文章目录
JVM内存布局
(1)线程共享的
Java堆
Eden区
Survivor区
方法区
(2)线程不共享的
虚拟机栈
本地方法栈
程序计数器
数据库对象
触发器,表,视图,存储过程,索引,缺省值,图表,用户,规则等等吧。
数据库索引的类型
(1)全文索引
(2)hash索引
(3)BTree索引
(4)RTree索引
(1)普通索引:仅加速查询
(2)唯一索引:加速查询+列值唯一(可以有null)
(3)主键索引:加速查询+列值唯一(不可以有null)+ 表中只有一个
(4)组合索引:多列值组合成一个索引,专用于组合搜索,效率高于索引合并
(5)全文索引:对文本的内容进分词,进行搜索
如何解决高并发
(1)html静态化
(2)图片服务器分离。建立单独的图片服务器
(3)使用数据库集群。 库表散列
(4)缓存技术
(5)镜像
(6)负载均衡
sql优化方向
(1)表连接数要少。链接越多,性能越差
(2)如果不可避免,可以使用临时表存储临时结果
(3)少用子查询
(4)视图的嵌套不宜过深
(5)尽量不要让索引失效
NULL列是不允许使用索引的。
字符串连接也是会使索引失效
like通配符是会使索引失效的
order by子句中药尽量使用索引字段
not 运算也是会使索引失效的。
(6)使用exits代替in
awk命令
https://blog.csdn.net/jin970505/article/details/79056457
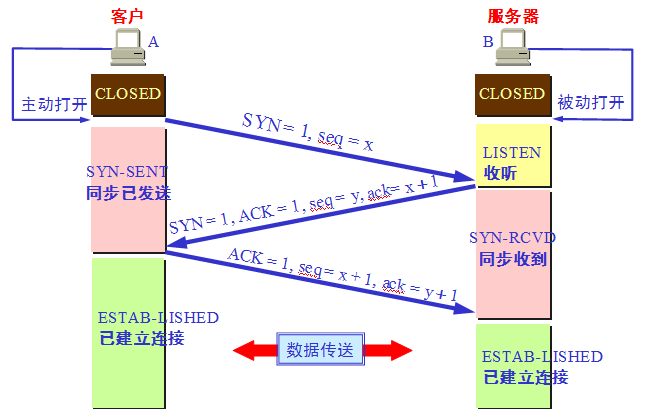
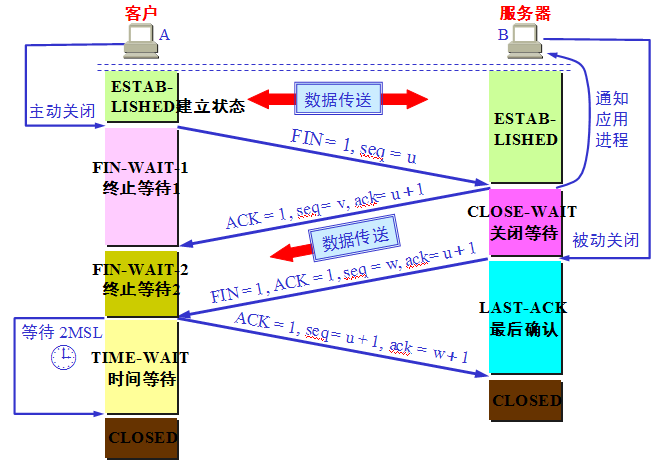
tcp 状态机
【扩展】 linux日志处理和其他监控
https://www.cnblogs.com/dion-90/articles/8568129.html
uptime命令
uptime
08:21:34 up 36 min, 2 users, load average: 0.00, 0.00, 0.00
#当前服务器时间: 08:21:34
#当前服务器运行时长 36 min
#当前用户数 2 users
#当前的负载均衡 load average 0.00, 0.00, 0.00,分别取1min,5min,15min的均值
sar命令
性能监控
iostat
Device: 以sdX形式显示的设备名称
tps: 每秒进程下发的IO读、写请求数量
KB_read/s: 每秒从驱动器读入的数据量,单位为K。
KB_wrtn/s: 每秒从驱动器写入的数据量,单位为K。
KB_read: 读入数据总量,单位为K。
KB_wrtn: 写入数据总量,单位为K。
链表反转
public static Node reverseList(Node head)
{
if(head == null || head.next == null)
return head;
Node preNode = null;
Node currentNode = head;
Node nextNode = null;
while(currentNode!= null)
{
nextNode = currentNode.next;
currentNode.next = preNode;
preNode = currentNode;
currentNode = nextNode;
}
return preNode;
}
我曾经的一个错误解答:

select poll epoll
https://www.cnblogs.com/aspirant/p/9166944.html
1、支持一个进程所能打开的最大连接数
select
单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的
epoll
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接
2、FD剧增后带来的IO效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll
同上
epoll
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3、 消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
同上
epoll
epoll通过内核和用户空间共享一块内存来实现的。
hdfs优缺点
优点
1. 高容错
副本机制
2. 适合批处理
“移动计算”
3. 适合大数据处理
4. 流式访问
一写多读。
5. 可构建在廉价机器上面
主要还是高可靠性
缺点
1. 不适合第延迟的场景,适合高吞吐
2. 无法对海量小文件进行存储
3. 不支持并发写入,文件的随机修改
hdfs的RPC
linux内存管理
从进程地址空间:段堆栈讲起,然后谈访存时四级和五级页表和tlb,再讲缺页中断。缺页中断在文件映射和匿名文件映射时各不同,文件映射需要分配页缓存并执行dma,而匿名文件映射是由memory management code管理,具体是由buddy 分配器。可能面临物理内存用完的情况,讲lru。然后替换的数据丢哪,如果是匿名内存,会丢到磁盘的交换区。
(1) 总结文: https://software.intel.com/en-us/articles/how-memory-is-accessed
()
虚拟地址和物理地址的映射
Linux分页机制
【页地址】【页内偏移】
页表
多级页表
TLB(Translation Lookaside Table)
tlb miss代价很大,解决方案如下:
(1) 修改页的大小
(2)使用huge page
(3) Carefully planning how your data fits in the pages
缺页中断
https://blog.csdn.net/a7980718/article/details/80895302
缓存替换
active inactive
两个标识位:PG_referenced 和 PG_active
Linux环境下cpp程序问题诊断与调优
一、cpu问题
1. uptime命令
up 了多久。机器有没有重启可以快速发现
登录了多少个user
查看负载情况
2. vmstat
虚拟内存的监控
3. top命令
4. strace
可以分析具体线程的系统调用耗时
5. 分析cpu瓶颈——perf
6. 精确到函数的性能分析——火焰图
7. 分析各个线程的资源消耗情况,线程内函数消耗情况:valgrind
8. 分析程序各个线程的堆栈执行情况:pstack & pt-pmp
内存问题
(1)开发要求:尽量避免手工管理内存。尽量使用shared_ptr,unique_ptr等智能指针。
(2)valgrind工具
(3)为多线程优化的通用内存库。 jemalloc和tcmalloc
(4) free -hw观察内存使用情况
(5)主动清理page cache,主动sync刷新脏页
(6) 关闭swap
IO问题
观测磁盘IO情况
(1) dd命令:简单测试磁盘io性能
(2)fio:测试随机读写性能
(3)iostat
观测进程IO和句柄
(1) iotop:观察各个进程的IO消耗情况
(2) 通过proc文件系统查看进程句柄情况:ls /proc/87091/fd -l
(3) lsof:查看进程句柄情况
网络问题
(1) netstat:查看网络连接信息
(2) lsof:查看开了端口的进程 lsof -i :36000
(3)sar命令:查看网卡流量和包量
sar -n DEV -n EDEV 1
(4)tcpdump:数据传输问题诊断
(5)wireshark工具
其它
gdb
日志
