一、hadoop本地运行模式介绍
默认的模式,无需运行任何守护进程,所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
使用本地文件系统,而不是分布式文件系统。
Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
用于对MapReduce程序的逻辑进行调试,确保程序的正确。
所谓默认模式,及安装完jdk及hadoop,配置好相应的环境,及本地模式配置完成。
二、hadoop本地运行模式环境搭建
2.1 创建虚拟机
在本文章中,hadoop的搭建是基于 VMware12 虚拟的 CentOS 6.8 系统,下面来讲解一下如何使用 VMware12 来虚拟一个 Centos 6.8 系统。
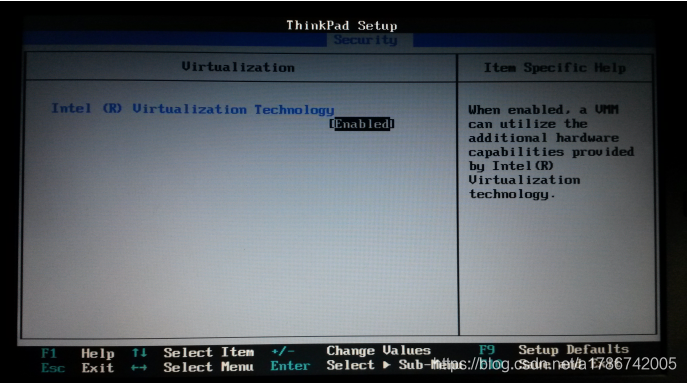
1、检查BIOS虚拟化支持
每台电脑进入BIOS的方式都不同,可以查看自己电脑型号,自行百度。
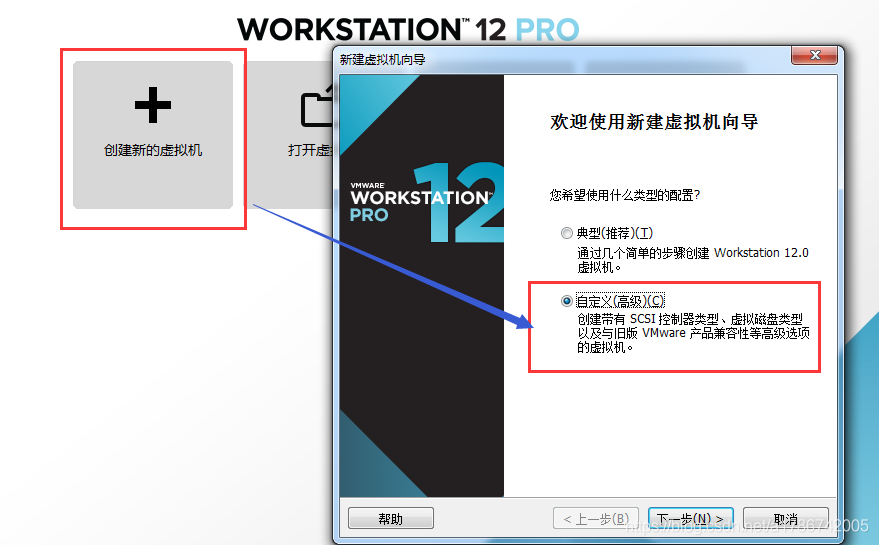
2、新建虚拟机
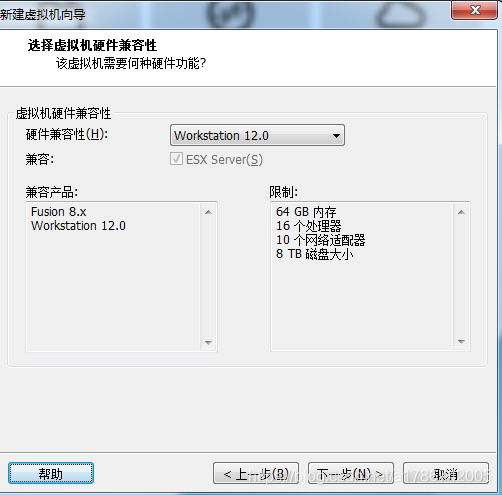
3、新建虚拟机向导
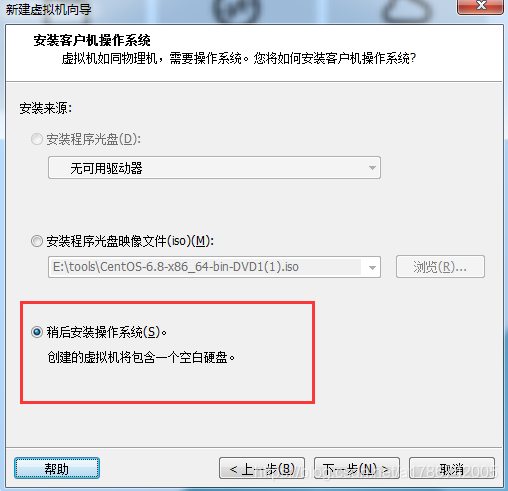
4、创建虚拟空白光盘
5、安装Linux系统对应的CentOS 64位

6、虚拟机命名和定位磁盘位置
7、处理器配置
虚拟机处理器数量可以根据自己的机器配置来定,点击电脑的属性即可查看。
8、设置内存
这里可以根据自己电脑内存的大小进行设置,我选择2G。
9、网络设置
这里我选择了NAT模式,关于其他网络连接方式大家可以自行百度查看其区别。
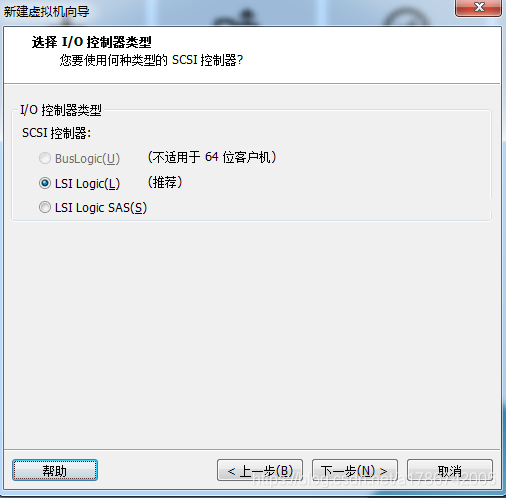
10、选择IO控制器类型
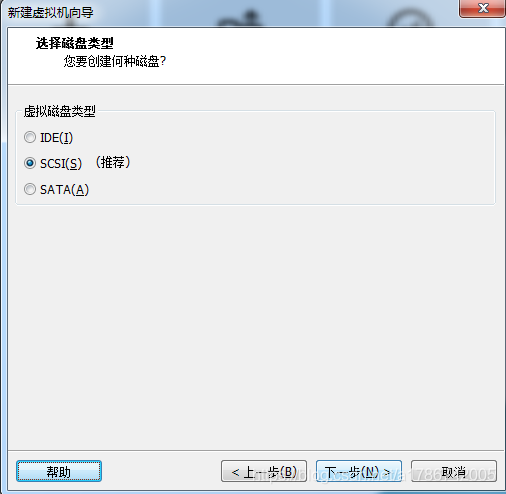
11、选择磁盘类型
IDE: 老的磁盘类型
SCSI: 服务器上推荐使用的磁盘类型,串口。
SATA: 也是串口,也是新的磁盘类型。
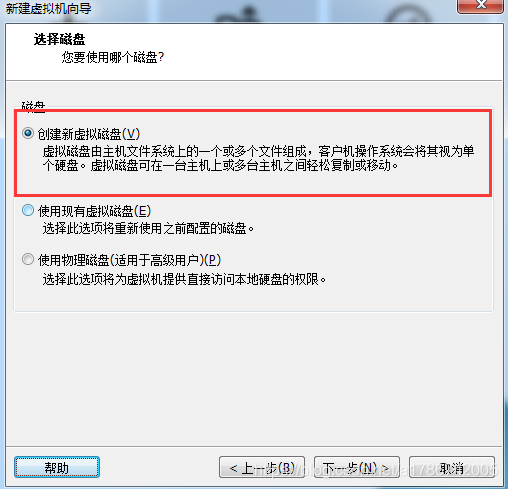
12、新建虚拟磁盘
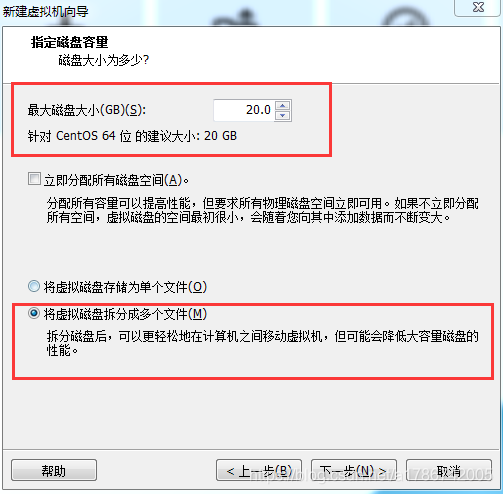
13、设置磁盘容量
14、指定磁盘文件存储位置
15、新建虚拟机向导完成
16、VM设置
17、加载ISO
 18、启动虚拟机安装配置CentOS系统
18、启动虚拟机安装配置CentOS系统
 19、进入系统初始化安装界面
19、进入系统初始化安装界面
回车选择第一个开始安装配置。此外,在Ctrl+Alt可以实现Windows主机和VM之间窗口的切换。
 20、是否对CD媒体进行测试,直接跳过Skip
20、是否对CD媒体进行测试,直接跳过Skip
21、CentOS欢迎页面,直接点击Next
 22、选择简体中文进行安装
22、选择简体中文进行安装
 23、选择语言键盘
23、选择语言键盘
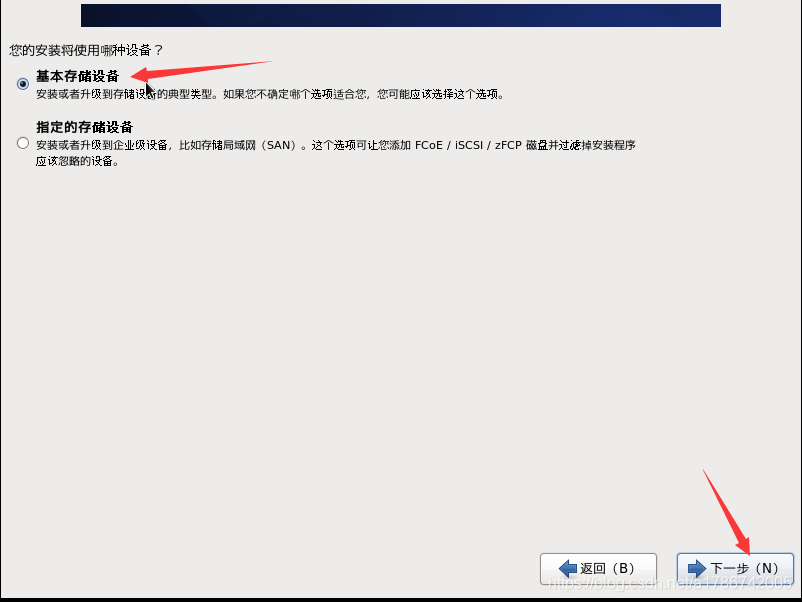
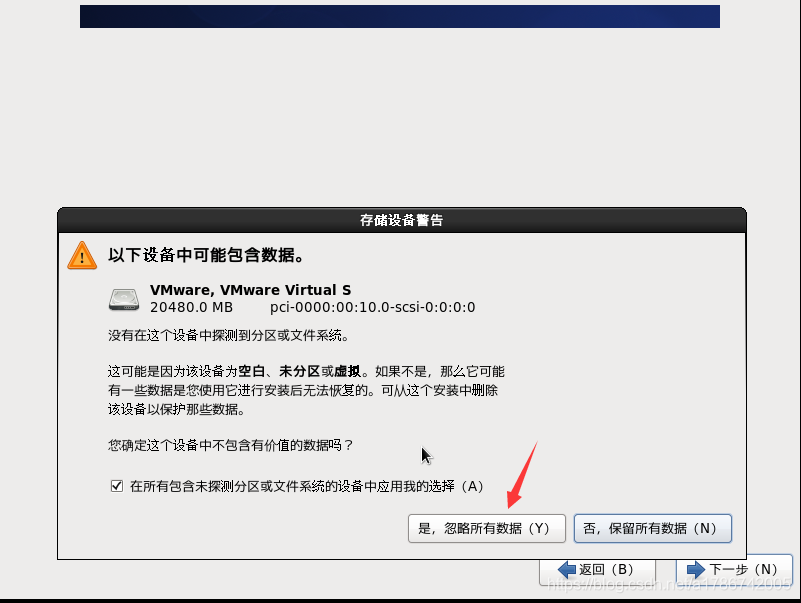
 24、选择存储设备
24、选择存储设备
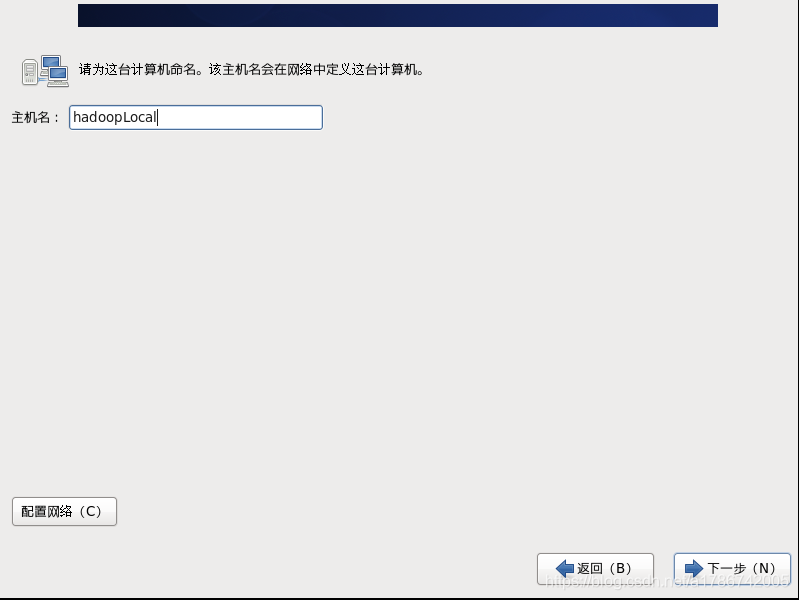
 25、给计算机起名
25、给计算机起名
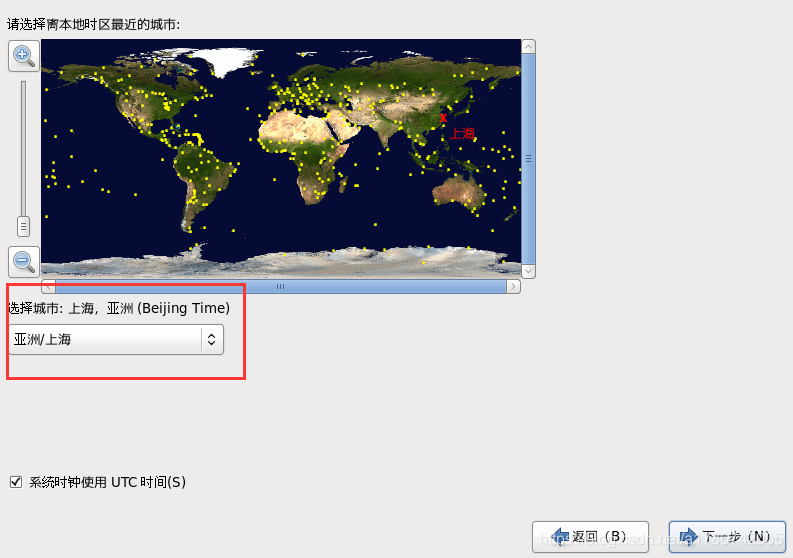
 26、选择时区
26、选择时区
 27、设置root密码
27、设置root密码
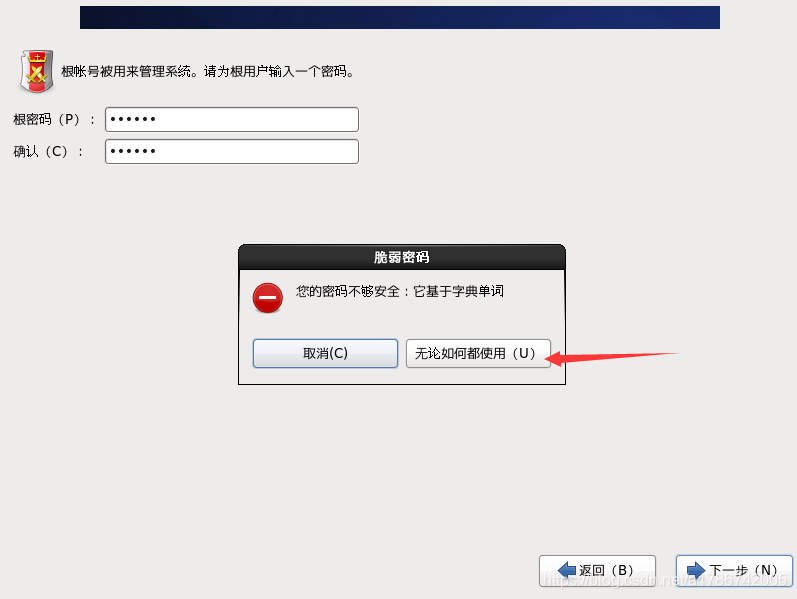 28、硬盘分区
28、硬盘分区
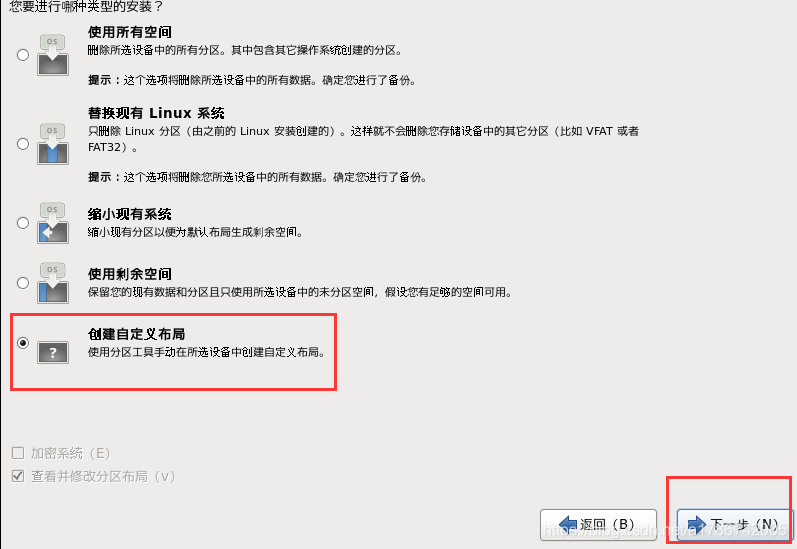 29、分区创建
29、分区创建
这里创建了/、/boot以及swap交换分区,也可以创建其他挂载点,请自行百度。

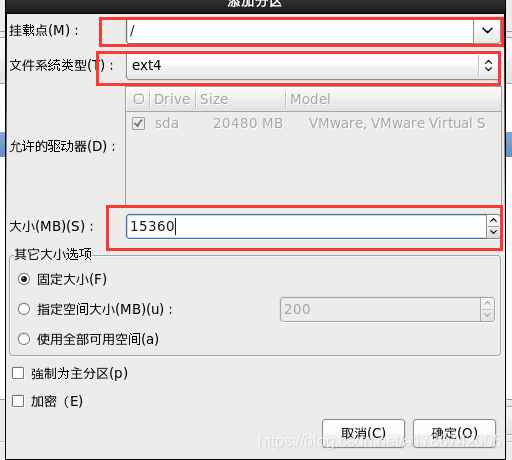
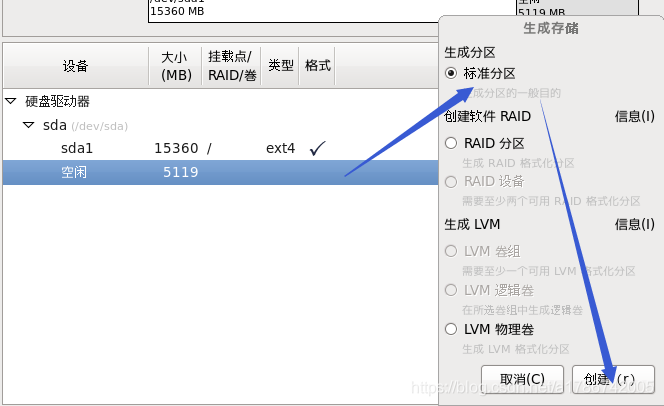
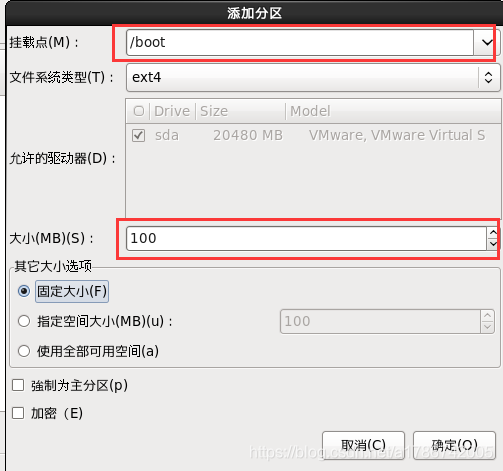
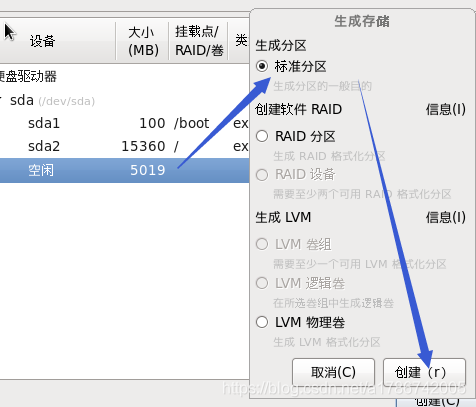
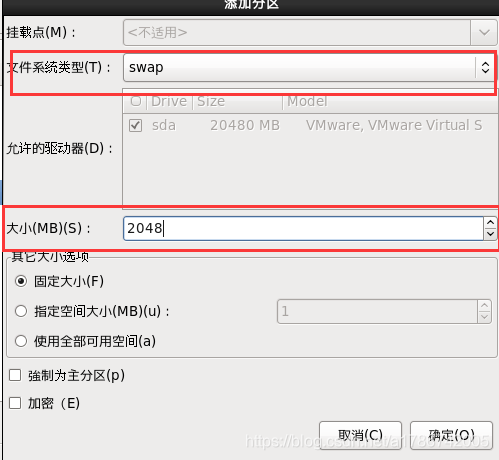
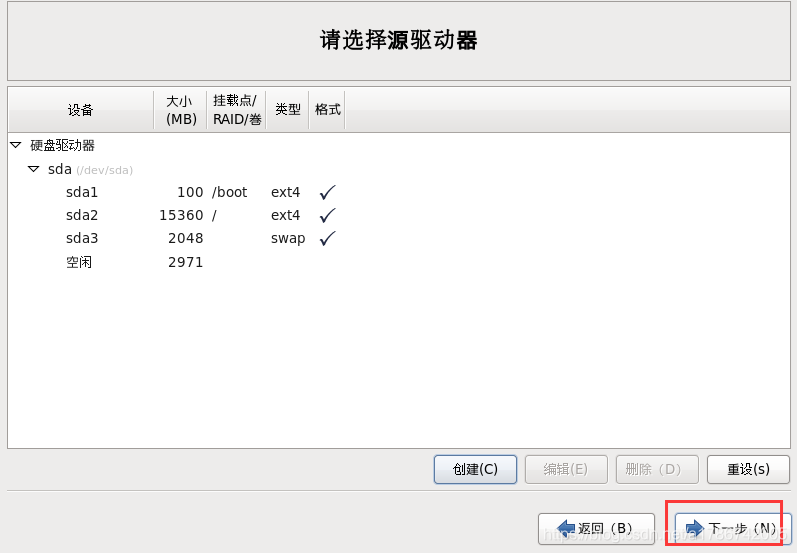 30、程序引导,直接下一步
30、程序引导,直接下一步
 31、定制系统软件
31、定制系统软件
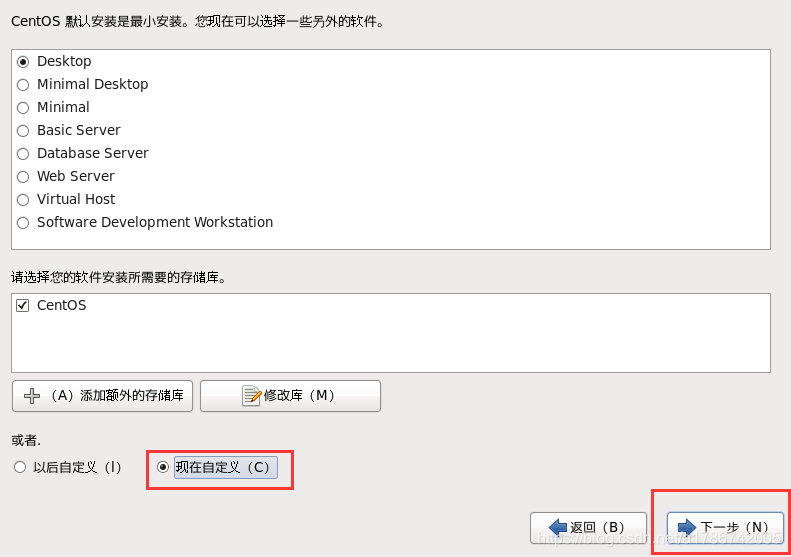 32、Web环境
32、Web环境
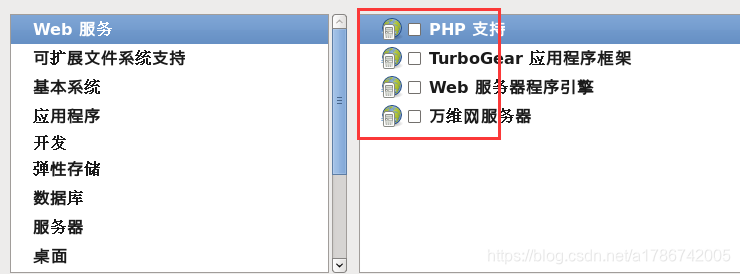 33、可扩展文件系统支持
33、可扩展文件系统支持
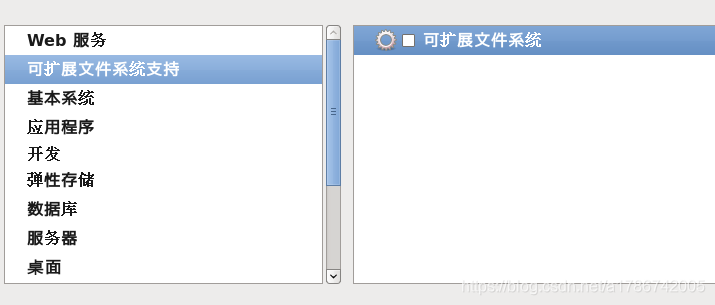 34、基本系统(不要去勾选java平台,因为后面我们自己需要安装)
34、基本系统(不要去勾选java平台,因为后面我们自己需要安装)
 35、应用程序
35、应用程序
 36、开发、弹性存储、数据库、服务器
36、开发、弹性存储、数据库、服务器
可以都不勾,有需要,以后使用中有需要再手动安装
37、桌面
除了KDE,其他都选就可以了。
 38、语言支持
38、语言支持
 39、系统管理、虚拟化、负载平衡器、高可用性可以都不选
39、系统管理、虚拟化、负载平衡器、高可用性可以都不选
40、完成配置,开始安装CentOS
 41、安装完成,重新引导
41、安装完成,重新引导
 42、欢迎引导页面
42、欢迎引导页面
 43、许可证
43、许可证
 44、创建用户,可以先不创建,用root账户登录就行
44、创建用户,可以先不创建,用root账户登录就行

45、时间和日期
46、去掉Kdump

 47、重启后用root登录
47、重启后用root登录
48、配置可以上网
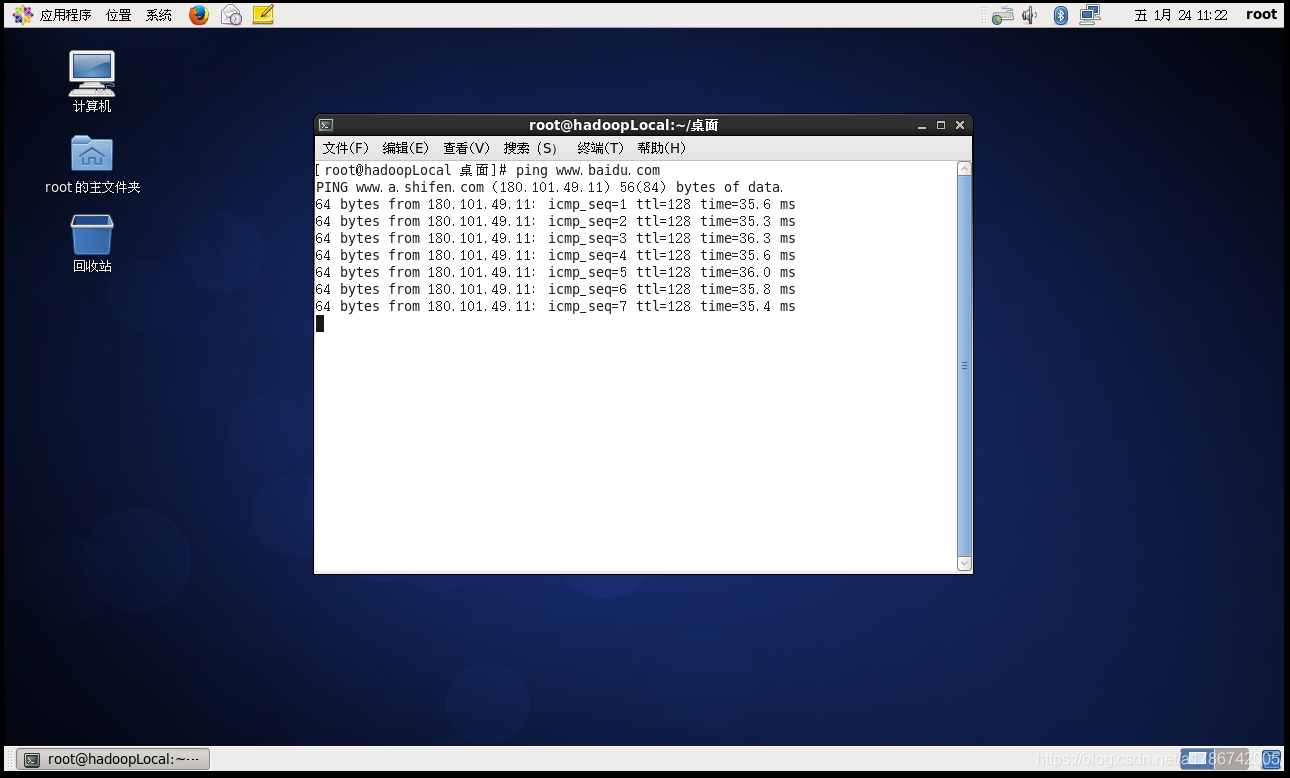
 49、ping一下百度,查看网络情况
49、ping一下百度,查看网络情况
2.2 修改克隆虚拟机的静态IP
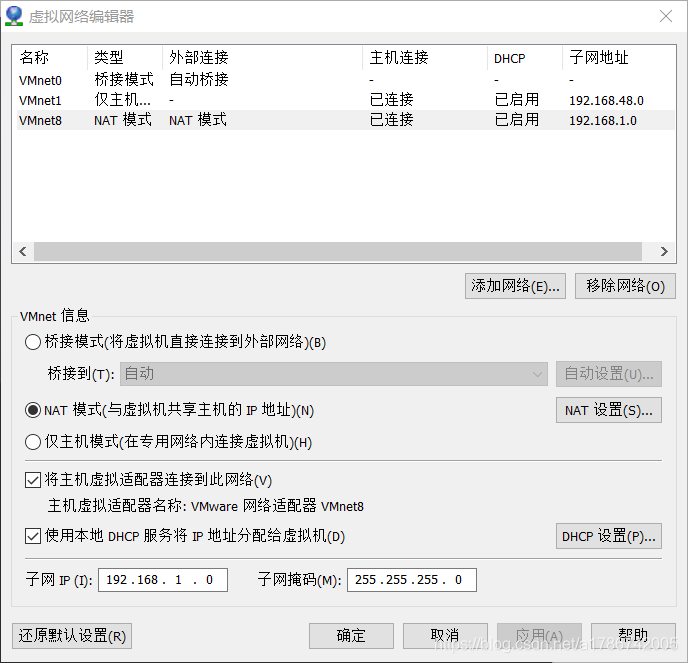
1、查看虚拟网络连接器
2、修改ip地址
这里可以自行修改,但必须为内网地址
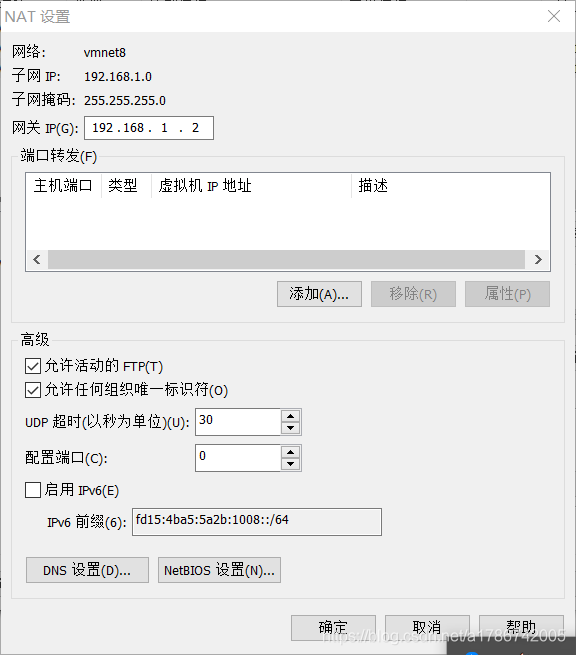
 3、查看网关
3、查看网关
4、查看windows环境的中VMnet8网络配置

5、将测试机ip进行修改
(1) 用vim修改配置
在终端输入命令:
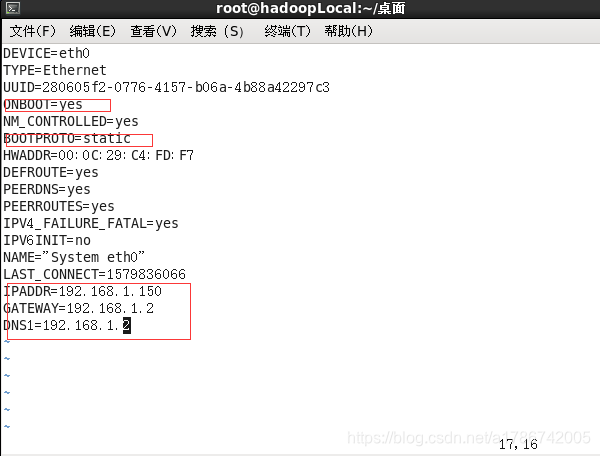
原配置为:
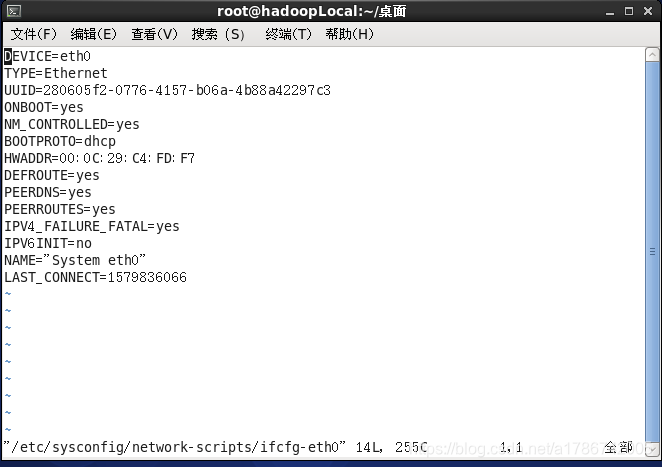 修改后的配置为:
修改后的配置为:
以下标红的项必须修改,有值的按照下面的值修改,没有该项的要增加。
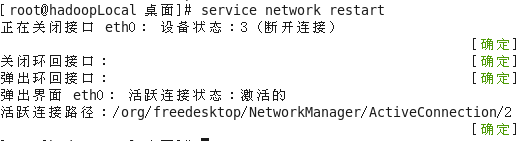
 (2) 在终端中执行以下命令,重启网络服务
(2) 在终端中执行以下命令,重启网络服务
 (3) 如果报错,reboot,重启虚拟机
(3) 如果报错,reboot,重启虚拟机
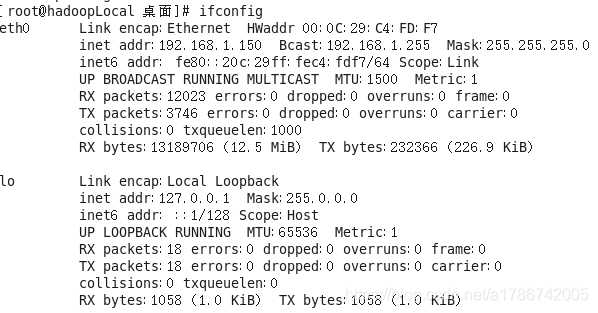
(4) 使用ifconfig查看网络
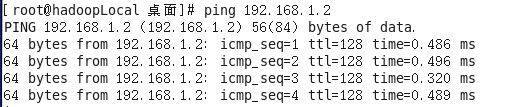
(5) 使用ping命令测试网络
A、windows主机ping虚拟机
 B、虚拟机ping网关
B、虚拟机ping网关
C、虚拟机ping外网
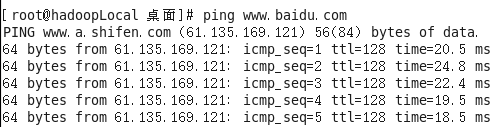
2.3 修改主机名
1、查看当前服务器主机名称

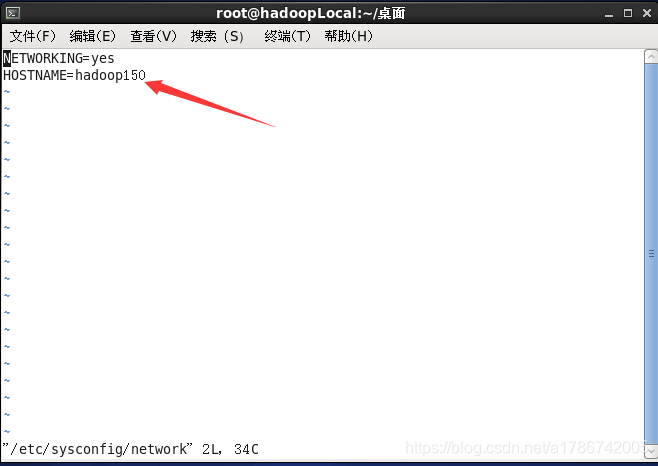
2、修改服务器主机名称
注意:主机名称不要有"_"下划线

 3、重新启动虚拟机
3、重新启动虚拟机
在终端中输入命令:reboot
 4、查看主机名称
4、查看主机名称

2.4 配置主机名与ip映射
1、修改配置文件

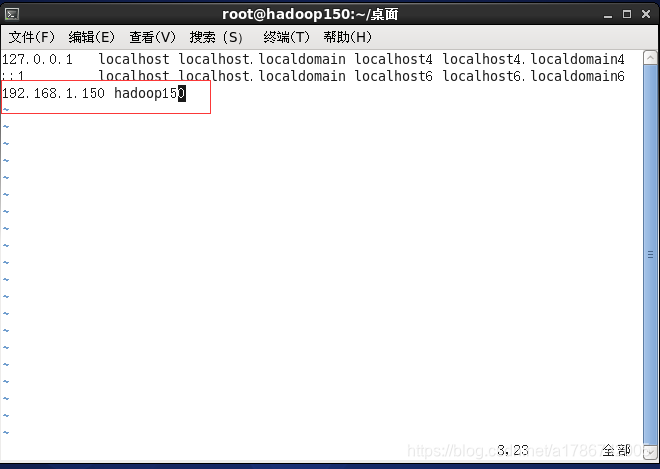 2、ping一下主机名看看能否ping通
2、ping一下主机名看看能否ping通

2.5 关闭防火墙
1、临时关闭防火墙
(1) 查看防火墙状态
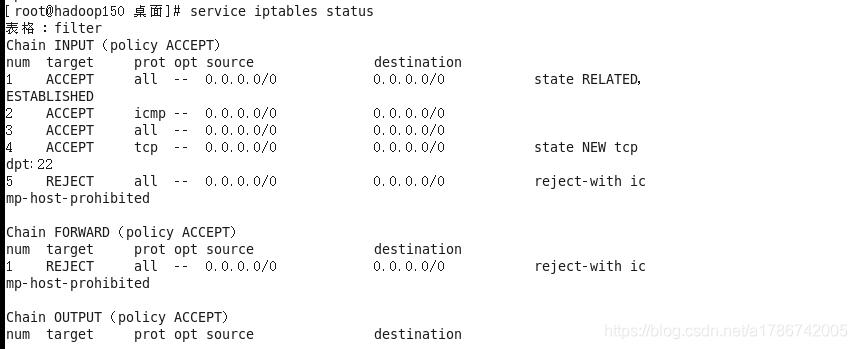
(2) 临时关闭防火墙

2、开机启动时关闭防火墙
(1) 查看防火墙开机启动状态

(2) 设置开机时关闭防火墙

2.6 创建test用户
添加用户并设置密码

2.7 使test用户拥有sudo权限
修改配置文件,添加用户
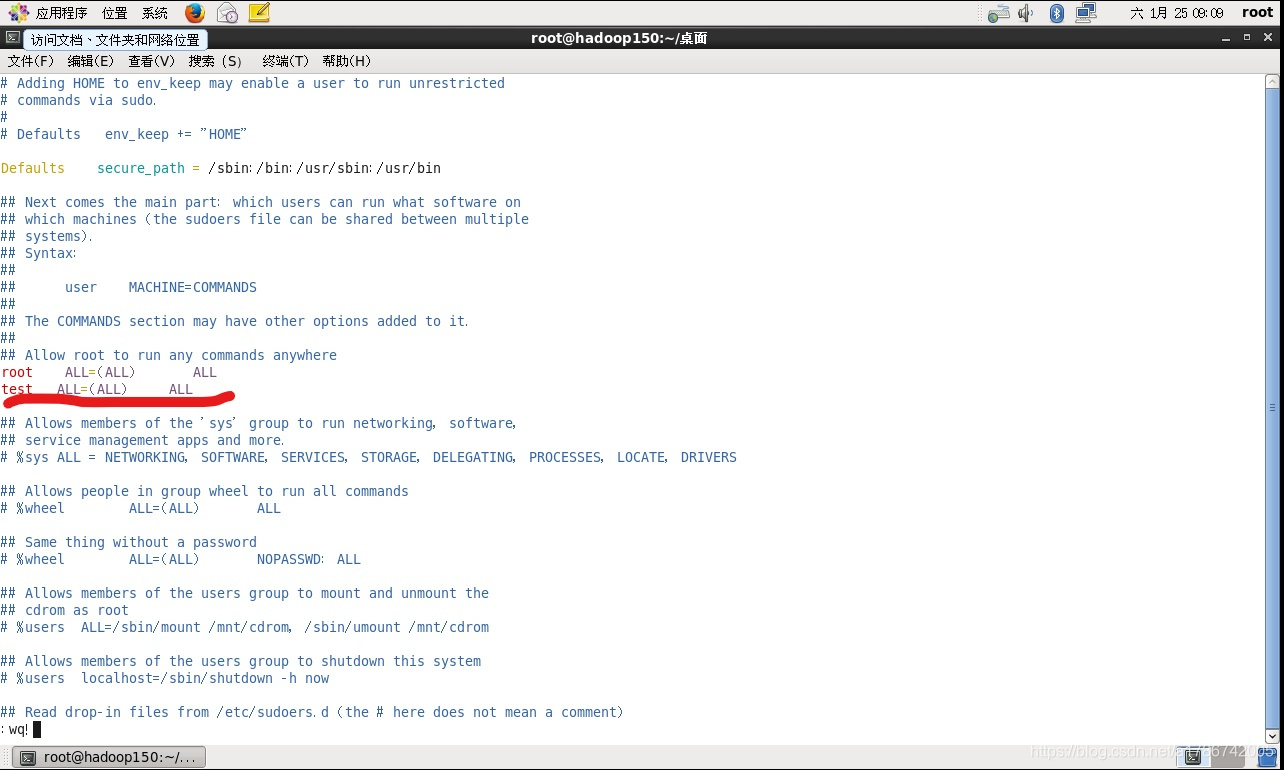
2.8 在/opt目录下创建文件夹
1、在/opt目录下创建module、software文件夹
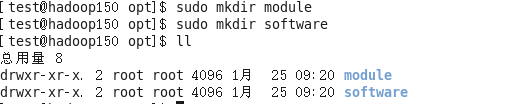
2、修改module、software文件夹的所有者

2.9 安装JDK
1、卸载现有JDK
(1) 查询是否安装Java软件
[test@hadoop150 opt]$ rpm -qa | grep java
(2) 如果安装的版本低于1.7,卸载该JDK
[test@hadoop150 opt]$ sudo rpm -e 软件包
(3) 查看JDK安装路径
[test@hadoop150 ~]$ which java
2、用filezilla软件将安装包上传到/opt目录下的software文件夹
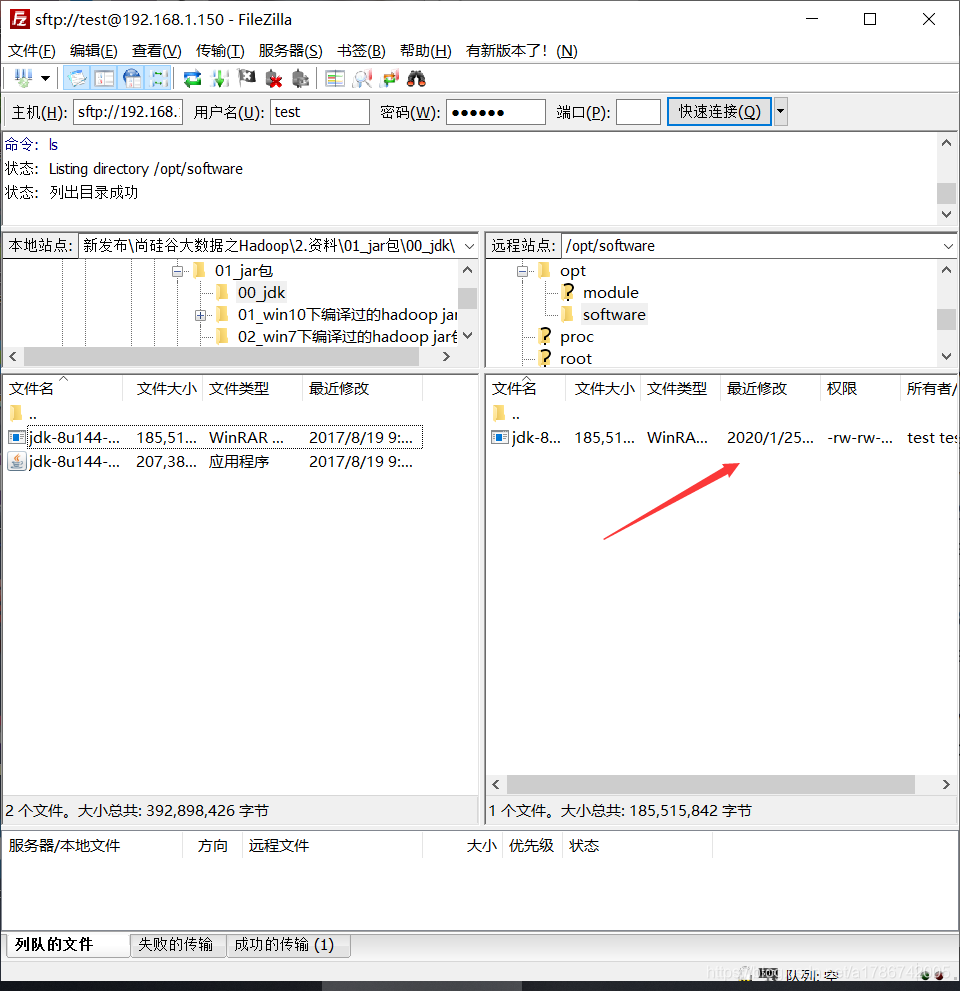 3、在Linux系统下的opt目录中查看软件包是否导入成功
3、在Linux系统下的opt目录中查看软件包是否导入成功

4、解压JDK到/opt/module目录下
[test@hadoop150 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
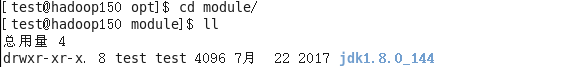
5、配置JDK环境变量
(1) 先获取JDK路径
[test@hadoop150 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
(2) 打开/etc/profile文件
[test@hadoop150 software]$ sudo vi /etc/profile
在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(3) 保存后退出
:wq
(4) 让修改后的文件生效
[test@hadoop150 jdk1.8.0_144]$ source /etc/profile
6、测试JDK是否安装成功
[test@hadoop150 jdk1.8.0_144]# java -version
java version “1.8.0_144”
2.10 安装Hadoop
1、用filezilla软件将安装包上传到/opt目录下的software文件夹
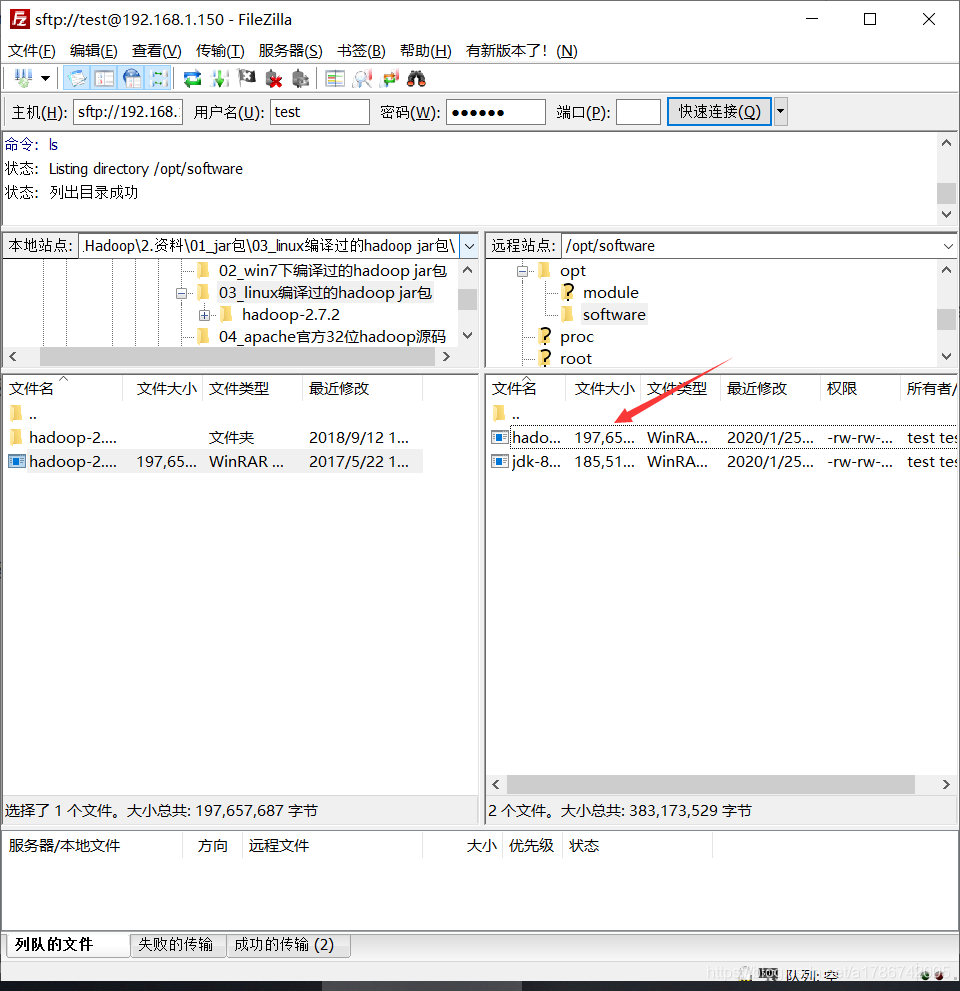 2、解压安装文件到/opt/module下面
2、解压安装文件到/opt/module下面
[test@hadoop150 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
3、查看是否解压成功

4、将Hadoop添加到环境变量
(1) 获取Hadoop安装路径
[test@hadoop150 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
(2) 打开/etc/profile文件
[test@hadoop150 hadoop-2.7.2]$ sudo vi /etc/profile
在profile文件末尾添加JDK路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3) 保存后退出
:wq
(4) 让修改后的文件生效
[test@ hadoop150 hadoop-2.7.2]$ source /etc/profile
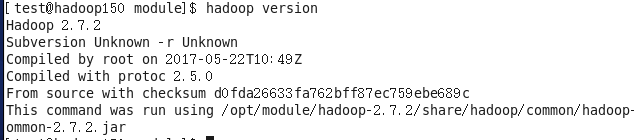
5、测试是否安装成功
2.11 本地运行模式测试
1、测试案例介绍
以官方的WordCount程序对Hadoop本地运行模式进行测试
2、创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[test@hadoop150 hadoop-2.7.2]$ mkdir wcinput
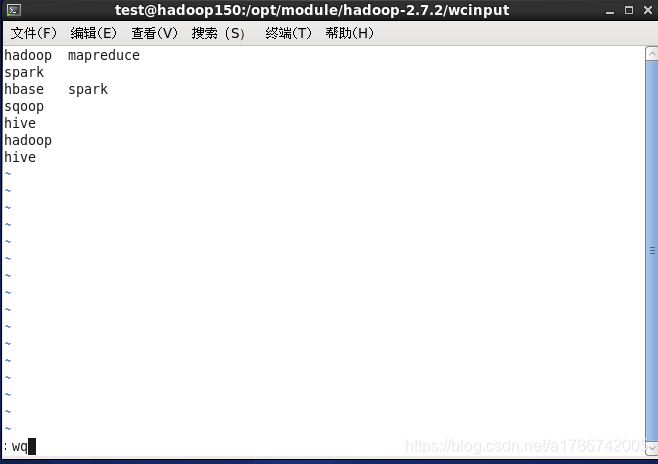
3、编辑wc.input文件
 4、回到Hadoop目录/opt/module/hadoop-2.7.2
4、回到Hadoop目录/opt/module/hadoop-2.7.2
5、执行程序
[test@hadoop150 hadoop-2.7.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
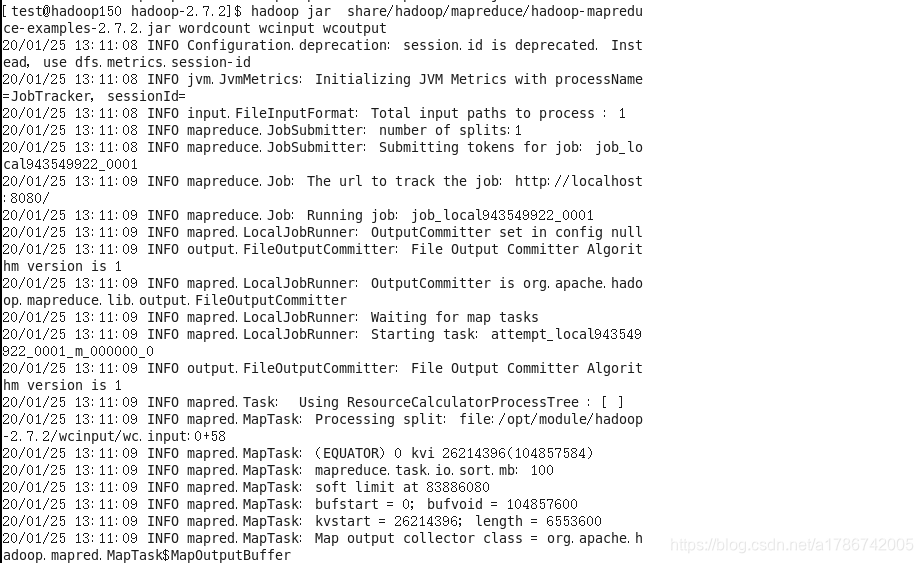
6、查看结果

三、软件说明
VMware:12
子系统:centOS 6.8 (64位)
hadoop版本:2.7.2 (64位,已编译好)
jdk:1.8 (64 位)
FileZilla:3.7.1.1
用到的软件地址都放在百度网盘:
https://pan.baidu.com/s/1dsQS1DW2D0VfRSS2UvIuLQ
若链接失效请留言邮箱:[email protected]
