二、MapReduce 第二讲Secondary sort(二次排序)
接下来,我们先讲一下二次排序的原理。
MR默认会对键进行排序,然而有的时候我们也有对值进行排序的需求。满足这种需求一是可以再reduce阶段排序收集过来的values,但是,如果有数量巨大的values可能就导致数据溢出等问题,这就是二次排序应用的场景——————将对值的排序也安排到MR计算过程之中,而不是单独来做。
二次排序就是首先按照第一字段排序,然后再对第一字段相同的行按照第二轴端排序,注意不能破坏第一次排序的结果。
好了 下面话不多少,直接上程序。
原始数据:

demo:二次排序
需求:第一列正序,第二列倒序。
代码如下:
副类
//自定义类
package sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
//自己定义的key类应该实现WritableComparable接口
public class inpart extends Object implements WritableComparable<inpart>{
//定义两个变量
private int frist;
private int second;
/*这里需要注意一下! 这个方法必须添加否则会报错。
public inpart() {
}
*/
public inpart(int frist, int second) {
this.frist = frist;
this.second = second;
}
//反序列化,从流中的二进制转换成InPart
public void readFields(DataInput in) throws IOException {
frist=in.readInt();
second=in.readInt();
}
//序列化,将InPart转化成使用流传送的二进制
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(frist);
out.writeInt(second);
}
public int getFrist() {
return frist;
}
public void setFrist(int frist) {
this.frist = frist;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + frist;
result = prime * result + second;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
inpart other = (inpart) obj;
if (frist != other.frist)
return false;
if (second != other.second)
return false;
return true;
}
public int compareTo(inpart o) {
//第一列正序排列
int cmp = this.frist-o.frist;
if (cmp!=0) {
return cmp;
}
//第二列倒序排列
return o.second-this.second;
}
public String toString() {
return frist+"\t"+second;
}
}
主类:
package sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class sort{
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(sort.class);
job.setMapperClass(MMapper.class);
job.setReducerClass(MReduce.class);
job.setMapOutputKeyClass(inpart.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(inpart.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class MMapper extends Mapper<LongWritable, Text, inpart, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//转换数据类型并切割
String[] line = value.toString().split("\t");
int one = Integer.parseInt(line[0]);
int two = Integer.parseInt(line[1]);
//写入
context.write(new inpart(one,two), NullWritable.get());
}
}
public static class MReduce extends Reducer<inpart, NullWritable, inpart, NullWritable>{
@Override
protected void reduce(inpart key, Iterable<NullWritable> value,
Context context)
throws IOException, InterruptedException {
//这里直接写出
context.write(key, NullWritable.get());
}
}
}
运行结果:
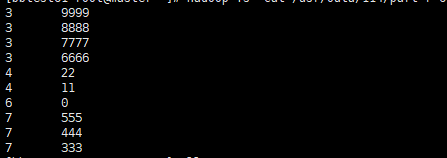
下面附上数据:
7 444
3 9999
7 333
4 22
3 7777
7 555
3 6666
6 0
3 8888
4 11
本次的教程到次结束,有什么不会不懂的地方下方留言。
!!!多多支持博主!!!。

