日期:2019年12月29日
作者:Commas
注释:编码这件小事,其实就是这么回事……
一、什么是编码?
编码在我们生活中无处不在,暂且我们先不讨论计算机编码,举几个生活中的例子:
身份证号码:前两位代表省、自治区、直辖市,比如说“44…”,代表广东省,而“43…”,代表湖南省;车牌号:第一个汉字代表车户口所在省的简称,比如“粤…”,代表广东省;电话区号:前三位是电话区号,比如说“020-…”,代表广州,而“0760-…”,代表中山;学号:前四位代表学生的届数,比如说“2019…”,代表2019届学生;摩斯密码:用特殊符号代表想要表达的含义,比如说用“… — …”来代表“SOS”,向他人发送求救信号;
从以上的例子当中,我们不难发现,编码的本质就是,出于某种原因,用一种东西去表达另外一种东西,且这种表达的关系都是一一对应的,有点类似于字典,我们只需要对应着规则去找就可以得到我们想要的答案。同时也正是因为一一对应的关系是确定的,所以才不会说身份证号码前两位44即代表广东省,又代表湖南省,身份证44开头的人即是广东人,又是湖南人这样的乌龙,从而出现了所谓的“乱码”。
那么问题来了,计算机编码是怎么回事呢?其实也就那么回事,用大白话讲就是用一种东西表达另外一种东西,比方说我们可以用数字5来表示“我”,用数字2来表示“爱”,用数字0来表示你,那么520就是“我爱你”,并且我也给这个编码取个响当当的名字叫做“CSCII”编码(和“ASCII”码有点类似,Chinese Standard Code for Information Interchange),大家都遵循这个CSCII码,就可以表达想要表达的内容了。那么乱码怎么来?无非是你不仅用了我的CSCII码,还用了美国银制定的ASCII码,所以明明在情人节那天想给女朋友一个浪漫,发送了一个520,等待对象接收“我爱你”的表白,而对象接收的信息却是“ENQ (enquiry) STX (start of text) NUL(null)”,什么鬼?不多说,直接给你say goodbye。
二、计算机编码原来如此
众所周知,计算机实际上只认识二进制的数字,也就是说在计算机中,无论是做什么计算,操作什么字符串等等,本质就是在操作一群人类难以读懂的一串二进制数字的排列组合(由0和1组成,逢二进一的一种计算规则)。
那么计算机为什么只能识别0和1呢?那是因为现代计算机都是通用电进行工作的,当电流走过设备的时候必然会产生电压。所以聪明的前辈们就人为的设定了规则,取一个电压值,比这个值大的叫做高电位,用数字1表示;比这个值小的叫做低电位,用数字0表示。基于这个原理,计算机就可以识别0和1,我们就可以利用这种关系,进行我们想要的操作。
这些二进制编码数字即是计算机编码。
话说我也不记得什么时候看到过一个科普,也没有找到相关文件,大致上是说以前还真的存在过十进制的计算机,但是逻辑非常非常的复杂,从而放弃了我们生活中使用的十进制,转而采用了二进制。二进制的好处有挺多,如下:
- 二进制技术实现非常简单,采用高低电位即可辨别;
- 二进制的0和1可以完美的表示真假,0就是假,1就是真,完美的找不到瑕疵;
- 进制之间的转换也比较容易,所以我们可以利用进制转换,将我们生活中的数字转成计算机识别的二进制,从而借助计算机计算,然后再把结果转换十进制返回给我们。
| 十进制 | 二进制 |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 9 | 1001 |
| 100 | 1100100 |
三、字符编码和字符集不过如此
数字可以通过进制转换到达我们想要的效果,但是字符呢?该如何用计算机编码来实现呢?聪明的前辈们,于是想出了赋予每个特定的编码串(二进制)一个特定的含义,每个编码串的含义互不重复,比方说,我们用0100 0001 来表示大写的A,用0100 0010 来表示大写的B,再通过一一映射的关系,在屏幕上通过点阵的方式显示出我们现在所看到的A、B。前辈们通过这种方式,将大小写英文字母、阿拉伯数字和一些字符都做了“翻译”,就形成了一个字符集——ASCII码,如下是ASCII码表的一部分:
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|---|---|---|
| 0100 0001 | 65 | 41 | A |
| 0100 0010 | 66 | 42 | B |
| 0100 0011 | 67 | 43 | C |
| 0100 0100 | 68 | 44 | D |
| 0100 0101 | 69 | 45 | E |
| 0100 0110 | 70 | 46 | F |
| 0100 0111 | 71 | 47 | G |
为什么这些二进制编码串是8位,不是7位,也不是9位呢?是因为计算机是美国银发明的,他们当时需要的字符也就127个,也就是27(=128)就足够了,本来应该是采用7位,但是考虑到以后还可能需要扩展,小脑瓜子灵光一动,多准备一位(即28),最高位填先不使用,填写0就可以了。总是感觉缺点什么,不完美,缺啥呢?单位,对,就是缺少一个能够度量“数据大小”(二进制编码串)的单位?聪明的前辈们,就将表示信息的最小单位设置为bit,是binary digit的缩写,那位8位就是8bit。在当时看来,既然所有的字符都用8bit就可以表示出来,逢8位断一句,如“0100 0001 0100 0010 0100 0011”这个二进制编码串表示字符“ABC”,断句断了三次,总共为24bit。这个数字少,还是比较好数的,倘若我们来一个极限思想,整一个屏幕的01,那得数到何年何月呢?既然24bit断句3次,表示3个字符,那为何不整一个大一点的单位呢?于是乎字节byte就这么给整出来了,从而就有了这么一个经典的换算公式1 byte = 8 bit。字节的出现,更加丰富了我们对字符大小的表示,在ASCII码中,可以这么说,一个字符可以用一个字节表示,字节也成为了计算机最小的存储单位,奠定了现代字符编码的基础。
知识加油站:
字符集:许多字符与二进制编码串映射关系的集合;
bit:表示信息的最小单位,也就是实际存在硬盘中的实际数据(二进制编码串)的大小;
byte:表示计算机最小的储存单位,目前来说,是没有半个字节的,因为纵观第一个字符集ASCII码的出现,到现在的众多字符集形成,一个字符的至少得一个字节表示;
编码:字符 → 二进制编码串,如 A 翻译成机器识别的 0100 0001;
解码:二进制编码串 → 字符,如 0100 0001 翻译成人类易读的 A;
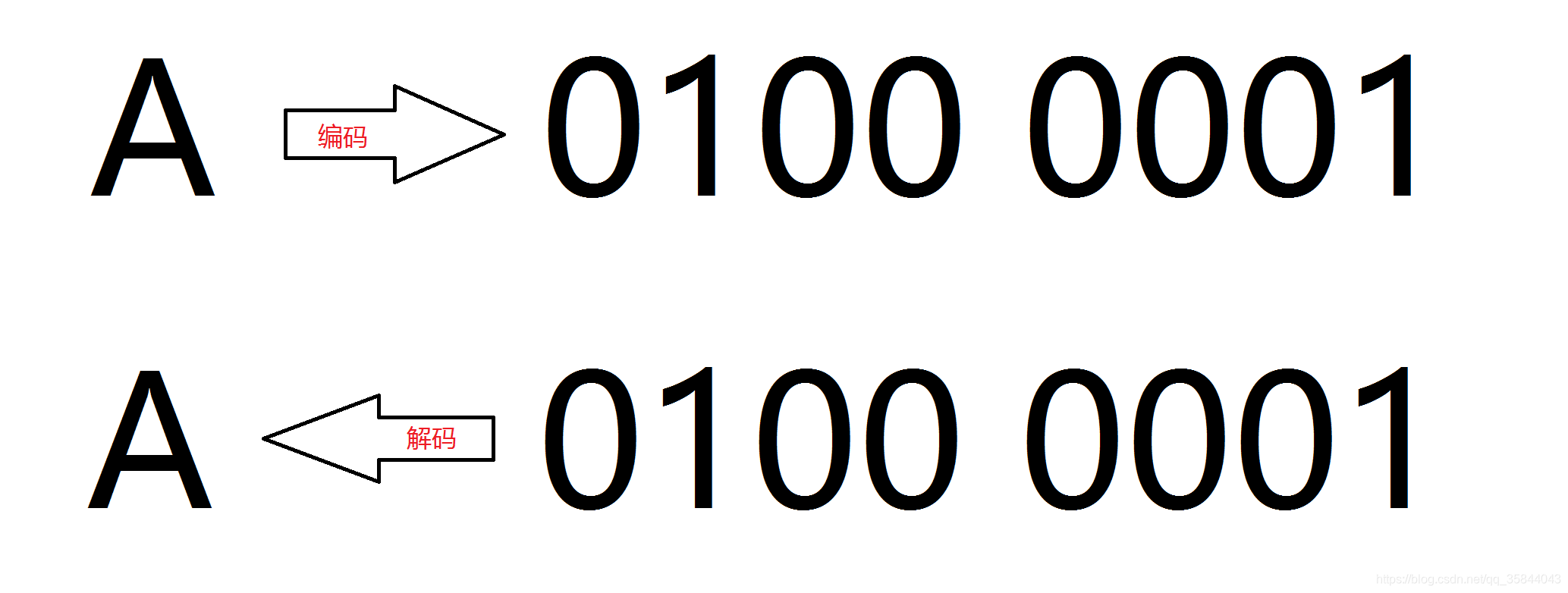
四、字符编码大爆炸
当计算机走出了美国的大门,走向了全世界的时候,ASCII码字符集已经无法满足用户的需求了,纵使扩展的ASCII码字符集也是无法满足的。每个国家都迫切需要一套字符集和字符编码来表示自己国家或地区的语言以及符号,于是就出现了:
- 中国:GB2312、BIG5、GBK、GB18030
- 日本:Shift_JIS
- 韩国:Euc-kr
百花齐放自然是好事,极大丰富了计算机字符编码,使得各国可以幸福快乐的表示自己国家或地区的语言或符号,当人们处于甜蜜期时,突然来了这么一个拦路虎。拿我们的GB2312来举例子吧,当我们中英文混用的时候,如“您好,我的中文名叫逗号先生,我的英文名叫Commas”,计算机就不知所措,整了一堆乱码出来。这个时候,我们的GB2312除了支持我们的中文之外,还应该支持英文。但是GB2312是通过2个字节表示一个中文的(因为中国文字多如牛毛,用一个字节28=256根本都不够塞牙缝,所以中文采用2个字节,最多可容纳2^16=65536个字符),如果英文也采用2个字节表示一个英文的话,就相当坑爹了。以前1G的单字节表示的英文文档,用双字节表示的话,就会变成2G文档,这得多费内存空间,有钱也不是这么造的吧!聪明的中国人咋会被这点小事难住,于是乎采用了“高字节识别法”(即首位为128的字节被称为高字节,遇到高字节就连续对两位,表示一个中文;遇到低字节,就读一个字节,即和原ASCII码一致),这样既兼容了ASCII码,又解决了乱码的问题。1995年,专家们又升级了GB2312,加入了更多字符,藏语、维吾尔语、日语、韩语、蒙古语等等,这些就是我们所熟知的一个GBK字符集。
到目前为止,我们的windows电脑的中文版本的编码还是GBK。
四、字符编码大一统
百花齐放的编码,因为各国各地区标准不一致,不可避免会有所冲突,如果多国语言混用,那么势必会出现乱码,这么一来将极大阻碍了不同国家的信息传递,这是我们大家都不希望看到的。比较爱看《三国》,也借用这么一句经典的句子:“天下大势,分久必合”吧,于是联合国为了解决这个混乱的局面,就整出了一个Unicode标准,采用2-4个字节表示字符(为了简化学习,可以这么理解先,后面再参考修正①) ,将支持全球所有语言,目前还在不断扩张中。同时为了有利于推广,支持各种语言编码的自由转换。
乱码问题解决了,但是新问题又出现了。假使使用Unicode编码,那么会比使用ASCII编码保存英文文件整整多出一倍的存储空间的需求,这不利于存储与网络传输。为了解决这个问题,出现了Unicode Transformation Format,即UTF,于是乎,出现了以下三个版本:
| UTF版本 | 说明 |
|---|---|
| UTF-8 | 使用1-4个字节表示所有字符,优先使用1个字节,无法满足时再逐渐增加 |
| UTF-16 | 使用2、4个字节表示所有字符,优先使用2个字节,无法满足时使用4个字节 |
| UTF-32 | 使用4个字节表示所有字符 |
其中,UTF-8被广泛的使用,原因是因为完全兼容ASCII码,并且更利于储存和网络传输。
修正①:Unicode既然是为了整合全世界所有语言文字而诞生的,那么任何文字在Unicode中都会有一个对应的值,这个值称为代码点(code point), 用一句大白话讲,就是给所有字符都取了一个ID值(即代码点),那么你们只要对应我这个ID值就可以找到对应的字符。起初是用2个字节来表示代码点(称为UCS-2),后面为了能够表达更多的文字(字符),前辈们又提出了UCS-4,即用4个字节表示代码点,值得指出的是,这些仅仅只是规定了代码点与字符之间的对应关系,并没有规定代码点在计算机中是如何存储的,而UTF规定存储方式,本质上就是将“代码点”通过一定的计算规则与“二进制编码串”建立关联,进行互相转换,这才完美解决了乱码与存储的两大问题。
知识加油站:
Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。
本文参考:
1、https://baike.baidu.com/item/%E6%AF%94%E7%89%B9%28bit%29/7675114?fr=aladdin
2、https://baike.baidu.com/item/ASCII/309296?fr=aladdin
3、https://baike.baidu.com/item/%E5%AD%97%E7%AC%A6%E9%9B%86/946585
4、https://baike.baidu.com/item/%E6%89%A9%E5%B1%95ASCII/9882009?fr=aladdin
版权声明:本文为博主原创文章,如需转载,请给出:
原文链接:https://blog.csdn.net/qq_35844043/article/details/103713522
