这篇文章是在之前文章的基础之上进行的Hadoop运行模式-本地模式
必看
1.hadoop运行环境搭建-虚拟机安装与配置(开发重点)
2.虚拟机安装机安装JDK以及Hadoop(保姆级教程)
官方Grep案例
- 创建在hadoop-2.7.2文件下面创建一个input文件夹
[hadoop@hadoop101 hadoop-2.7.2]$ mkdir input
- 将Hadoop的xml配置文件复制到input
[hadoop@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input
- 执行share目录下的MapReduce程序
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
grep input output 'dfs[a-z.]+'
- 查看输出结果
[hadoop@hadoop101 hadoop-2.7.2]$ cat output/part-r-00000

官方WordCount案例
- 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[hadoop@hadoop101 hadoop-2.7.2]$ mkdir wcinput
- 在wcinput文件下创建一个wc.input文件
[hadoop@hadoop101 hadoop-2.7.2]$ cd wcinput
[hadoop@hadoop101 hadoop-2.7.2]$ touch wc.input
- 编辑wc.input文件
[hadoop@hadoop101 hadoop-2.7.2]$ vi wc.input
在文件中输入如下内容
xianglin yuanyun baibaihe
linlin chen lixiaolu
chen chen liuyifei jiangsuying
xiang chenyuanyuan
chenyuangyuan
保存退出::wq
4. 回到Hadoop目录/opt/module/hadoop-2.7.2
[hadoop@hadoop101 wcinput]$ cd /opt/module/hadoop-2.7.2/
- 执行程序
hadoop jar
[hadoop@hadoop101 wcinput]$
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
wordcount wcinput wcoutput
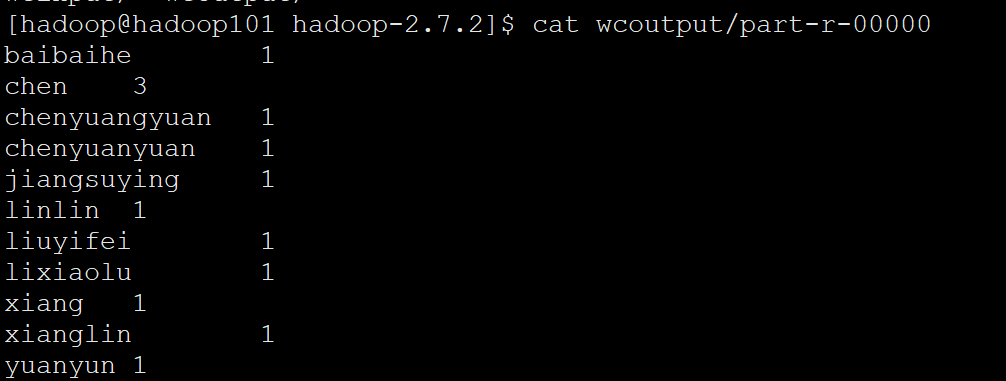
- 查看结果
[hadoop@hadoop101 hadoop-2.7.2]$ cat wcoutput/part-r-00000