**
问题描述:
**
请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。它应该支持以下操作:get 和 put。
- get(key) - 如果键存在于缓存中,则获取键的值(总是正数),否则返回 -1。
- put(key, value) - 如果键不存在,请设置或插入值。当缓存达到其容量时,则应该在插入新项之前,使最不经常使用的项无效。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除
最近 最少使用的键。
「项的使用次数」就是自插入该项以来对其调用 get 和 put 函数的次数之和。使用次数会在对应项被移除后置为 0 。
进阶:
你是否可以在 O(1) 时间复杂度内执行两项操作?
示例:
LFUCache cache = new LFUCache( 2 /* capacity (缓存容量) */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 去除 key 2
cache.get(2); // 返回 -1 (未找到key 2)
cache.get(3); // 返回 3
cache.put(4, 4); // 去除 key 1
cache.get(1); // 返回 -1 (未找到 key 1)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
**
解题代码:
**
public class LFUCache {
private Map<Integer, ListNode> map;
/**
* 访问次数哈希表,使用 ListNode[] 也可以,不过要占用很多空间
*/
private Map<Integer, DoubleLinkedList> frequentMap;
/**
* 外部传入的容量大小
*/
private Integer capacity;
/**
* 全局最高访问次数,删除最少使用访问次数的结点时会用到
*/
private Integer minFrequent = 1;
public LFUCache(int capacity) {
map = new HashMap<Integer, ListNode>(capacity);
frequentMap = new HashMap<Integer, DoubleLinkedList>();
this.capacity = capacity;
}
/**
* get 一次操作,访问次数就增加 1;
* 从原来的链表调整到访问次数更高的链表的表头
*
* @param key
* @return
*/
public int get(int key) {
// 测试测出来的,capacity 可能传 0
if (capacity == 0) {
return -1;
}
if (map.containsKey(key)) {
// 获得结点类
ListNode listNode = removeListNode(key);
// 挂接到新的访问次数的双向链表的头部
int frequent = listNode.frequent;
addListNode2Head(frequent, listNode);
return listNode.value;
} else {
return -1;
}
}
/**
* @param key
* @param value
*/
public void put(int key, int value) {
if (capacity == 0) {
return;
}
// 如果 key 存在,就更新访问次数 + 1,更新值
if (map.containsKey(key)) {
ListNode listNode = removeListNode(key);
// 更新 value
listNode.value = value;
int frequent = listNode.frequent;
addListNode2Head(frequent, listNode);
return;
}
// 如果 key 不存在
// 1、如果满了,先删除访问次数最小的的末尾结点,再删除 map 里对应的 key
if (map.size() == capacity) {
// 1、从双链表里删除结点
DoubleLinkedList doubleLinkedList = frequentMap.get(minFrequent);
ListNode removeNode = doubleLinkedList.removeTail();
// 2、删除 map 里对应的 key
map.remove(removeNode.key);
}
// 2、再创建新结点放在访问次数为 1 的双向链表的前面
ListNode newListNode = new ListNode(key, value);
addListNode2Head(1, newListNode);
map.put(key, newListNode);
// 【注意】因为这个结点是刚刚创建的,最少访问次数一定为 1
this.minFrequent = 1;
}
// 以下部分主要是结点类和双向链表的操作
/**
* 结点类,是双向链表的组成部分
*/
private class ListNode {
private int key;
private int value;
private int frequent = 1;
private ListNode pre;
private ListNode next;
public ListNode() {
}
public ListNode(int key, int value) {
this.key = key;
this.value = value;
}
}
/**
* 双向链表
*/
private class DoubleLinkedList {
/**
* 虚拟头结点,它无前驱结点
*/
private ListNode dummyHead;
/**
* 虚拟尾结点,它无后继结点
*/
private ListNode dummyTail;
/**
* 当前双向链表的有效结点数
*/
private int count;
public DoubleLinkedList() {
// 虚拟头尾结点赋值多少无所谓
this.dummyHead = new ListNode(-1, -1);
this.dummyTail = new ListNode(-2, -2);
dummyHead.next = dummyTail;
dummyTail.pre = dummyHead;
count = 0;
}
/**
* 把一个结点类添加到双向链表的开头(头部是最新使用数据)
*
* @param addNode
*/
public void addNode2Head(ListNode addNode) {
ListNode oldHead = dummyHead.next;
// 两侧结点指向它
dummyHead.next = addNode;
oldHead.pre = addNode;
// 它的前驱和后继指向两侧结点
addNode.pre = dummyHead;
addNode.next = oldHead;
count++;
}
/**
* 把双向链表的末尾结点删除(尾部是最旧的数据,在缓存满的时候淘汰)
*
* @return
*/
public ListNode removeTail() {
ListNode oldTail = dummyTail.pre;
ListNode newTail = oldTail.pre;
// 两侧结点建立连接
newTail.next = dummyTail;
dummyTail.pre = newTail;
// 它的两个属性切断连接
oldTail.pre = null;
oldTail.next = null;
// 重要:删除一个结点,当前双向链表的结点个数少 1
count--;
return oldTail;
}
}
/**
* 将原来访问次数的结点,从双向链表里脱离出来
*
* @param key
* @return
*/
private ListNode removeListNode(int key) {
// 获得结点类
ListNode deleteNode = map.get(key);
ListNode preNode = deleteNode.pre;
ListNode nextNode = deleteNode.next;
// 两侧结点建立连接
preNode.next = nextNode;
nextNode.pre = preNode;
// 删除去原来两侧结点的连接
deleteNode.pre = null;
deleteNode.next = null;
// 维护双链表结点数
frequentMap.get(deleteNode.frequent).count--;
// 【注意】维护 minFrequent
// 如果当前结点正好在最小访问次数的链表上,并且移除以后结点数为 0,最小访问次数需要加 1
if (deleteNode.frequent == minFrequent && frequentMap.get(deleteNode.frequent).count == 0) {
minFrequent++;
}
// 访问次数加 1
deleteNode.frequent++;
return deleteNode;
}
/**
* 把结点放在对应访问次数的双向链表的头部
*
* @param frequent
* @param addNode
*/
private void addListNode2Head(int frequent, ListNode addNode) {
DoubleLinkedList doubleLinkedList;
// 如果不存在,就初始化
if (frequentMap.containsKey(frequent)) {
doubleLinkedList = frequentMap.get(frequent);
} else {
doubleLinkedList = new DoubleLinkedList();
}
// 添加到 DoubleLinkedList 的表头
doubleLinkedList.addNode2Head(addNode);
frequentMap.put(frequent, doubleLinkedList);
}
public static void main(String[] args) {
LFUCache cache = new LFUCache(2);
cache.put(1, 1);
cache.put(2, 2);
System.out.println(cache.map.keySet());
int res1 = cache.get(1);
System.out.println(res1);
cache.put(3, 3);
System.out.println(cache.map.keySet());
int res2 = cache.get(2);
System.out.println(res2);
int res3 = cache.get(3);
System.out.println(res3);
cache.put(4, 4);
System.out.println(cache.map.keySet());
int res4 = cache.get(1);
System.out.println(res4);
int res5 = cache.get(3);
System.out.println(res5);
int res6 = cache.get(4);
System.out.println(res6);
}
}
**
解题思路:
**
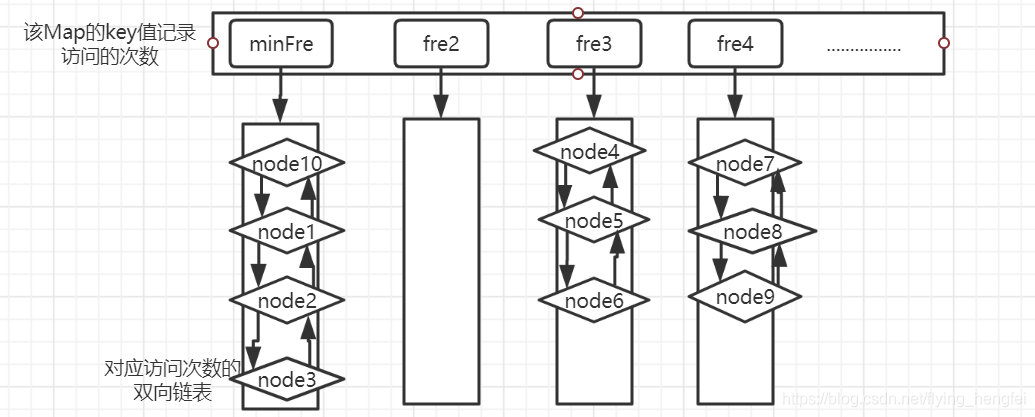
该问题采用哈希表+双向链表的方法进行解决,只看代码可能会很难看懂,下面是根据我自己的理解做的简图
1.存放数据的map(Map<Integer, ListNode-节点类型>)
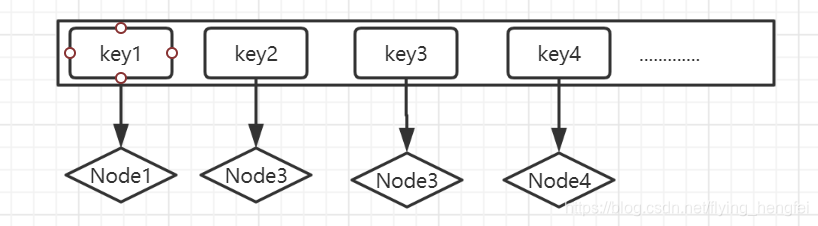
2.存放数据节点被访问次数的frequentMap(Map<Integer, DoubleLinkedList-双向链表类型>)
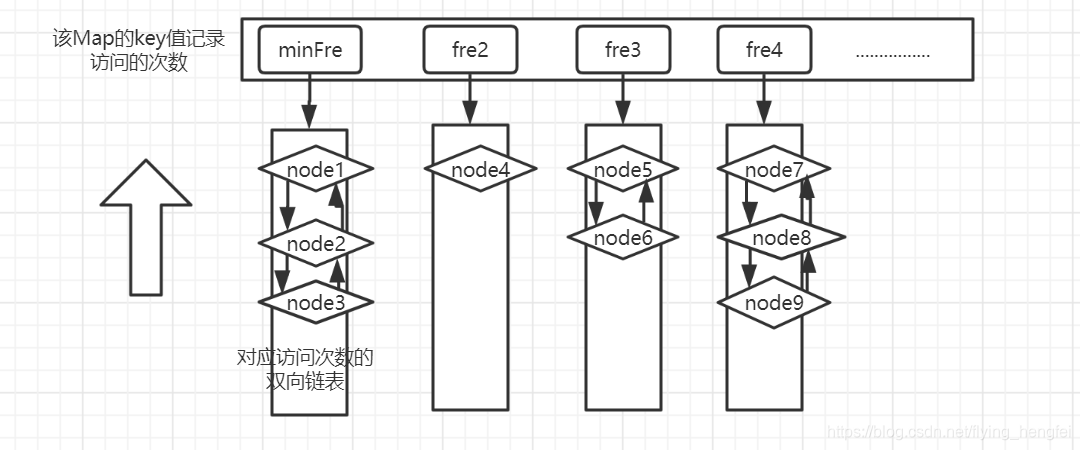
3.get方法-假设要读取node4
- 查询map中发现有这个数据节点
- 从frequentMap中获取到这个node4,将其分离出来成为游离节点,此时frequentMap的状态是这样的
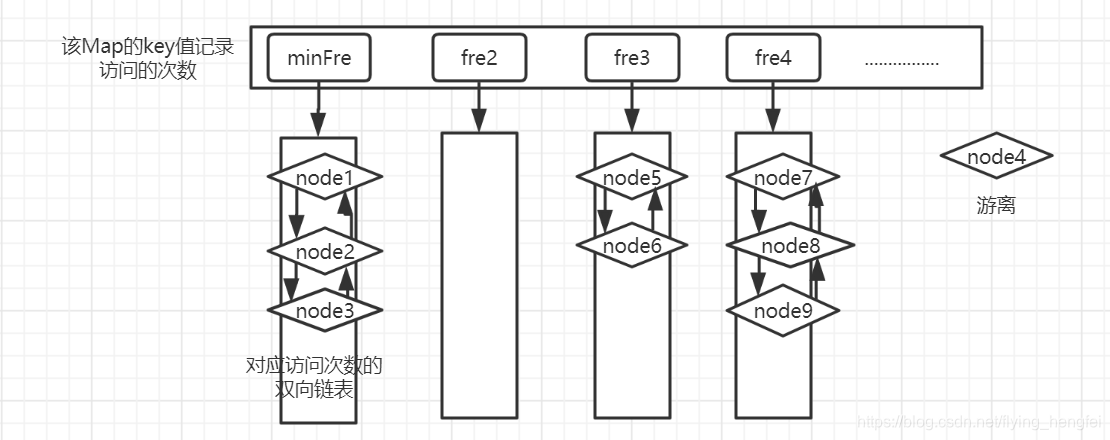
3.将node4中记录访问次数的count数加一,将其插入到目前对对应的次数的key下的双向链表的头部,frequentMap的状态:
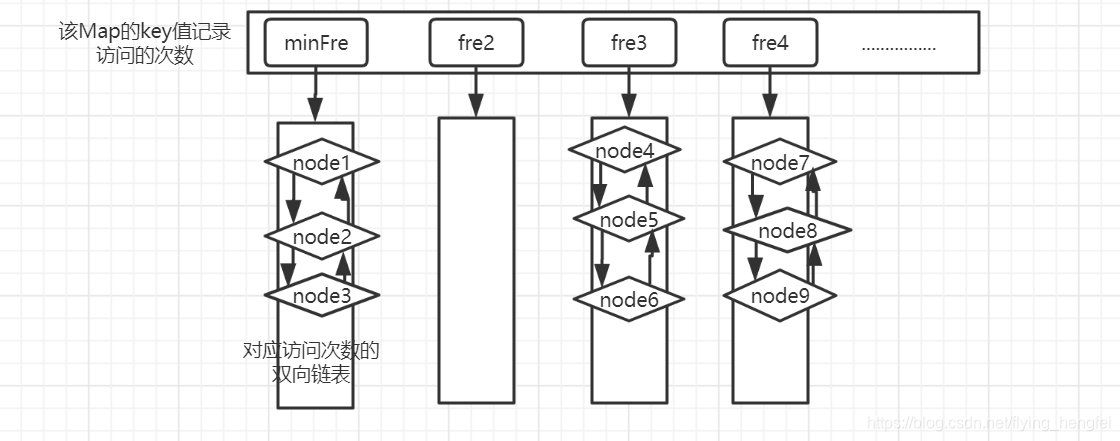
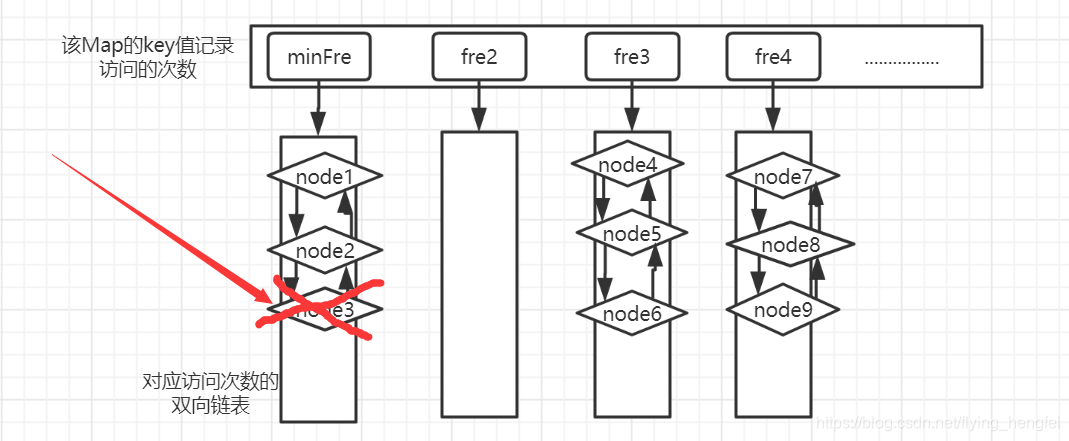
4.put方法-假设插入node10,并且此时的minFre(最小访问次数)为1
- 插叙此时map中是否包含这个数据节点node10,不包含则插入
- 如果此时map的容量没有满,则直接插入,而frequentMap状态:
- 如果此时map的容量已经满,则需要删除最近访问最少的节点,再进行插入(需要注意的是,新插入的数据的访问次数一定是1,所以minFre不是1的话,在插入结束后需要将minFre调整为1)
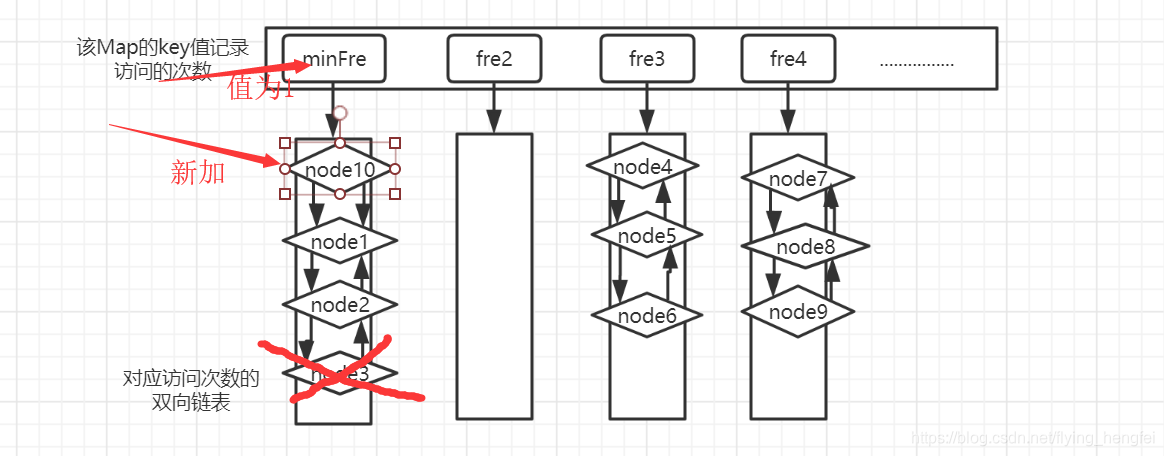
**
知识拓展
**
缓存算法 : 缓存算法是指令的一个明细表,用于提示计算设备的缓存信息中哪些条目应该被删去。常见类型包括LFU、LRU、ARC、FIFO、MRU。
最不经常使用算法(LFU):这个缓存算法使用一个计数器来记录条目被访问的频率。通过使用LFU缓存算法,最低访问数的条目首先被移除。这个方法并不经常使用,因为它无法对一个拥有最初高访问率之后长时间没有被访问的条目缓存负责。
最近最少使用算法(LRU):这个缓存算法将最近使用的条目存放到靠近缓存顶部的位置。当一个新条目被访问时,LRU将它放置到缓存的顶部。当缓存达到极限时,较早之前访问的条目将从缓存底部开始被移除。这里会使用到昂贵的算法,而且它需要记录“年龄位”来精确显示条目是何时被访问的。此外,当一个LRU缓存算法删除某个条目后,“年龄位”将随其他条目发生改变。
自适应缓存替换算法(ARC):在IBM Almaden研究中心开发,这个缓存算法同时跟踪记录LFU和LRU,以及驱逐缓存条目,来获得可用缓存的最佳使用。
最近最常使用算法(MRU):这个缓存算法最先移除最近最常使用的条目。一个MRU算法擅长处理一个条目越久,越容易被访问的情况。
先进先出算法(FIFO):FIFO是英文First In First Out 的缩写,是一种先进先出的数据缓存器,他与普通存储器的区别是没有外部读写地址线,这样使用起来非常简单,但缺点就是只能顺序写入数据,顺序的读出数据,其数据地址由内部读写指针自动加1完成,不能像普通存储器那样可以由地址线决定读取或写入某个指定的地址。
**
个人感悟
**
最近学习操作系统正好了解了一下缓存算法,没想到碰到了这个题,难度就不用描述啦,好在有大佬的帮助
我发现别人是5个小时才写出来代码,我2个小时才看懂,这可能就是与大佬之间的差距,为了拉近差距,我努力的去看代码,然后根据理解画出了图,这样更容易理解
在编程的学习中,数据结构和算法的应该算是重中之重,无论什么公司的笔试和面试都会考到,哈希表和链表也是其中必考的项目,所以多多学习然后熟练掌握才是王道,自勉!
