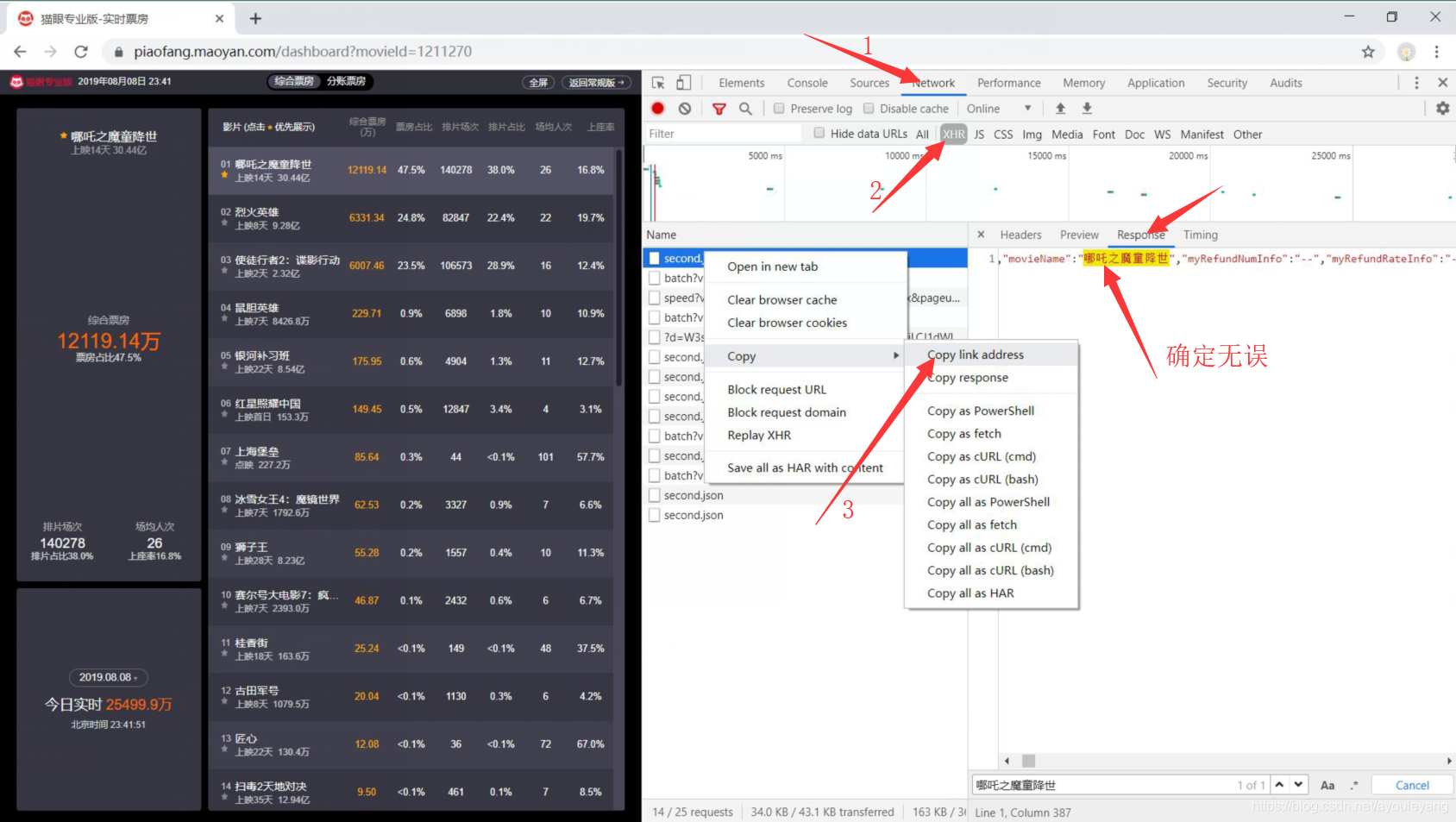
2、请求数据
import requests
import pprint
url = 'https://box.maoyan.com/promovie/api/box/second.json' #刚才复制的link address
res = requests.get(url)
- pprint 包含一个“美观打印机”,用于生成数据结构的一个美观视图。格式化工具会生成数据结构的一些表示,不仅可以由解释器正确地解析,而且便于人类阅读。输出尽可能放在一行上,分解为多行时则需要缩进。
pprint.pprint(res.json())
美化后输出的结果:
{'data': {'crystal': {'maoyanViewInfo': '378.5',
'status': 1,
'viewInfo': '697.9',
'viewUnitInfo': '万张'},
'list': [{'avgSeatView': '16.3%',
'avgShowView': '25',
'avgViewBox': '34.4',
'boxInfo': '11794.28',
'boxRate': '48.0%',
'movieId': 1211270,
'movieName': '哪吒之魔童降世',
'myRefundNumInfo': '--',
'myRefundRateInfo': '--',
'onlineBoxRate': '--',
'refundViewInfo': '--',
'refundViewRate': '--',
'releaseInfo': '上映14天',
'releaseInfoColor': '#666666 1.00',
'seatRate': '44.4%',
'showInfo': '140407',
'showRate': '38.0%',
'splitAvgViewBox': '30.9',
'splitBoxInfo': '10603.21',
'splitBoxRate': '47.9%',
'splitSumBoxInfo': '28.02亿',
'sumBoxInfo': '30.41亿',
'viewInfo': '342.2',
'viewInfoV2': '342.2万'},
<---省略部分内容 --->
现在就可以得到一个美观的字典型数据进行参照提取相应的内容,字典的功能之一就是方便查找数据。
3、查找所有需要的数据
rank = 0
for mv in res.json()['data']['list']:#注意字典的层级关系
rank = rank + 1 #网页中的排名并没有在.json这个url中,就直接循环赋值
name = mv['movieName']#查找数据
zhpf = mv['boxInfo']
pfzb = mv['splitBoxRate']
ppcc = mv['showInfo']
ppzb = mv['showRate']
cjrc = mv['avgShowView']
szl = mv['avgSeatView']
syts = mv['releaseInfo']
print (rank,name,zhpf,pfzb,ppcc,ppzb,cjrc,szl,syts)
运行结果:
1 上海堡垒 3651.98 54.3% 132944 33.7% 8 5.8% 上映首日
2 哪吒之魔童降世 1295.51 19.2% 105251 26.7% 4 2.4% 上映15天
3 使徒行者2:谍影行动 914.45 13.5% 75694 19.2% 4 2.9% 上映3天
4 烈火英雄 509.42 7.5% 53329 13.5% 3 2.5% 上映9天
5 红星照耀中国 129.95 1.8% 9332 2.3% 4 3.4% 上映2天
6 童童的风铃密室 46.97 0.6% 3471 0.8% 5 5.0% 上映首日
7 桂香街 28.20 0.4% 120 <0.1% 60 50.6% 上映19天
8 萤火奇兵2:小虫不好惹 28.10 0.4% 2867 0.7% 4 3.1% 展映
9 古田军号 16.16 0.2% 1337 0.3% 4 3.0% 上映9天
10 鼠胆英雄 9.90 0.1% 1699 0.4% 2 1.3% 上映8天
11 银河补习班 9.87 0.1% 1444 0.3% 2 2.2% 上映23天
12 冰雪女王4:魔镜世界 8.43 0.1% 1295 0.3% 2 2.0% 上映8天
13 匠心 7.23 0.1% 34 <0.1% 66 56.2% 上映23天
14 极度危机 6.60 <0.1% 393 <0.1% 5 5.2% 上映首日
15 狮子王 6.35 <0.1% 483 0.1% 4 3.9% 上映29天
16 最美的地方遇见你 5.56 <0.1% 236 <0.1% 8 7.3% 上映8天
17 哈姆雷特 4.26 <0.1% 2 <0.1% 146 73.0% 2016-01
18 周恩来回延安 4.10 <0.1% 36 <0.1% 36 37.0% 上映87天
19 赛尔号大电影7:疯狂机器城 3.93 <0.1% 665 0.1% 2 1.8% 上映8天
20 神奇马戏团之动物饼干 2.48 <0.1% 538 0.1% 3 2.0% 2018-07
21 李尔王 1.75 <0.1% 1 <0.1% 120 82.7% 展映
22 丛林历险记 1.74 <0.1% 525 0.1% 2 1.1% 上映2天
23 游戏人生 零 1.62 <0.1% 23 <0.1% 20 33.3% 上映22天
24 特别追踪 1.59 <0.1% 4 <0.1% 123 77.9% 2018-09
25 悲惨世界:25周年纪念演唱会 1.53 <0.1% 1 <0.1% 105 76.0% 展映
26 跳舞吧!大象 1.35 <0.1% 39 <0.1% 8 8.6% 上映15天
27 白蛇:缘起 1.00 <0.1% 521 0.1% 2 1.2% 2019-01
注意: 在网页上只能显示27条数据,我第一次运行的时候,《哪吒之魔童降世》排名是第一的,现在重新运行python加载后,排名已经变了,这是正常的
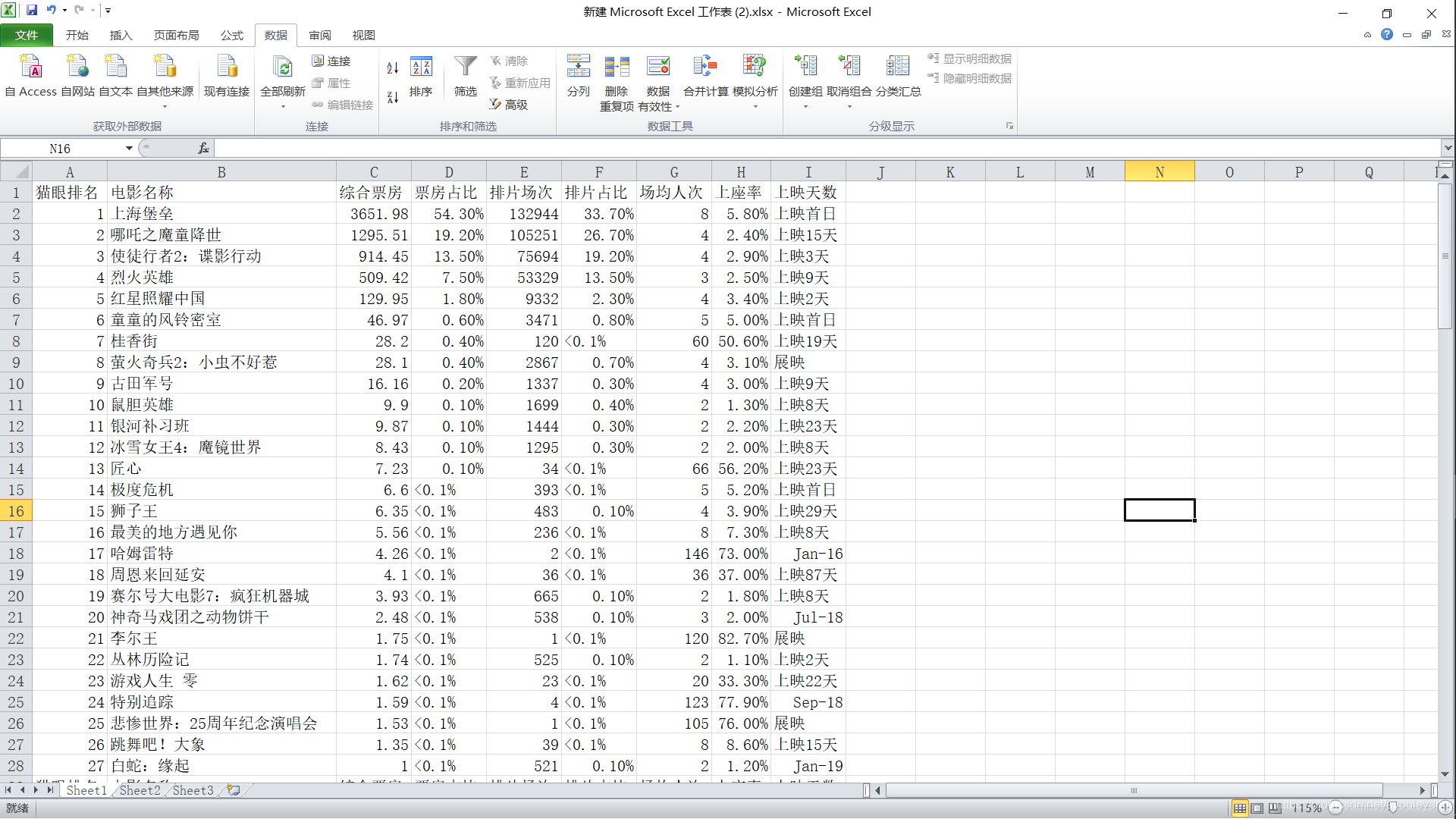
将数据保存到csv及源码如下:
#!/usr/bin/env python3
#-*-coding:utf-8-*-
import requests,csv
import pprint
url = 'https://box.maoyan.com/promovie/api/box/second.json'
res = requests.get(url)
pprint.pprint(res.json())
#创建CSV文件,并写入表头信息
fp = open('G:\maoyan_data.csv','a',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('猫眼排名','电影名称','综合票房','票房占比','排片场次','排片占比','场均人次','上座率','上映天数'))
rank = 0
for mv in res.json()['data']['list']:#注意字典的层级关系
rank = rank + 1 #网页中的排名并没有在.json这个url中,就直接循环赋值
name = mv['movieName']#查找数据
zhpf = mv['boxInfo']
pfzb = mv['splitBoxRate']
ppcc = mv['showInfo']
ppzb = mv['showRate']
cjrc = mv['avgShowView']
szl = mv['avgSeatView']
syts = mv['releaseInfo']
print (rank,name,zhpf,pfzb,ppcc,ppzb,cjrc,szl,syts)
# 写入csv数据
writer.writerow((rank,name,zhpf,pfzb,ppcc,ppzb,cjrc,szl,syts))
csv结果如下:
如果出现csv乱码,请参照python xpath爬取豆瓣图书Top 250存入csv文件并解决csv乱码问题
