背景
在研究双向队列之前,是遇到了这么一道题。
146. LRU缓存机制
这道题的思路是HashMap与双向队列的组合。LRU就是删除最近最少使用的数据值。
比如我先打开了支付宝,之后打开了手机淘宝,之后打开微信,此时在后台就是如下排列

之后我又点击支付宝,在后台中就会来到队友
假如缓存容量为3的话,此时又打开了时钟,就会把淘宝从缓存中删除,因为他是最近最少使用的应用。
那么这道题的思路很清晰了,就是使用一个队列,然后只要用户调用get函数去查找某个key(应用),就把这个key(键值对)放在队列头部,当用户向队列put新的键值对的时候,我们就要判断队列的长度是否超过缓存容量,不超过的话就把新的键值对插入队列的头部,超过的话就把队列尾部的键值对弹出,然后将新的键值对插入队列的头部。下面是代码形式的解释。
/* 缓存容量为 2 */
LRUCache cache = new LRUCache(2);
// 你可以把 cache 理解成一个队列
// 假设左边是队头,右边是队尾
// 最近使用的排在队头,久未使用的排在队尾
// 圆括号表示键值对 (key, val)
cache.put(1, 1);
// cache = [(1, 1)]
cache.put(2, 2);
// cache = [(2, 2), (1, 1)]
cache.get(1); // 返回 1
// cache = [(1, 1), (2, 2)]
// 解释:因为最近访问了键 1,所以提前至队头
// 返回键 1 对应的值 1
cache.put(3, 3);
// cache = [(3, 3), (1, 1)]
// 解释:缓存容量已满,需要删除内容空出位置
// 优先删除久未使用的数据,也就是队尾的数据
// 然后把新的数据插入队头
cache.get(2); // 返回 -1 (未找到)
// cache = [(3, 3), (1, 1)]
// 解释:cache 中不存在键为 2 的数据
cache.put(1, 4);
// cache = [(1, 4), (3, 3)]
// 解释:键 1 已存在,把原始值 1 覆盖为 4
// 不要忘了也要将键值对提前到队头
解决方法
解决方法就是双向链表+哈希表,如下图所示。下图出处
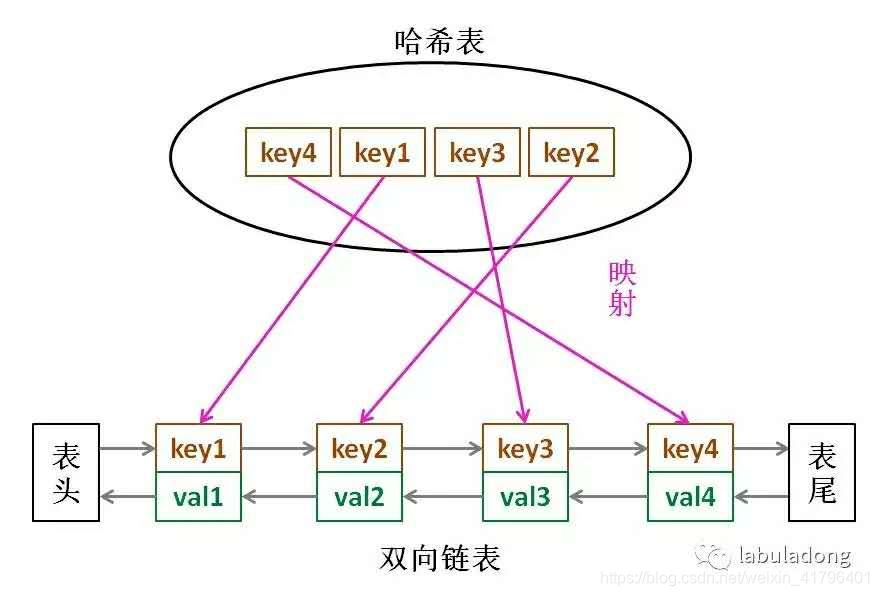
具体为什么这么解决先放一放,先说下双向链表要实现什么功能。
1.在队头插入元素(每次get操作中都要插入数据头部),
2.删除队尾的元素(每次都要弹出队尾的元素)
3.删除元素(当要把当前的键值对插入到头部时,需要先删除之前的那个键值对)。
1.链式节点
这个节点需要包含key和val以及指向前一个节点的last与指向后一个节点的next。
/**
* 双向链表中的节点类,存储key是因为我们在双向链表删除表尾的值时,只是返回了一个节点,
* 所以这个节点要包括key值,这样我们的哈希表才可以删除对应key值的映射
*/
class DoubleNode {
DoubleNode last;
DoubleNode next;
int key,val;
public DoubleNode(int key,int val){
this.val = val;
this.key = key;
}
}
2.双向链表
值得注意的是,我们需要两个链式节点来作为头和尾,同时在构造函数里,我们要创建这两个链式节点,并将二者连起来。
下面通过图例来解释各个方法,首先这是当前的双向链表。

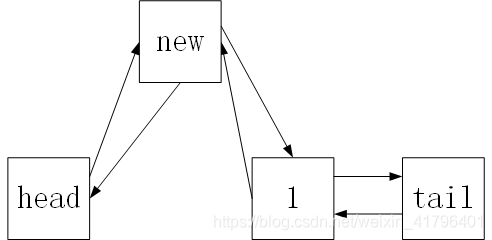
addFirst方法
可以看到新的节点new要插入头部,首先要把node的next指向1,之后要把1的last指向new,之后把new的last指向head,最后把head的next指向new。O(1)时间复杂度
remove方法
简单来说就是将head和tail与1的联系删去,残忍。
让1前面的节点的next不指向1,而指向1后面的那个节点
让1后面的节点的last不指向1,而指向1前面的节点,这样就把1从链式结构中剔除出去了。
注意这里没有说head和tail是因为双向链表可能很长,删去1个节点,是连接上他前后的两个节点。
O(1)时间复杂度
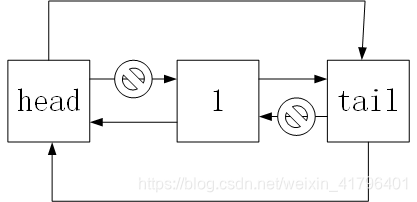
removeLast方法
和remove方法相似,只不过最后一个后面的节点是确定的,就是tail节点。
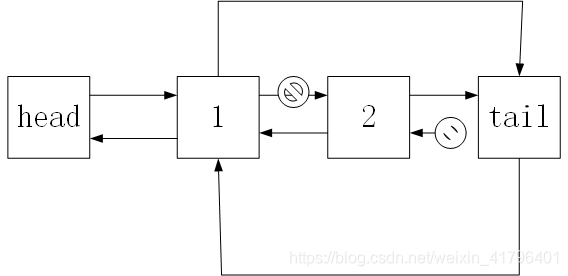
通过图中了解了如何写这几个函数,接下来就看完整的代码吧。
/**
* 双向链表,实现插入队头,删除队尾,删除元素功能
*/
class DoubleList {
DoubleNode head;
DoubleNode tail;
int size = 0;
public DoubleList()
{
head = new DoubleNode(0,0);
tail = new DoubleNode(0,0);
head.next = tail;
tail.last = head;
}
//当一个值被get操作时,就把其放在队头
public void addFirst(DoubleNode node)
{
node.next = head.next;
head.next.last = node;
node.last = head;
head.next = node;
size++;
}
//删除元素
public void remove(DoubleNode node){
node.last.next = node.next;
node.next.last = node.last;
size--;
}
//删除队尾的元素
public DoubleNode removeLast(){
if (size==0)
return null;
DoubleNode node = tail.last;
node.last.next = tail;
tail.last = node.last;
size--;
return node;
}
public int size()
{
return size;
}
public String toString()
{
String s = "";
if(size==0)
return s;
int length = size;
DoubleNode node = head;
while(length>0)
{
node = node.next;
s += node.val;
length--;
}
return s;
}
}
最终代码
数据域要包括双向链表,一个哈希表。
get方法
首先判断哈希表中是否存在key,如果没有的话就返回-1,如果有的话就先将该key对应的节点插入到队列的队头(调用put方法,传入当前的key,与节点),然后返回该key对应的节点的value值。
put方法
1.首先根据key与节点的value值创建一个新的节点(DoubleNode)对象;
2.之后去判断当前key是否存在于map中,如果存在的话有两种情况1).是用户调用了get当前key,所以要使用put将当前key对应的节点放到队列头部;2).用户正常put(key,value),只不过当前put的key存在。无论是处于哪种情况,都要在双向链表删除原有key对应的节点,然后将新创建的节点插入队头,最后在map中更新key对应的节点(新节点)。
3.如果不存在当前map中,只能是用户put新的key与value,这种情况涉及判断当前链表的数量是否等于上限,如果等于上限,就把队列尾部的元素弹出,同时要将map中key与旧节点之间的映射删去,然后将新节点插入链表队头,最后在map中put key与新节点。
class LRUCache {
DoubleList cache;
Map<Integer,DoubleNode>map;
int capacity;
public LRUCache(int capacity) {
this.capacity = capacity;
cache = new DoubleList();
map = new HashMap<>();
}
public int get(int key) {
if(!map.containsKey(key))
return -1;
else{
DoubleNode node = map.get(key);
//把当前key对应的那个DoubleNode移动到队头
put(key,node.val);
return node.val;
}
}
public void put(int key, int value) {
DoubleNode newnode = new DoubleNode(key,value);
//要调整位置插入至最前面(可能是调用了get这个key于是我们要把这个DoubleNode放到队尾,也可能是put了一个新值,只不过key相同,这时就要更改下key对应的value,在这里我们是直接换一个DoubleNode去插入)
if(map.containsKey(key)){
DoubleNode lastNode = map.get(key);
cache.remove(lastNode);
cache.addFirst(newnode);
//不能忘记更新map
map.put(key,newnode);
}else{
if(cache.size==capacity)
{
//这里不光要把队尾去掉,也要把map中的key和DoubleNode的映射去掉
//这里也是为什么DoubleNode中要有key的原因,
DoubleNode last = cache.removeLast();
map.remove(last.key);
}
cache.addFirst(newnode);
map.put(key,newnode);
}
}
}
总结
1.这个题为什么要用双向链表,单向链表不可以么?
原因在于我要删除一个节点的时候,比较方便,因为知道当前节点的上一个节点与下一个节点。直接将二者连接起来即可。
2.为什么链式节点要包含key,如果单单是一个value不可以么
原因在于,当我们删除队尾节点时,我们只能返回这个节点,在map中也需要删除相应映射,所以链式节点必须要有key,否则map不知道去删除谁。
3.为什么map中的数据类型是<Integer,DoubleNode>,而不是<Integer,Integer>
其实问题在于为什么是key,DoubleNode而不是key,value。当执行put操作时,map中存在这个key的时候,我们需要在双向链表中删除掉当前这个节点,所以map中的应该是链式节点,而不是value。

