一、前期工作
1.1 爬取目标
爬取的目标是新浪微博用户的公开基本信息,如用户昵称、头像、用户的关注、粉丝列表以及发布的微博等
1.2 准备工作
代理池、 Cookies 池已经实现并可以正常运行,安装 Scrapy 、PyMongo 库
1.3 爬取思路
首先我们要实现用户的大规模爬取。 这里采用的爬取方式是,以微博的几个大 V 为起始点,爬取他们各内的粉丝和关注列表,然后获取粉丝和关注列表的粉丝和关注列表,以此类推,这样下去就可以实现递归爬取。 如果一个用户与其他用户有社交网络上的关联,那他们的信息就会被爬虫抓取到,这样我们就可以做到对所有用户的爬取 。 通过这种方式,我们可以得到用户的唯一 ID ,再根据 ID 获取每个用户发布的微博即可。
1.4 爬取分析
爬取的站点是https://m.weibo.cn,此站点是微博移动端的站点,找到一个用户的主页面
在页面最上方可以看到她的关注和粉丝数量 。 我们点击关注,进入到她的关注列表
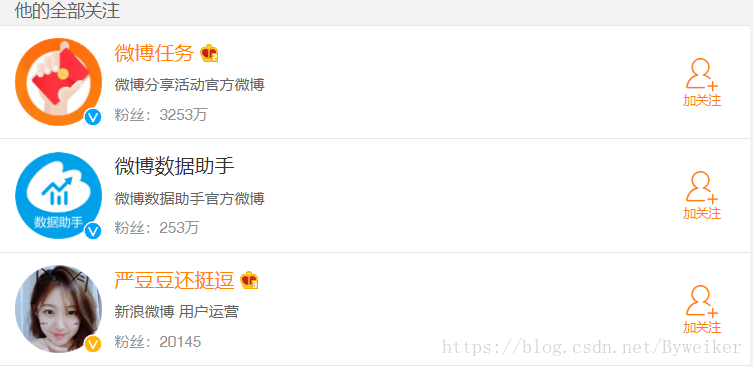
打开开发者工具,切换到XHR 过滤器,一直下拉关注列表,即可看到下方会出现很多人ajax请求,这些请求就是获取关注列表的 Ajax 请求.
- AJAX = 异步 JavaScript 和 XML。
- AJAX 是一种用于创建快速动态网页的技术。
- 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。

打开第一个 Ajax 请求, 将其展开之后 即可看到其关注的用户的基本信息。接下来我们只需要构造这个请求的参数。其中最主要的参数就是 cont ainerid 和 page 。 有了这两个参数,我们同样可以获取请求结果 。 我们可以将接口精简为 :
https://m.weibo.cn/api/container/getIndex?containerid=231051_-_followers_-_2244367010&page=2
这里的 containerid 的前半部分是固定的,后半部分是用户的 id 。 所以这里参数就可以构造出来了,只需要修改 containerid 最后的 id 和 page 参数即可获取分页形式的关注列表信息 。
利用同样的方法,我们也可以分析用户详情的 Ajax 链接、用户微博列表的 Ajax 链接,如下所示:
- #用户详情 API
user_url = 'https://m.weibo.cn/api/container/getIndex?uid={uid}&luicode=10000011&lfid=230413{uid}_-_WEIBO_SECOND_PROFILE_WEIBO&type=uid&value={uid}&containerid=100505{uid}'- #关注列表 API
follow_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_followers_-_{uid}&page={page}'- #粉丝列表 API
fan_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_{uid}&page={page}'- #微博列表API
weibo_url = 'https://m.weibo.cn/api/container/getIndex?uid={uid}&luicode=10000011&lfid=23041{uid}_-_WEIBO_SECOND_PROFILE_WEIBO&type=uid&value={uid}&containerid=100505{uid}'此处的 uid 和 page 分别代表用户 ID 和分页页码。
二、项目实战
2.1 新建项目
接下来,我们用 Scrapy 来实现这个抓取过程。 首先创建一个项目,命令如下所示:scrapy startproject weibo进入项目中,新建一个 Spider,名为 weibocn ,命令如下所示 :scrapy genspider weibocn m.weibo.cn我们首先修改 Spider,配置各个 Ajax 的 URL ,选取几个大 V,将他们的 ID 赋值成一个列表,实现 start_requests()方法, 也就是依次抓取各个大 V 的个人详情,然后用 parse_user()进行解析
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
class WeibocnSpider(scrapy.Spider):
name = 'weibocn'
allowed_domains = ['m.weibo.cn']
user_url ='https://m.weibo.cn/api/container/getIndex?uid={uid}&luicode=10000011&lfid=230413{uid}_-_WEIBO_SECOND_PROFILE_WEIBO&type=uid&value={uid}&containerid=100505{uid}'
follow_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_followers_-_{uid}&page={page}'
fan_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_{uid}&page={page}'
weibo_url = 'https://m.weibo.cn/api/container/getIndex?uid={uid}&luicode=10000011&lfid=23041{uid}_-_WEIBO_SECOND_PROFILE_WEIBO&type=uid&value={uid}&containerid=100505{uid}'
start_users = ['3217179555', '1742566624', '2282991915', '1288739185', '3952070245', '5878659096']
def start_requests(self):
for uid in self.start_users:
yield Request(self.user_url.format(uid=uid), callback=self.parse_user)
2.2 创建Item
解析用户的基本信息并生成 Item。 这里我们先定义几个 Item ,如用户、用户关系、微博Item ,如下所示:
class UserItem(Item):
collection = 'users'
id = Field()
name = Field()
avatar = Field()
cover = Field()
gender = Field()
description = Field()
fans_count = Field()
follows_count = Field()
weibos_count = Field()
verified = Field()
verified_reason = Field()
verified_type = Field()
follows = Field()
fans = Field()
crawled_at = Field()
class UserRelationItem(Item):
collection = 'users'
id = Field()
follows = Field()
fans = Field()
class WeiboItem(Item):
collection = 'weibos'
id = Field()
attitudes_count = Field()
comments_count = Field()
reposts_count = Field()
picture = Field()
pictures = Field()
source = Field()
text = Field()
raw_text = Field()
thumbnail = Field()
user = Field()
created_at = Field()
crawled_at = Field()这里定义了 collection 字段,指明保存的 Collection 的名称。 用户的关注和粉丝列表直接定义为一个单独的 UserRelationitem ,其中 id 就是用户的 ID, follows 就是用户关注列表, fans 是粉丝列表
2.3 提取数据
开始解析用户的基本信息,实现 parse_user ()方法,如下所示:
def parse_user(self, response):
"""
解析用户信息
:param response: Response对象
"""
self.logger.debug(response)
result = json.loads(response.text)
if result.get('data').get('userInfo'):
user_info = result.get('data').get('userInfo')
user_item = UserItem()
field_map = {
'id': 'id', 'name': 'screen_name', 'avatar': 'profile_image_url', 'cover': 'cover_image_phone',
'gender': 'gender', 'description': 'description', 'fans_count': 'followers_count',
'follows_count': 'follow_count', 'weibos_count': 'statuses_count', 'verified': 'verified',
'verified_reason': 'verified_reason', 'verified_type': 'verified_type'
}
for field, attr in field_map.items():
user_item[field] = user_info.get(attr)
yield user_item
# 关注
uid = user_info.get('id')
yield Request(self.follow_url.format(uid=uid, page=1), callback=self.parse_follows,meta={'page': 1, 'uid': uid})
# 粉丝
yield Request(self.fan_url.format(uid=uid, page=1), callback=self.parse_fans,meta={'page': 1, 'uid': uid})
# 微博
yield Request(self.weibo_url.format(uid=uid, page=1), callback=self.parse_weibos,meta={'page': 1, 'uid': uid})在这里一共完成了两个操作:
- 解析 JSON 提取用户信息并生成 UserItem 返回 。 我们并没有采用常规的逐个赋值的方法,而是定义了一个字段映射关系 。 我们定义的字段名称可能和 JSON 中用户的字段名称不同,所以在这里定义成一个字典,然后遍历字典的每个字段实现逐个字段的赋值。
- 构造用户的关注、粉丝、微博的第一页的链接,井生成 Request ,这里需要的参数只有用户的ID 。 另外,初始分页页码直接设置为 l 即可。
接下来,我们还需要保存用户的关注和粉丝列表。以关注列表为例,其解析方法为 parse_follows() ,实现如下所示:
def parse_follows(self, response):
"""
解析用户关注
:param response: Response对象
"""
result = json.loads(response.text)
if result.get('ok') and result.get('data').get('cards') and len(result.get('data').get('cards')) and result.get('data').get('cards')[-1].get('card_group'):
# 解析用户
follows = result.get('data').get('cards')[-1].get('card_group')
for follow in follows:
if follow.get('user'):
uid = follow.get('user').get('id')
yield Request(self.user_url.format(uid=uid), callback=self.parse_user)
uid = response.meta.get('uid')
# 关注列表
user_relation_item = UserRelationItem()
follows = [{'id': follow.get('user').get('id'), 'name': follow.get('user').get('screen_name')} for follow in follows]
user_relation_item['id'] = uid
user_relation_item['follows'] = follows
user_relation_item['fans'] = []
yield user_relation_item
# 下一页关注
page = response.meta.get('page') + 1
yield Request(self.follow_url.format(uid=uid, page=page),callback=self.parse_follows, meta={'page': page, 'uid': uid})在这个方法里面做了如下三件事:
- 解析关注列表中的每个用户信息并发起新的解析请求。我们首先解析关注列表的信息,得到用户的 ID ,然后再利用 user_url 构造访问用户详情的 Request ,回调就是刚才所定义的parse_user()方法 。
- 提取用户关注列表内的关键信息并生成 UserRelationitem 。 id 字段直接设置成用户的 ID,JSON 返回数据中的用户信息有很多冗余字段 。 在这里我们只提取了关注用户的 lD 和用户名,然后把它们赋值给 follows 字段, fans 字段设置成空列表。 这样我们就建立了一个存有用户 ID 和用户部分关注列表的 UserRelationitem ,之后合并且保存具有同 一个 lD 的UserRelationit凹的关注和粉丝列表 。
- 提取下一页关注。 只需要将此请求的分页页码加 l 即可 。 分页页码通过 Request 的 meta 属性进行传递, Response 的meta 来接收。 这样我们构造并返回下一页的关注列表的 Request。
抓取粉丝列表的原理和抓取关注列表原理相同
来抓取用户的微博信息;
def parse_weibos(self, response):
"""
解析微博列表
:param response: Response对象
"""
result = json.loads(response.text)
if result.get('ok') and result.get('data').get('cards'):
weibos = result.get('data').get('cards')
for weibo in weibos:
mblog = weibo.get('mblog')
if mblog:
weibo_item = WeiboItem()
field_map = {
'id': 'id', 'attitudes_count': 'attitudes_count', 'comments_count': 'comments_count',
'reposts_count': 'reposts_count', 'picture': 'original_pic', 'pictures': 'pics',
'created_at': 'created_at', 'source': 'source', 'text': 'text', 'raw_text': 'raw_text',
'thumbnail': 'thumbnail_pic',
}
for field, attr in field_map.items():
weibo_item[field] = mblog.get(attr)
weibo_item['user'] = response.meta.get('uid')
yield weibo_item
# 下一页微博
uid = response.meta.get('uid')
page = response.meta.get('page') + 1
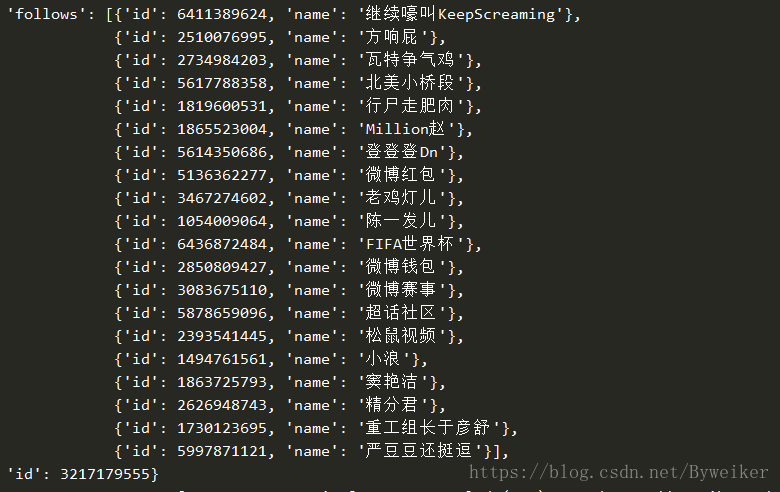
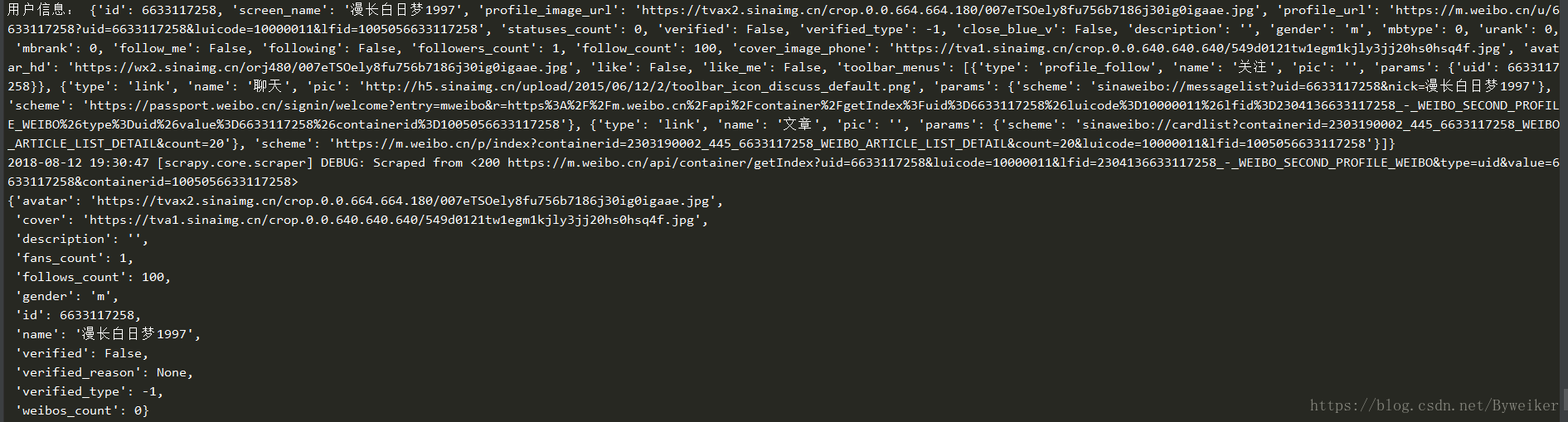
yield Request(self.weibo_url.format(uid=uid, page=page), callback=self.parse_weibos,meta={'uid': uid, 'page': page})信息抓取结果:
用户信息

粉丝信息:

关注信息:
抓取列表外用户信息:
2.4 数据清洗

有些微博的时间可能不是标准的时间,比如它可能显示为刚刚、几分钟前、几小时前、昨天等。这里我们需要统一转化这些时间,实现一个 parse_time ()方法,如下所示:
def parse_time(self, date):
if re.match('刚刚', date):
date = time.strftime('%Y-%m-%d %H:%M', time.localtime(time.time()))
if re.match('\d+分钟前', date):
minute = re.match('(\d+)', date).group(1)
date = time.strftime('%Y-%m-%d %H:%M', time.localtime(time.time() - float(minute) * 60))
if re.match('\d+小时前', date):
hour = re.match('(\d+)', date).group(1)
date = time.strftime('%Y-%m-%d %H:%M', time.localtime(time.time() - float(hour) * 60 * 60))
if re.match('昨天.*', date):
date = re.match('昨天(.*)', date).group(1).strip()
date = time.strftime('%Y-%m-%d', time.localtime() - 24 * 60 * 60) + ' ' + date
if re.match('\d{2}-\d{2}', date):
date = time.strftime('%Y-', time.localtime()) + date + ' 00:00'
return date用正则来提取一些关键数字,用 time 库来实现标准时间的转换。
上面数据清洗的工作主要是对时间做清洗。
2.5数据存储
数据清洗完毕之后,我们就要将数据保存到 MongoDB 数据库 。 我们在这里实现 MongoPipeline类,如下所示:
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
self.db[UserItem.collection].create_index([('id', pymongo.ASCENDING)])
self.db[WeiboItem.collection].create_index([('id', pymongo.ASCENDING)])
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
if isinstance(item, UserItem) or isinstance(item, WeiboItem):
self.db[item.collection].update({'id': item.get('id')}, {'$set': item}, True)
if isinstance(item, UserRelationItem):
self.db[item.collection].update(
{'id': item.get('id')},
{'$addToSet':
{
'follows': {'$each': item['follows']},
'fans': {'$each': item['fans']}
}
}, True)
return item
2.6 Cookies池对接
在这里实现一个 Middleware,为每个 Request 添加随机的 Cookies
2.7代理池对接
启动redis提供数据存储
运行代理池程序
获取代理IP:

在微博抓取中的程序中启动代理ip服务
555代表优先级,设置完毕
文章转载需要授权,版权所有,源代码关注微信公众号:七彩树枝
回复:新浪爬虫
获取
