Index Pattern 设置
设置索引规则,用于区分数据源
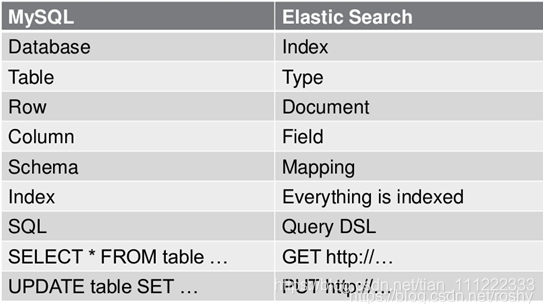
mysql和ES中的元素对比
index pattern (索引匹配规则)是目前在Kibana中十分重要的一个元素,我们通过日志收集服务filebeat将数据发送到elasticsearch中时会设置相应的index索引,每一个index对应其数据源,代码某一块的日志信息。设置收集信息index的时候建议尽可能细的区分设置,以方便对不同类型的日志做相应的汇总或者单独拆分搜索。
当前的索引规则
索引部分信息是在filebeat的filebeat.yml中
规则%{[fields][indexprefix]}-filebeat-%{[agent.version]}-%{+yyyy.MM.dd}
- %{[fields][indexprefix]} 表示自定义的前缀,区分服务环境和服务类型
- filebeat 固定字符
- %{[agent.version]} filebeat版本
- %{+yyyy.MM.dd} 当前日志, 这样的话每天的数据都是一个新的index 方便对历史的数据进行删除,大量的日志非常占用空间,同时也影响es的性能
找到Management菜单
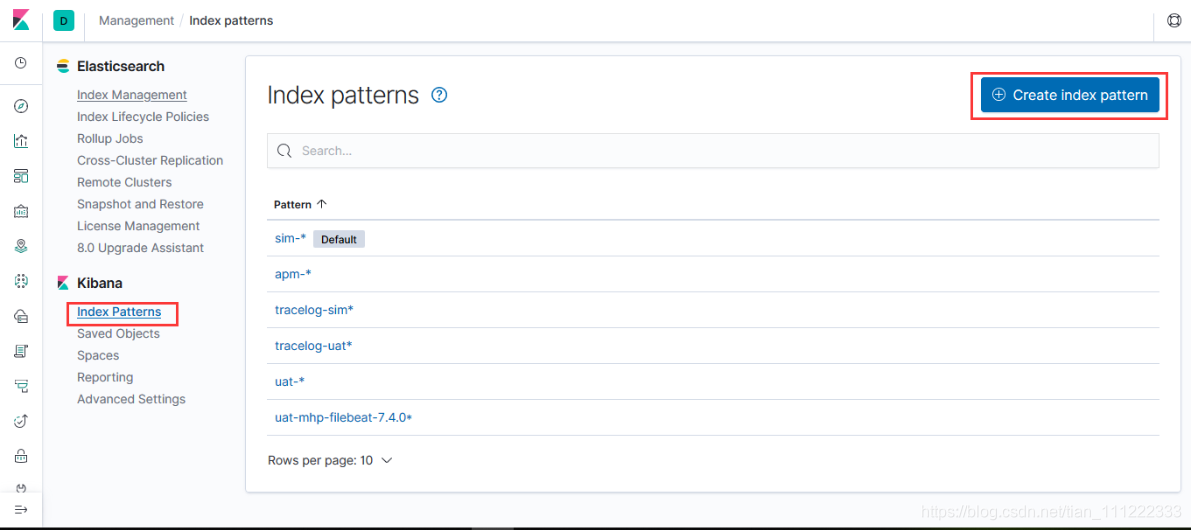
创建自定义index patterns
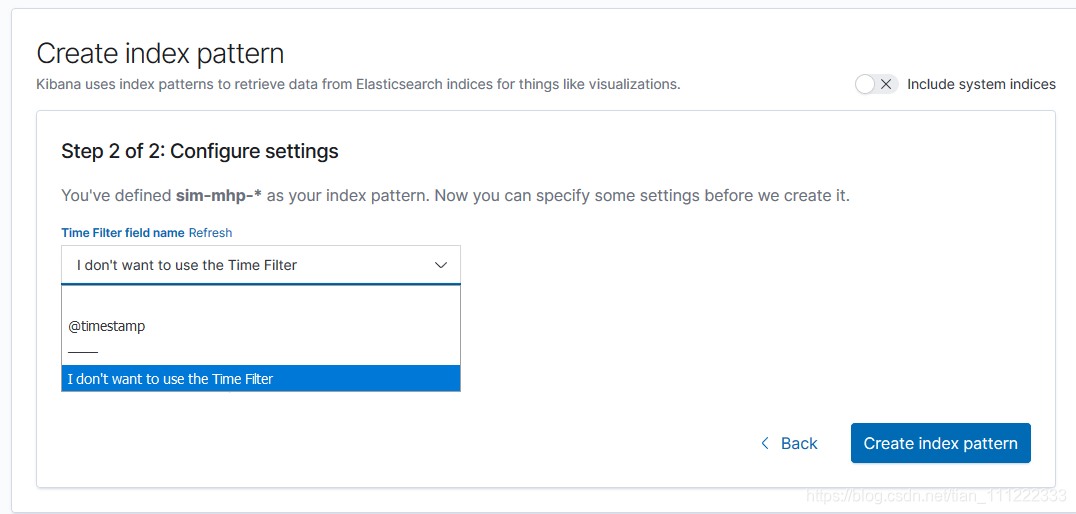
当系统不存在默认的index pattern 规则时,会提示去创建相关索引匹配规则,否则相关页面不知道从何处获取数据
根据需要来选择设置自己的匹配规则,支持前后**来模糊匹配,同一个index允许被不同的 index pattern 匹配到
此处会默认提供一个时间过滤器,可以选择不用,如果后面需要根据数据同步过来的时间做过滤的话可以加上去,日志信息中原先的时间因为读取格式问题,只能当作字符来匹配,不支持单独根据日志中打印的信息来过滤.另外,如果使用Time Filter还可以自动在Discover页面搜索结果页显示一个按照时间统计文件数目的图表