贴上官方文档:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
这里的一个障碍,就是英文.不要虚就是上,hhh.读的越多,越熟练。
- 首先配置 /etc/hadoop/hadoop-env.sh
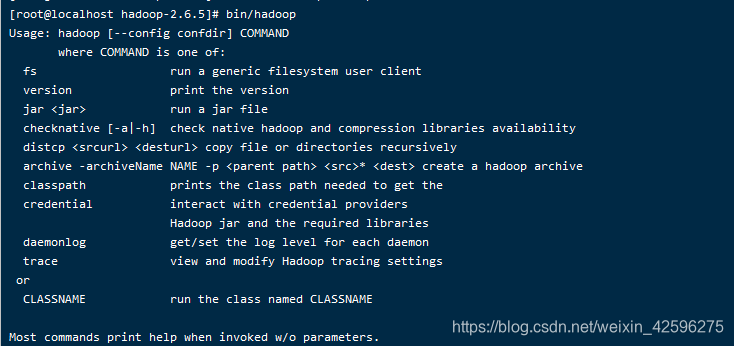
这里需要更改JAVA_HOME,直接这里替换成你的JDK的安装路径,一般来说应该是在module文件夹里 - 然后接下来你可以检测一下自己是否已经成功有了Hadoop的环境,输入如下代码:
bin/hadoop
效果图:
3. 在hadoop的bin的根目录穿件一个input文件夹
4. 接下来将
cp etc/hadoop/*.xml input
- 这里的含义是运行在share中的jar包,然后这里测试的主类是exaples,即是Hadoop中的一个样例程序,注意这里的output一定是一个不存在的文件夹.
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
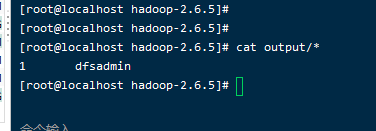
- 查看ouput文件夹,如果有输出,则表明Hadoop的本地运行没有什么问题了,就相当于最开始学习C语言时候的HelloWorld
命令:
cat output/*
案列二
测试wordcount类
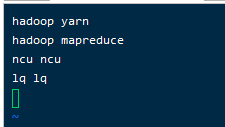
- 创建一个输入文件夹 wcinput,并在文件夹里面编辑一个input文件
mkdir wcinput
vim wc.input
运行效果:
2. 在bin的根目录里面
使用命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount wcinput wcoutput
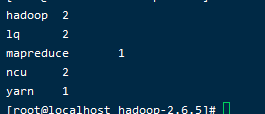
- 查看wcoutput信息
cat wcoutput/*
over;
本地模式的用途一般只用于测试。
That’s all.
