上一篇文章中,我们准备好了深度学习所需的数据。为了实现分辨猫狗的目的,我们决定使用卷积神经网络(Convolutional Neural Networks,CNN),目前它在图像识别方面十分受欢迎,那么到底什么是卷积神经网络呢?我们应该怎么去理解它?
1 CNN 基本结构
一个基本的 CNN 结构为:输入层 -> 卷积层 -> 池化层 -> 卷积层 -> 池化层 -> 全连接层 -> 输出层
2 卷积
什么是卷积
话不多说,先上张图。
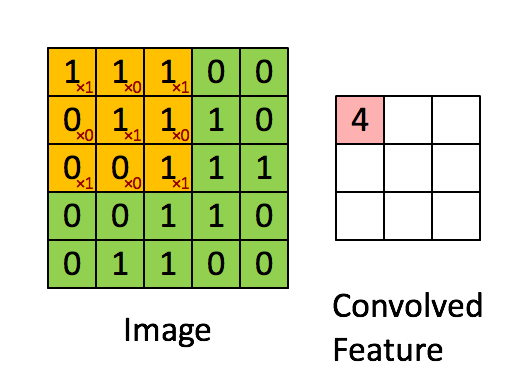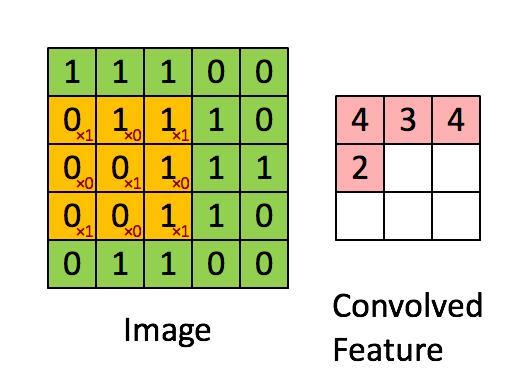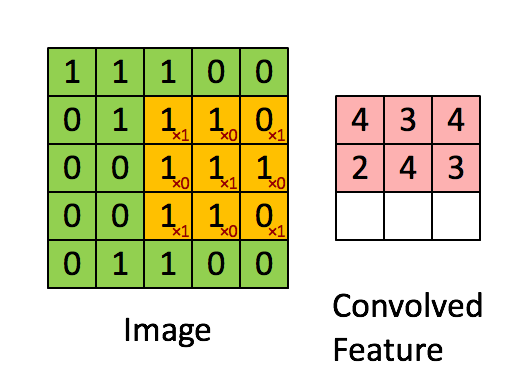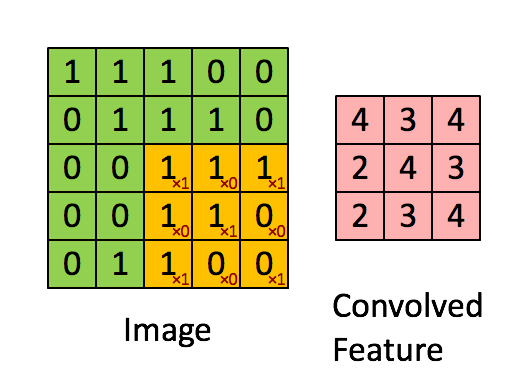
左图中
的黄色区域即 “卷积核”(Kernel),或者称之为卷积模板。其中右下角的数字可以理解为权值,卷积核每移动一步,就会计算权值和当前重叠区域的对应像素值的乘积之和,来作为下一层中的新值。由于卷积被认为是提取局部特征的过程,所以卷积后的输出又叫特征图。
“卷积”,是对英文的直译,对于上面这种操作,我觉得叫 “加权叠加” 更好理解一点,不过叫卷有叫卷的道理,不必纠结这些。
想要深入理解的话需要从数学和物理(信号学)两个方面着手,对于以深度学习应用为目的的我们,目前了解到这个程度就可以了。
为什么要卷积?
在讲这个问题之前,我们需要认识到机器学习更偏向于“工程”,有时候我们并不需要太严密的论证,就可以使用一些“感觉上”有效的工具。卷积和池化均属于这种工具,虽然目前还没有彻底搞清楚为什么使用这两种工具会得到不错的结果,但事实是确实这样做结果不错。
提取图像特征
上面已经说过了,卷积可以提取图像的局部特征。通常人眼识别图像也不是以孤立的像素为单位的,所以卷积被认为是合理的。然鹅,通过卷积提取出的特征好像跟我们理解的特征不太一样,或者人根本不认为那是特征,但事实证明,让机器自己去做往往比我们使用特征工程的结果要好。这正是卷积神经网络能够逆袭 SVM 的重要原因之一。
降低计算量
相较全连接层,卷积层只需要跟与卷积核相同大小的输入层神经元连接。
比如我们有一个 的图像,中间一个隐含层有 个神经元,如果为全连接层,则需要计算 个权值,共 1000100 个(+1 为 bias),而如果使用大小为 ,步长为 1 的卷积层,则需要计算的权值个数为:
计算量已经大大减少了。而如果我们只使用一种卷积核,那么实际上卷积层每个神经元连接的 的区域的权值都是相同的,也就是我们最终只需要得到 个权值即可。

P.S. 由于图像的特征有很多种类,使用一种卷积核只能提取一部分的特征,所以我们通常使用多个卷积核,也就是会得到多种特征图。注意这些卷积核正是神经网络学习得到的成果,我们只是简单地设定了卷积核的个数。
3 池化
什么是池化
看图。
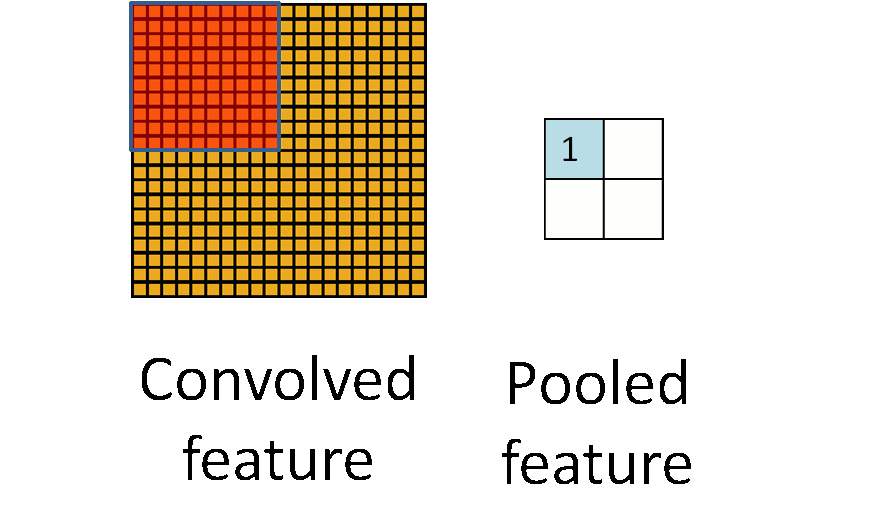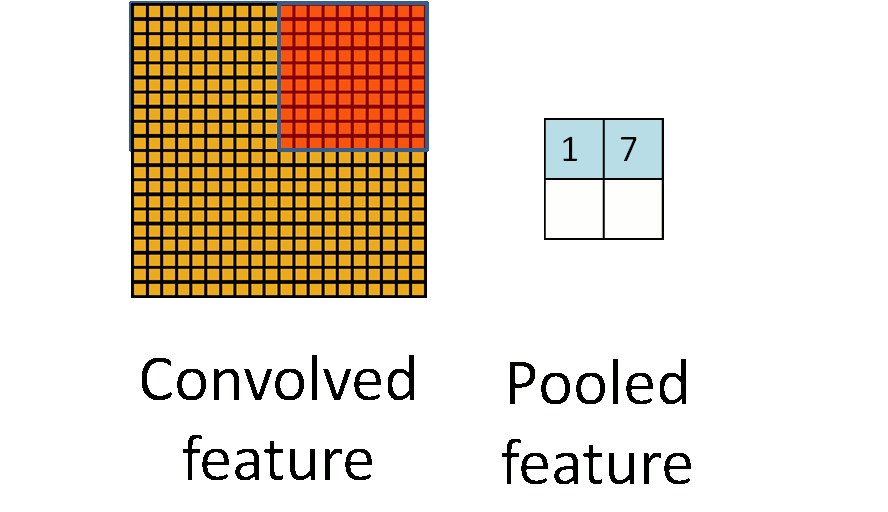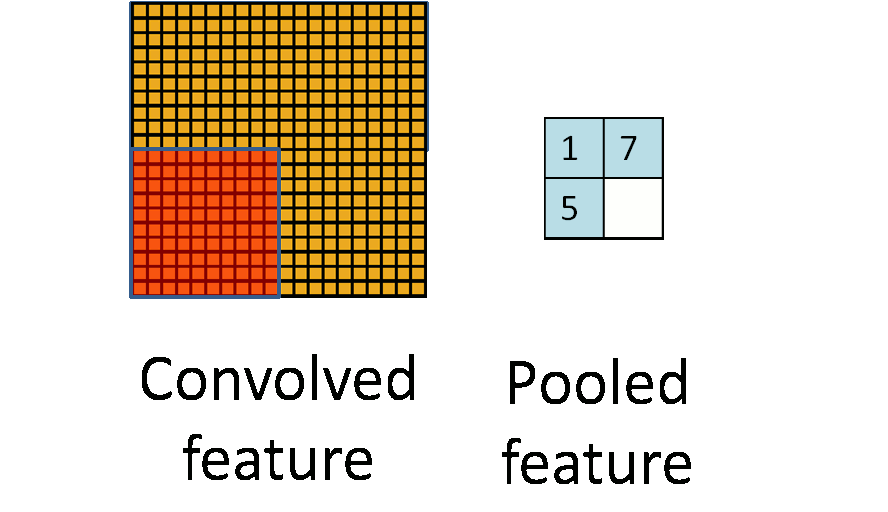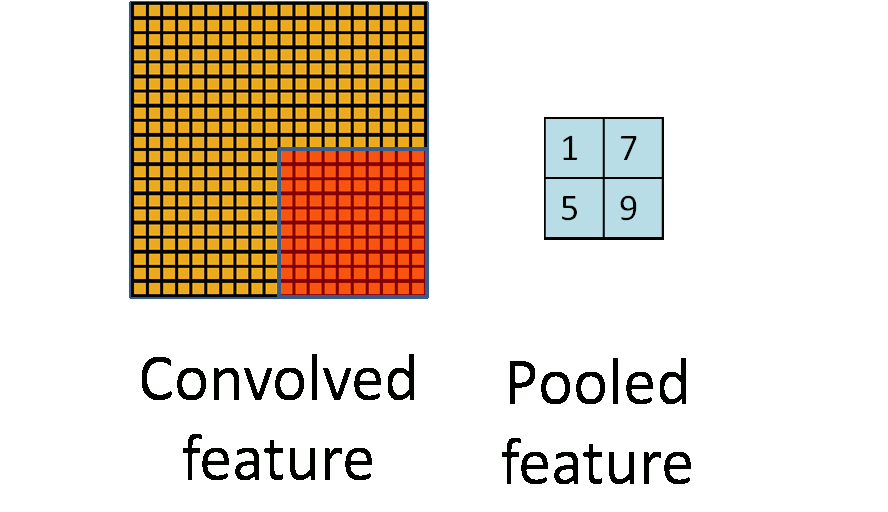
池化是一种下采样,也就是在原图上开窗,并把整个窗口作为一个新的像素,可以采用原图窗口中的最大值作为新像素的值(称为最大池化策略),或是其它的采样方法(如均值池化策略)。
为什么要池化?
降低计算量与防止过拟合
经过池化层后下一层需要计算的参数明显变少了。但其实多加了这么一层,总的计算量不一定就减小了,这只是相较全连接层而言。更重要的作用是卷积层输出的特征经过池化之后维度降低了,可以防止过拟合(即防止少量像素就会影响识别结果)。
使模型对小的变化不敏感
由于池化可以看作是提取区域的特征,这个区域发生一些微小的平移和变形并不会太影响池化的结果,所以有人认为交叉使用池化层可以降低模型对这些微小变化的敏感性。当然这只是一种“看上去合理”的说法。
4 全连接层
在经过重复的卷积、池化过程后,我们又加入了一个全连接层。至于为什么要加,仍然是解释不清楚的,大概是和一般的神经网络类比,像是一种经验上的迁移。当然也有很多正儿八经的解释,可以在知乎上搜一搜。
关于卷积神经网络,要说的就是这么多,深度学习是一个不断发展的知识体系,我们要做的就是在合理推测与大胆尝试中不断向前。
