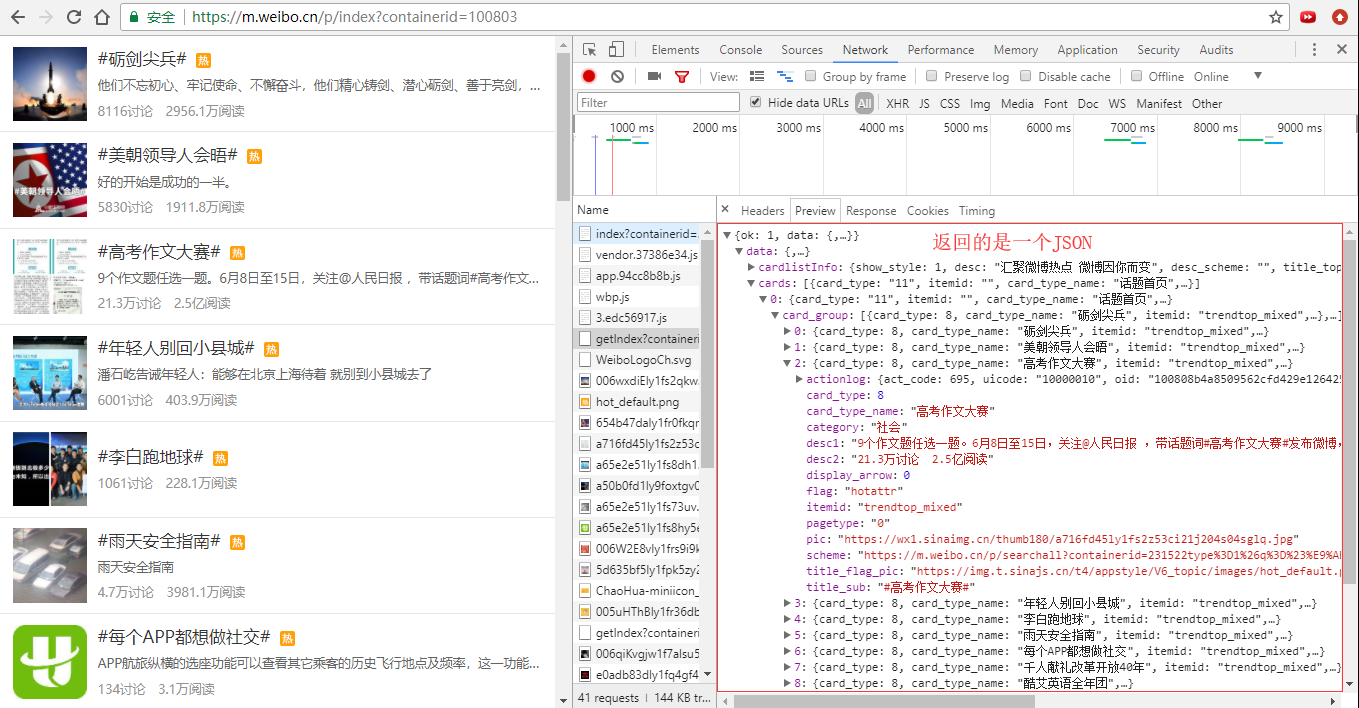
1.先找到数据所在的url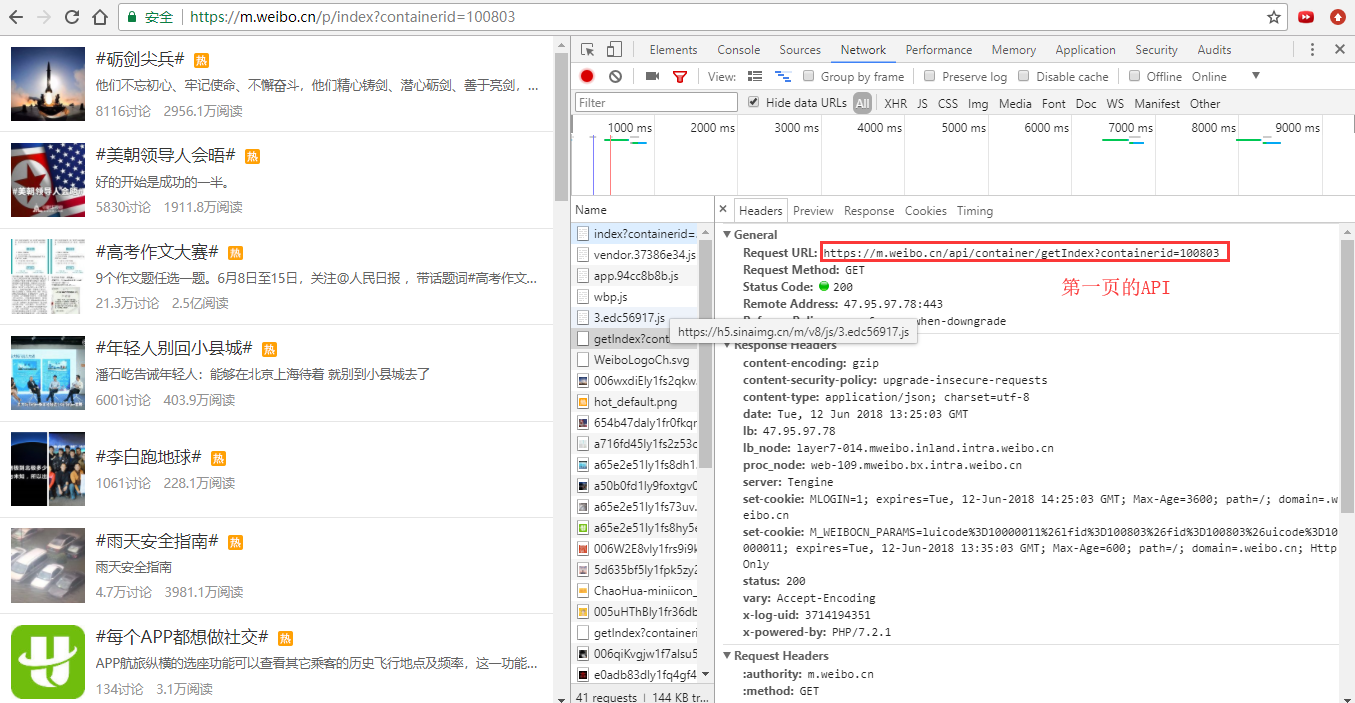
 2.写代码获取数据,并保存
2.写代码获取数据,并保存
import requests
import time
import sys
import os
import xlwt, xlrd
import xlutils.copy
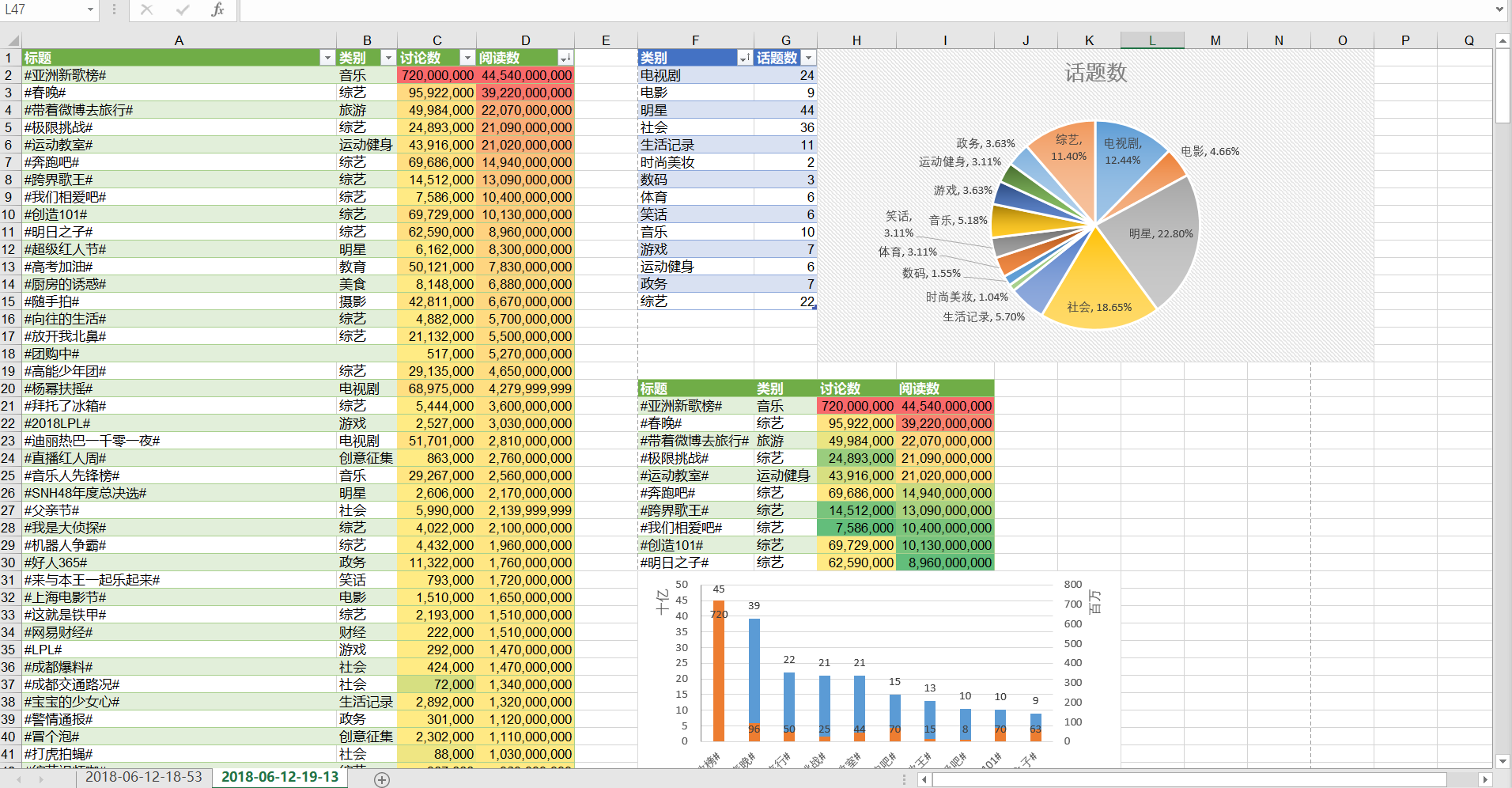
#传入要爬取的页数page,将获取的热门话题名称、类别、讨论数、阅读数存到二维列表中
def get_hot_topic(page):
topic_list = []
session = requests.session()
for i in range(page):
print("\n*****正在获取第{}页*****".format(i + 1))
if i == 0:
the_url = "https://m.weibo.cn/api/container/getIndex?containerid=100803"
if i == 1:
the_url = "https://m.weibo.cn/api/container/getIndex?containerid=100803&since_id=%7B%22page%22:2,%22next_since_id%22:6,%22recommend_since_id%22:[%22%22,%221.8060920078958E15%22,%221.8060920009434E15%22,0]%7D"
else:
the_url = "https://m.weibo.cn/api/container/getIndex?containerid=100803&since_id=%7B%22page%22:{},%22next_since_id%22:{},%22recommend_since_id%22:[%22%22,%221.8060912084255E14%22,%221.8060920000515E15%22,0]%7D".format(i+1,6 + 14*(i-2))
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36",
'Referer':'https://m.weibo.cn/p/index?containerid=100803',
'Host':'m.weibo.cn',
}
try:
r = session.get(the_url, headers = header)
res = r.json()
except requests.exceptions.ConnectionError:
print("!!!网络连接出错,请检查网络!!!")
time.sleep(2)
for cards in res.get("data").get("cards"):
#try:
if cards.get("card_group") is None:
continue
for card in cards.get("card_group"):
#print("***", card.get("title_sub"), card.get("category"), card.get("desc2"))
title = card.get("title_sub")
category = card.get("category")
desc2 = card.get("desc2")
if "超级话题" in desc2:
print("超级话题:", end = "")
scheme = card.get("scheme")
topic_id = scheme[scheme.index("=") + 1 : scheme.index("=") + 7]
topic_url = "https://m.weibo.cn/api/container/getIndex?containerid={}type%".format(topic_id)\
+ "3D1%26q%3D%23%E7%8E%8B%E4%BF%8A%E5%87%AF%E4%B8%AD%E9%A4%90%E5%8E%"\
+ "85%E7%AC%AC%E4%BA%8C%E5%AD%A3%23%26t%3D10&luicode=10000011&lfid="\
+ "100803&page_type=searchall"
r2 = session.get(topic_url)
res2 = r2.json()
desc2 = res2.get("data").get("cardlistInfo").get("cardlist_head_cards")[0].get("head_data").get("midtext").split()
desc2.reverse()
desc2 = " ".join(desc2)
print(title, category, desc2.split())
cv = []
for n in desc2.split():
if "万" in n:
for ch in n:
if u'\u4e00' <= ch <= u'\u9fff': #去除中文
n = n.replace(ch, "")
n = float(n) * 10000
elif "亿" in n:
for ch in n:
if u'\u4e00' <= ch <= u'\u9fff': #去除中文
n = n.replace(ch, "")
n = float(n) * 100000000
else:
for ch in n:
if u'\u4e00' <= ch <= u'\u9fff': #去除中文
n = n.replace(ch, "")
cv.append(int(n))
try:
topic_list.append([title, category, cv[0], cv[1]])
except:
continue
#except:
#continue
time.sleep(2)
print(len(topic_list))
return topic_list
#将列表数据写入Excel文件中
def write_excel(topic_list):
root = os.getcwd()
local_t = time.strftime("%Y-%m-%d-%H-%M", time.localtime())
path = root + "\\weibo_topic.xls"
if os.path.exists(path): #如果存在该文件,添加数据
workbook = xlrd.open_workbook(path) #读取excel文件
sheet_names = workbook.sheet_names() #读取所有sheet的名称
wb = xlutils.copy.copy(workbook)
if local_t not in sheet_names:
sheet1 = wb.add_sheet(local_t, cell_overwrite_ok = False) #添加表
sheet1.write(0, 0, label = "标题")
sheet1.write(0, 1, label = "类别")
sheet1.write(0, 2, label = "讨论数")
sheet1.write(0, 3, label = "阅读数")
for row in range(len(topic_list)):
for col in range(len(topic_list[row])):
sheet1.write(row + 1, col, topic_list[row][col])
wb.save(path)
print("文件更新成功:", path)
else: #如果不存在xls文件则创建并添加数据
workbook = xlwt.Workbook()
sheet1 = workbook.add_sheet(local_t, cell_overwrite_ok = True) #添加sheet
sheet1.write(0, 0, label = "标题")
sheet1.write(0, 1, label = "类别")
sheet1.write(0, 2, label = "讨论数")
sheet1.write(0, 3, label = "阅读数")
for row in range(len(topic_list)):
for col in range(len(topic_list[row])):
sheet1.write(row + 1, col, topic_list[row][col])
workbook.save(path)
print("文件保存成功:", path)
def main():
topic_list = get_hot_topic(40)
write_excel(topic_list)
if __name__ == "__main__":
main()
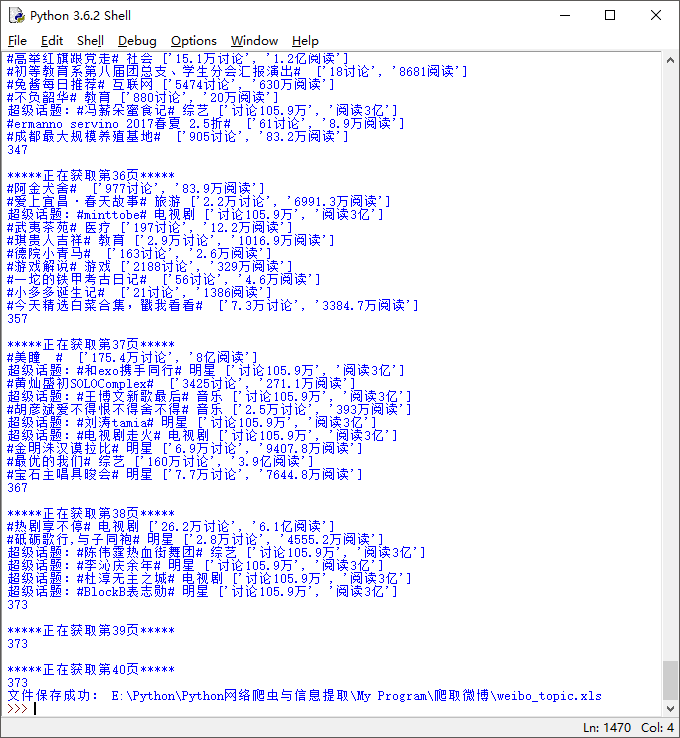
3.运行结果
4.数据简单处理