功能描述
本文以获取sina首页为例,描述如何使用java获取web页面中的url链接地址。
示例代码
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.junit.Test;
public class App {
public static void main(String[] args) {
parse();
}
public void parse() {
Document doc;
try {
int cnt = 0;
String url = "https://www.sina.com.cn/";
doc = Jsoup.connect(url).get();
Elements rows = doc.select("div ul li");
if (rows.size() > 0) {
for (Element row : rows) {
String link = row.select("a").attr("href");
String title = row.select("a").text();
System.out.println((++cnt) + ":\t" + title + "\t" + link);// 获取文件链接地址
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
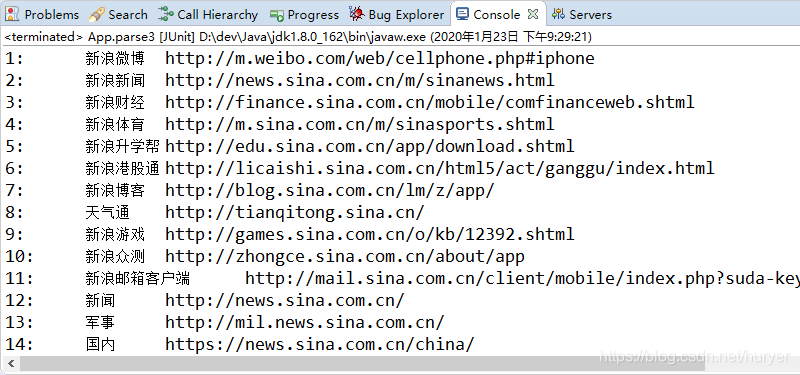
输出结果: