起步
大二上学期快结束时,在中国大学MOOC中无意接触到嵩天的python语言设计基础,‘人生苦短,我用python’犹记在心,学完基础后,总感觉浅了些,于是在网上找了一些资料,看了慕课网的bobby老师视频,也接触到了scrapy这个爬虫框架,于是就有了下面这个从入大学以来做的第一个python项目-基于scrapy的搜索引擎。
正则表达式
常用正则符号:
. 通配符 代替任意一个字符 \n不行
^ 尖角符 对字符串开始进行匹配
$ 刀类符 对字符串结尾进行匹配
* 星号 对字符串重复匹配 重复前面的字符0到多次
+ 加号 对字符串重复匹配 前面的字符至少出现1次
?问号 对字符串重复匹配 前面的字符只能出现0到1次
{} 大括号 对字符串重复匹配 前面的字符重复的次数在指定括号的范围内
*->{0,正无穷} +->{1,正无穷} ?->{0,1}
#----------------------------------------------------------------------
[] 中括号 匹配中括号内字符集范围内中的任一字符(或关系)
[.,*,?] 取消元字符的特殊功能 ****例外 (\ -范围 ^取反)
| 或
\ 反斜杠后面跟元字符去除特殊功能 *****
\ 反斜杠后面跟普通字符实现特殊功能 *****
\d 匹配任何十进制数:[0-9]
[\u4E00-\u9FA5] 汉字
\D 匹配任何非数字字符:[^0-9]
\s 匹配任何空白字符:[ \t\n\r\f\v]
\S 匹配任何非空白字符: [^ \t\n\r\f\v]
\w 匹配任何字母数字字符:[a-zA-Z0-9_]
\W 匹配任何非字母数字字符:[^a-zA-Z0-9_]
\b 匹配一个特殊字符的边界 也就是指单词和空格间的位置
常用语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
示例:
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
'(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"“作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\“表示。同样,匹配一个数字的”\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
字符编码
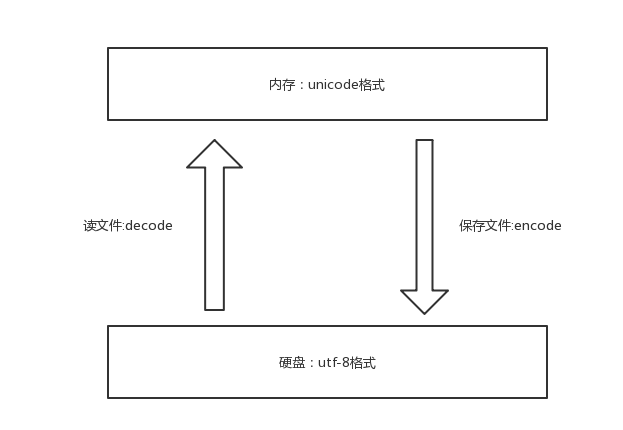
字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码
爬虫去重

深度优先及广度优先
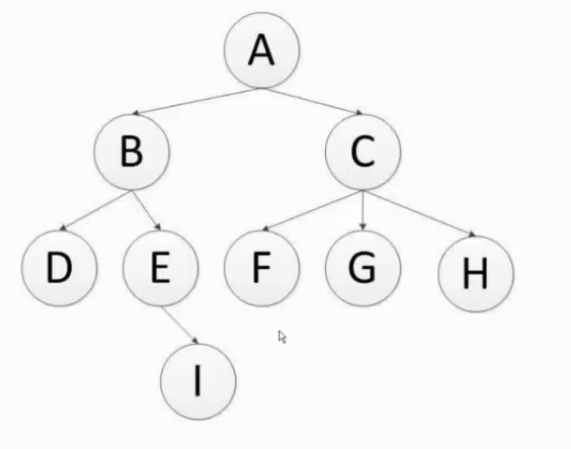

伪代码:


