矩阵加权帧内预测(Matrix weighted intra prediction,MIP)是VTM5.0中新加的帧内预测技术。该技术的核心就是训练矩阵,当前的亮度预测块的相邻采样点首先进行平均操作减少采样点数目,构成一个向量,然后该向量和视频序列集训练的一个参数矩阵相乘,通过该矩阵和向量相乘得到一个部分预测值的散点阵列,最后通过双线性插值生成出最终的预测值。
如果预测一个WxH的PU,MIP使用上边的W个重建像素,左边的H个重建像素作为参考像素。参考像素的生成方法和普通的帧内预测一样。然后经过平均、矩阵向量相乘、线性插值三个步骤得到最终预测值。

1、平均
首先需要从左边参考列和上边参考行通过邻域平均的方法取参考样点。当W=H=4时,左边取2个上边取2个,共4个。其他情况下左边取4个,上边取4个,共8个。如上图左边部分所示。
// init reduced boundary size
if (m_blockSize.width > 4 || m_blockSize.height > 4)
{
m_reducedBoundarySize = Size(4, 4);
}
else
{
m_reducedBoundarySize = Size(2, 2);
}计算邻域平均是个下采样过程,如下:

void PredictorMIP::doDownsampling( int* dst, const int* src, const SizeType srcLen, const SizeType dstLen )
{
// TODO: Check if src and dst can ever be negative. If not assign unsigned type and simplify rounding.
const SizeType downsmpFactor = srcLen / dstLen;
CHECKD( srcLen != dstLen * downsmpFactor, "Need integer downsampling factor." );
CHECKD( ( downsmpFactor & ( downsmpFactor - 1 ) ) != 0, "Need power of two downsampling factor." );
const int log2DownsmpFactor = g_aucLog2[ downsmpFactor ];
const int roundingOffsetPositive = ( 1 << ( log2DownsmpFactor - 1 ) );
for( SizeType srcIdx = 0, dstIdx = 0; dstIdx < dstLen; ++dstIdx )
{
int sum = 0;
for( SizeType blockIdx = 0; blockIdx < downsmpFactor; ++blockIdx, ++srcIdx )
{
sum += src[ srcIdx ];
}
const int roundingOffset = roundingOffsetPositive - ( sum < 0 ? 1 : 0 );
dst[ dstIdx ] = ( sum + roundingOffset ) >> log2DownsmpFactor;
}
}
取出的参考样点要拼接成长度为4或8的向量。拼接方式如下:

其中mode指的是MIP-mode。
#if JVET_N0217_MATRIX_INTRAPRED
int getNumModesMip(const Size& block)
{
if (block.width > (4 * block.height) || block.height > (4 * block.width))
{
return 0;
}
if( block.width == 4 && block.height == 4 )
{
return 35;
}
else if (block.width <= 8 && block.height <= 8)
{
return 19;
}
else
{
return 11;
}
}
bool PredictorMIP::isTransposed( const int modeIdx ) const
{
return ( modeIdx > ( m_numModes / 2 ) );
}2、矩阵向量相乘
上一步得到的向量和一个训练好的矩阵相乘,再加上一个偏移量得到预测值。

其中矩阵A和向量b都是训练好的,取自于集合S0,S1或S2。
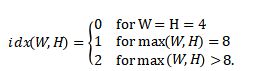
int PredictorMIP::getWeightIdx( const int modeIdx ) const
{//!<对于模式号大于m_numModes / 2 的需要进行折叠和小于m_numModes / 2 的使用相同矩阵
if( modeIdx > m_numModes / 2 )
{
return modeIdx - m_numModes / 2;
}
else
{
return modeIdx;
}
}
void PredictorMIP::getMatrixBias( const short*& matrix, const short*& bias, const int modeIdx ) const
{
const int idx = getWeightIdx( modeIdx );
//!<4x4块使用mipMatrix4x4和mipBias4x4里的矩阵和向量,下同
if( m_blockSize.width == 4 && m_blockSize.height == 4 )
{
matrix = &mipMatrix4x4[idx][0][0];
bias = &mipBias4x4 [idx][0];
}
else if( m_blockSize.width <= 8 && m_blockSize.height <= 8 )
{
matrix = &mipMatrix8x8[idx][0][0];
bias = &mipBias8x8 [idx][0];
}
else
{
matrix = &mipMatrix16x16[idx][0][0];
bias = &mipBias16x16 [idx][0];
}
}上面代码中mipMatrix4x4和mipBias4x4就是S0,mipMatrix8x8和mipBias8x8就是S1,mipMatrix16x16和mipBias16x16就是S2。
mipMatrix4x4里含18个16x4的矩阵,mipBias4x4里含18个16维的向量,用于4x4的块。
mipMatrix8x8里含10个16x8的矩阵,mipBias8x8里含10个16维的向量,用于4x8,8x4,8x8块。
mipMatrix16x16里含6个64x8的矩阵,mipBias16x16里含6个64维的向量,用于其他块。
由于篇幅限制,具体的矩阵和向量值就不贴了。
注:
1、由getNumModesMip函数可知,4x4块有35种MIP模式,4x8,8x4,8x8块有19种MIP模式,其他情况有11种模式。而这里S0,S1,S2长度分别是18,10,6,比之前减半了。注意由getWeightIdx可知每2种模式共享一个矩阵和向量。
2、对于4xn,nx4(n>8)的块,由上面公式可知其对应的矩阵A应该是32x8,这里使用S2内的矩阵和向量进行计算,其中会丢掉矩阵中的32行和向量中的32个值。丢掉的行分别对应于生成的8x8矩阵中的x奇数位置和y的奇数位置。
3、插值
插值是一个上采样过程。

如果两个方向都需要插值,如果W<H先进行水平方向插值否则先进行垂直方向插值。
以WxH块的垂直插值为例,其中max(W,H)≧8且W≧H。
首先,将待插值的矩阵扩展到上面一行,如图1右半部分所示。上边一行按下式得到。
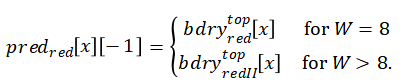
然后,对空余位置利用相邻值按下式进行插值。

从上面公式可以看出,当上采样2倍时即U_ver=2或H_ver=2,进行插值计算时不需要乘法运算。在其他情况下每次插值计算会进行不多于2次乘法运算。
void PredictorMIP::predictionUpsampling1D( int* const dst, const int* const src, const int* const bndry,
const SizeType srcSizeUpsmpDim, const SizeType srcSizeOrthDim,
const SizeType srcStep, const SizeType srcStride,
const SizeType dstStep, const SizeType dstStride,
const unsigned int upsmpFactor )
{
// TODO: Check if src and dst can ever be negative. If not assign unsigned type and simplify rounding.
const int log2UpsmpFactor = g_aucLog2[ upsmpFactor ];
CHECKD( upsmpFactor <= 1, "Upsampling factor must be at least 2." );
SizeType idxOrthDim = 0;
const int* srcLine = src;
int* dstLine = dst;
while( idxOrthDim < srcSizeOrthDim )
{
SizeType idxUpsmpDim = 0;
const int* before = bndry + idxOrthDim;
const int* behind = srcLine;
int* currDst = dstLine;
while( idxUpsmpDim < srcSizeUpsmpDim )
{
SizeType pos = 1;
int scaledBefore = ( *before ) << log2UpsmpFactor;
int scaledBehind = 0;
while( pos <= upsmpFactor )
{
scaledBefore -= *before;
scaledBehind += *behind;
*currDst = scaledBefore + scaledBehind;
*currDst = ( *currDst + ( 1 << ( log2UpsmpFactor - 1 ) ) -
( *currDst < 0 ? 1 : 0 ) ) >> log2UpsmpFactor;
pos++;
currDst += dstStep;
}
idxUpsmpDim++;
before = behind;
behind += srcStep;
}
idxOrthDim++;
srcLine += srcStride;
dstLine += dstStride;
}
}4、示例
下面给出一个完整的MIP算法过程是示例。
1.对于4x4的块,从左边和上边参考行各取两个值组成一个4维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S0。完成矩阵向量相乘和偏移值相加后得到一个16维的向量。这个16维向量形成一个4x4的矩阵不用进行插值直接作为预测矩阵。预测矩阵的每个值需要进行(4x16)/(4x4)=4次乘法运算。

2.对于8x8的块,从左边和上边参考行各取4个值组成一个8维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S1。完成矩阵向量相乘和偏移值相加后得到一个16维的向量。这个16维向量形成预测矩阵的奇数位置值。然后在垂直和水平方向进行插值,由于这个插值过程不需要进行乘法运算,所以预测矩阵的每个值需要进行(8x16)/(8x8)=2次乘法运算。

3.对于8x4的块,从左边和上边参考行各取4个值组成一个8维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S1。完成矩阵向量相乘和偏移值相加后得到一个16维的向量。这个16维向量形成预测矩阵的奇数行值和所有的列值。然后在水平方向进行插值,由于这个插值过程不需要进行乘法运算,所以预测矩阵的每个值需要进行(8x16)/(8x4)=4次乘法运算。4x8块处理过程类似。

4.对于16x16的块,从左边和上边参考行各取4个值组成一个8维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S2。完成矩阵向量相乘和偏移值相加后得到一个64维的向量。这个64维向量形成预测矩阵的奇数行值和奇数列值。然后在垂直和水平方向进行插值,由于插值过程不需要进行乘法运算,所以预测矩阵的每个值需要进行(8x64)/(16x16)=2次乘法运算。

对于更大尺寸的块处理过程类似,很容易计算出每个样点乘法运算次数小于4。
对于Wx8,W>8的块,生成的8x8预测矩阵包含所有行和奇数列,所以只需要在水平方向进行插值。预测矩阵的每个值需要进行(8x64)/(Wx8)=64/W次乘法运算。当W=16时,它的线性插值过程不需要乘法运算。当W>16时,每个像素插值过程需要的乘法运算少于2次。所以每个像素总的乘法运算小于等于4次。8xW类似。
对于Wx4的块,矩阵相乘时要去掉矩阵的奇数行,最终只需要在水平方向进行插值。预测矩阵的每个值需要进行(8x32)/(Wx4)=64/W次乘法运算。当W=16时,它的线性插值过程不需要乘法运算。当W>16时,每个像素插值过程需要的乘法运算少于2次。所以每个像素总的乘法运算小于等于4次。4xW类似。
感兴趣的请关注微信公众号Video Coding

