首先进行hadoop集群的hdfs,yarn等的相关配置,配置成功之后。进行如下操作:
1 启动Hadoop
执行命令启动前面实验部署好的Hadoop系统。
[root@master ~]# cd /usr/cstor/hadoop/
[root@master hadoop]# sbin/start-all.sh

使用jps 分别查看master的Java进程如下:

使用jps 分别查看其他slave1-4服务器上的Java进程如下:
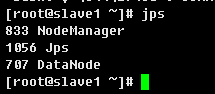
有如上信息说明Hadoop集群搭建成功。
停止进程操作:

[root@master ~]# cd /usr/cstor/h
hadoop/ hbase/ hive/
[root@master ~]# cd /usr/cstor/hadoop
[root@master hadoop]# cd sbin
[root@master sbin]# ll
[root@master sbin]# ./stop-all.sh

2.1 验证HDFS上没有/user/mapreduce/secsort/in的文件夹
[root@master ~]# cd /usr/cstor/hadoop/
[root@master hadoop]# bin/hadoop fs -ls / #查看HDFS上根目录文件 /
此时HDFS上应该是没有/user/mapreduce/secsort/in文件夹。
![]()
2.2 准备数据
输入数据如下:secsortdata.txt ('\t'分割)(数据放在/root/data/6目录下):
查看数据如下:

注意:这里之前如果没有数据文件的话需要使用远程连接的文件传输工具xftp或者其他进行数据文件的上传。
2.3 上传数据文件到HDFS
(1)新建上传路径
使用[root@master ~]# hdfs dfs -ls /查看没有发现有路径,则需要新建上传的路径[root@master ~]# hdfs dfs -mkdir -p /user/mapreduce/secsort/in 。
查看结果如下:

可以看到输入路径已经存在。
(注:这里的输入路径由于可以自由指定)
(2)上传数据文件到/user/mapreduce/secsort/in下。
[root@master ~]# hdfs dfs -put /root/data/6/secsortdata.txt /user/mapreduce/secsort/in
查看数据文件:
[root@master ~]# hdfs dfs -ls -R /

查看数据文件存在于该目录下即为上传成功。
3 编写IntPair程序
首先在eclipse上新建名为SecondarySort的java工程文件,然后新建类IntPair将其放在包mr的下面。
IntPair类用于数据的存储,并在IntPair类内部自定义Comparator类以实现第一字段和第二字段的比较。实现排序的功能。
程序如下:
IntPair 类:
package mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;
public class IntPair implements WritableComparable {
private IntWritable first;
private IntWritable second;
public void set(IntWritable first, IntWritable second) {
this.first = first;
this.second = second;
}
//注意:需要添加无参的构造方法,否则反射时会报错。
public IntPair() {
set(new IntWritable(), new IntWritable());
}
public IntPair(int first, int second) {
set(new IntWritable(first), new IntWritable(second));
}
public IntPair(IntWritable first, IntWritable second) {
set(first, second);
}
public IntWritable getFirst() {
return first;
}
public void setFirst(IntWritable first) {
this.first = first;
}
public IntWritable getSecond() {
return second;
}
public void setSecond(IntWritable second) {
this.second = second;
}
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
public boolean equals(Object o) {
if (o instanceof IntPair) {
IntPair tp = (IntPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
public String toString() {
return first + "\t" + second;
}
public int compareTo(IntPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}
注:程序非本人编写,来源于实验平台,这里只是记录一下所学知识。以方便自己和他人。
4 编写SecondarySort程序
在这个程序中定义了一个FirstPartitioner类,在FirstPartitioner类内部指定聚合规则为第一字段。实现聚合的功能。
此外,还需要开启MapReduce框架自定义Partitioner 功能和GroupingComparator功能。程序附在后面:
SecondarySort代码如下:
package mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SecondarySort {
static class TheMapper extends Mapper<LongWritable, Text, IntPair, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
int field1 = Integer.parseInt(fields[0]);
int field2 = Integer.parseInt(fields[1]);
context.write(new IntPair(field1,field2), NullWritable.get());
}
}
static class TheReducer extends Reducer<IntPair, NullWritable,IntPair, NullWritable> {
//private static final Text SEPARATOR = new Text("------------------------------------------------");
@Override
protected void reduce(IntPair key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static class FirstPartitioner extends Partitioner<IntPair, NullWritable> {
public int getPartition(IntPair key, NullWritable value,
int numPartitions) {
return Math.abs(key.getFirst().get()) % numPartitions;
}
}
//如果不添加这个类,默认第一列和第二列都是升序排序的。
//这个类的作用是使第一列升序排序,第二列降序排序
public static class KeyComparator extends WritableComparator {
//无参构造器必须加上,否则报错。
protected KeyComparator() {
super(IntPair.class, true);
}
public int compare(WritableComparable a, WritableComparable b) {
IntPair ip1 = (IntPair) a;
IntPair ip2 = (IntPair) b;
//第一列按升序排序
int cmp = ip1.getFirst().compareTo(ip2.getFirst());
if (cmp != 0) {
return cmp;
}
//在第一列相等的情况下,第二列按倒序排序
return -ip1.getSecond().compareTo(ip2.getSecond());
}
}
//入口程序
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SecondarySort.class);
//设置Mapper的相关属性
job.setMapperClass(TheMapper.class);
//当Mapper中的输出的key和value的类型和Reduce输出
//的key和value的类型相同时,以下两句可以省略。
//job.setMapOutputKeyClass(IntPair.class);
//job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//设置分区的相关属性
job.setPartitionerClass(FirstPartitioner.class);
//在map中对key进行排序
job.setSortComparatorClass(KeyComparator.class);
//job.setGroupingComparatorClass(GroupComparator.class);
//设置Reducer的相关属性
job.setReducerClass(TheReducer.class);
job.setOutputKeyClass(IntPair.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//设置Reducer数量
int reduceNum = 1;
if(args.length >= 3 && args[2] != null){
reduceNum = Integer.parseInt(args[2]);
}
job.setNumReduceTasks(reduceNum);
job.waitForCompletion(true);
}
}
5 打包程序
选择项目工程文件夹,右击选择“Export”进入如下界面:

选择JAR file ,点击“Next”进入如下界面:

选择图中箭头所指的文件和输出路径的位置,方便上传。
之后点击上面的“finish”即可完成打包,忽略警告信息即可。
6 运行程序
[root@master ~]# yarn jar SecondarySort.jar mr.SecondarySort /user/mapreduce/secsort/in/secsortdata.txt /user/mapreduce/secsort/out
其中“yarn”为命令,“jar”为命令参数,后面紧跟打包后的代码地址,“mr.SecondarySort”为主类名,mr为包名,“/user/mapreduce/secsort/in/secsortdata.txt”为输入文件在HDFS中的位置,“/user/mapreduce/secsort/out”为输出文件在HDFS中的位置。“SecondarySort.jar ”打包时的名称。
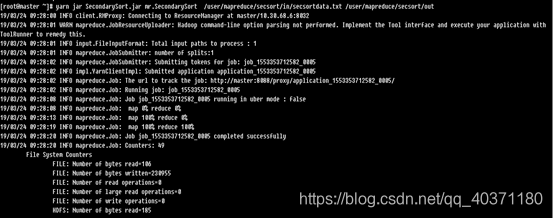

出现如上信息即为运行成功。
出现的问题:
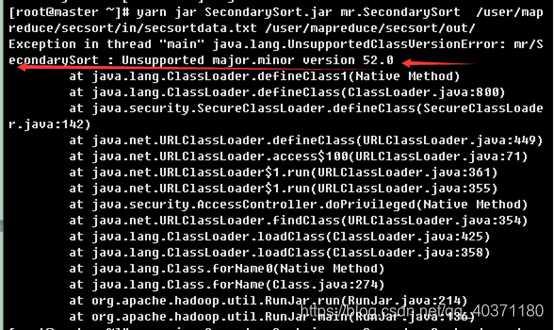
问题原因:在运行时出现了上述的版本不支持的问题,可以看出是由于java环境问题造成的,即为jdk版本不一致。
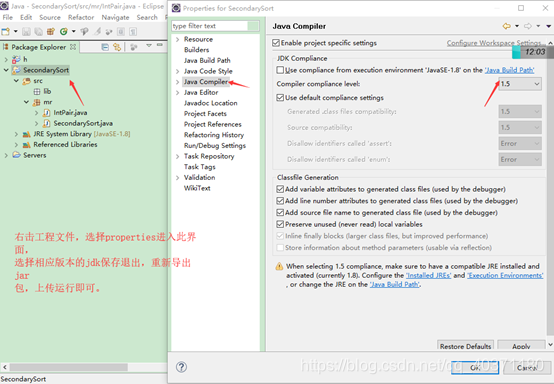
解决方法:修改项目的jdk版本:
7 查看运行结果
(1)在master服务器上查看
[root@master ~]# hdfs dfs -ls /user/mapreduce/secsort/out

查看源文件,进行一个对比。

发现程序运行正确。
(2)登录http://10.30.68.6:8088/cluster查看运行状态

可以看见二次排序程序运行成功,也可以看见其运行时间。
说明:在本实验中的程序并非本人所写,这里只是记录一下实验的步骤以及过程,方便自己和他人使用。
实验时不仅要认真更要注意查看每一步的结果,出错时,要看错误信息,不懂可以上网查看。
