RASA_NLU调研报告
一、rasa_nlu模块
1、rasa简介
Rasa是一个开源机器学习框架,用于构建上下文AI助手和聊天机器人。
Rasa有两个主要模块:
Rasa NLU :用于理解用户消息,包括意图识别和实体识别,它会把用户的输入转换为结构化的数据。
Rasa Core:是一个对话管理平台,用于举行对话和决定下一步做什么。
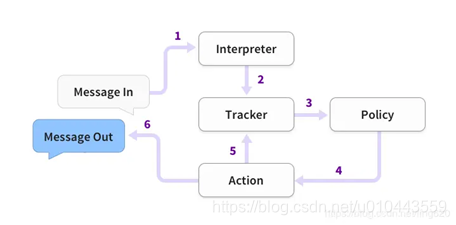
Rasam框架的基本流程:
2、rasa_nlu简介
Rasa NLU曾经是一个独立的库,但它现在是Rasa框架的一部分。
Rasa_NLU是一个开源的、可本地部署并配套有语料标注工具RASA NLU Trainer。其本身可支持任何语言,中文因其特殊性需要加入特定的tokenizer作为整个流程的一部分。
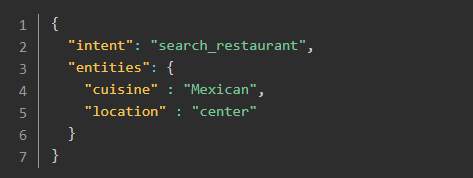
Rasa NLU 用于聊天机器人中的意图识别和实体提取。例如,下面句子:
"I am looking for a Mexican restaurant in the center of town"
返回结构化的数据:
3、rasa_nlu组件
针对中文对话rasa_nlu也提供了中文本的组件,各个组件相互衔接最终以pipeline的形式实现最终的意图识别和实体抽取功能。
组件模块主要包括:数据处理(training_data)、文本分词(tokenizers)、特征表示(featurizers)、意图分类(classifiers)、实体抽取(extractors)等模块。各个组件的数据用Message类进行传递。
training_data模块主要的功能是加载模型训练所需要的数据,并存储成文本分词模块所需要的数据形式。
tokenizers模块的主要功能是处理模型训练、测试数据,对文本进行按照jieba分词、空格分词、按单词分词等多种方式进行处理,并将处理结果保存成特征表示模块需要的数据形式。数据保存在Message[“tokens”]中。
featurizers主要实现将处理后的文本数据转化成特征向量表示。组件中配置了sklearn的CountVectorizer方法、mitie特征表示的方法、spacy特征表示的方法(先仅支持英文)等来对文本进行表示。最后保存成意图分类所需要的数据形式,数据保存在Message[“text_features”]中。
Classifiers主要实现对文本的意图进行分类。组件中配置了计算文本向量距离的方式、mitie.text_categorizer_trainer方式、sklearn.svm.SVC方式实现意图分类的算法。数据保存在Message [“intent”, “intent_ranking”]中。
Extractors主要实现对文本中实体进行提取。组件中配置了基于CRF模型的方法、Duckling包提取实体的方法、mitil提取实体的方法、Sapcy提u去实体的方法、EntitySynonymMapper类可以将提取到的是实体用同义词进行替换。数据保存在Message[“entities”]中。
二、rasa_nlu的整理框架
1、nlu模型训练代码逻辑
rasa_nlu以组件的形式实现意对文本的意图识别和实体抽取的功能。管道(pipline)训练的过程中需要对每个组件进行处理或训练。整个训练的过程主要分成一下几个步骤:
(1) 加载训练数据
(2) 数据处理
(3) 特征转化
(4) 训练意图分类模型
(5) 训练实体抽取模型
2、nlu预测代码逻辑
Rasa 以server的形式提供服务接口,其进入rasa_nlu模块的步骤如下:
- 启动server,调用run文件中的app.run()函数启动server。当然在app.run之前需要加载配置文件以及加载训练好的模型。
- Server开启之后就一直对程序进监听,当有对话输入时就会调用app.handel_request()函数,在函数内调用app.agent.handel_massage()函数来处理接收到信息。接收到的信息存储在meaasage类中,信息如下图所示:
- 在agent的handel_massage函数中调用prcocess的handel_message()函数。

- Process的handel_message函数(如上图)中调用self.log_message()(如下图)用message_processor 处理对话 & 获取当前对话之前的tracker并保存当前对话状态。调用_handle_message_with_tracker(message, tracker)函数处理数据
- self._handle_message_with_tracker(message, tracker) 用于解析message并且更新tracker。

- self._parse_message(message)调用解释器interpreter的解析函数pares()调用用pipeline中各组件的解释函数。
- model.py Interpreter.parse,Interpreter中的pipeline保存着nlu模块的各个component

component.process 有Has overridden methods(有重构函数),通过config.pipeline文件配置的组件信息调用各个组件。
在预测接管nlu模块的组件受config文件的配置影响,以下面的config.pipeline配置文件为例,对rasa_nlu模块预测过程的处理步骤进行说明。
language: "zh"
pipeline:
- name: "JiebaTokenizer"
- name: "RegexFeaturizer"
- name: "CountVectorsFeaturizer"
stop_words: "english"
min_df: 1
max_df: 1.0
token_pattern: "[\u4e00-\u9fa5_a-zA-Z0-9]{1,}"
- name: "EmbeddingIntentClassifier"
batch_strategy: sequence
mu_pos: 0.8
- name: "CRFEntityExtractor"
- name: "EntitySynonymMapper"
Nlu模块处理中文时的调用步骤注主要包含一下几个部分:
- 用JiebaTokenizer模块处理接收到的数据,Message.set(“tokens”)。
- 用CountVectorsFeaturizer模块提取文本的特征,并结合RegexFeaturizer将用正则表示的文本信息转化成特征向量,Message.set(“text_features”)。
- 用EmbeddingIntentClassifier模块对文本的意图进行分类,message.set(“intent”,“intent_ranking”)。
- CRFEntityExtractor组件提取文本的实体,配合EntitySynonymMapper组件将进行同义词转化,message.set("entities ")。
三、rasa_nlu实践
1、目的
用rasa框架实现多轮对话,接入天气查询、情感分析、文本审核、实体抽取、会议检索等功能。
2、实践数据
实践数据是结合实际业务中的意图类别以及任务型对话中需要的实体等要求人为整理了一批数据。
3、实践结果
在实践中用rasa_nlu模块完成文本解析的工作,针对天气查询业务设计了查询语句的意图(request_search_weather)需要的实体为查询的地点(laocation_weather)和查询的时间(date_time)。以“杭州今天的天气怎么样”为例,nlu模块对语句进行解析得到的结果如下图所示:
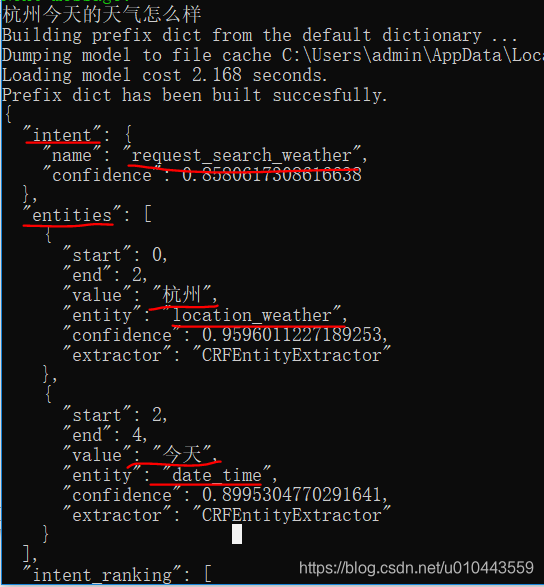
虽然nlu模块完成了文本意图的识别和实体的提取,但是这无法满足多轮对话的任务。实现完整的对话逻辑需要结合rasa core部分的对话管理和对话跟踪的功能,对整个对话进行管理。
4、结合业务场景
Rasa框架是一个很好的设计AI机器人的框架,rasa nlu模块和rasa core模块的结合能够实现完整的对话逻辑。Rasa Core是Rasa框架提供的对话管理模块,它类似于聊天机器人的大脑,主要的任务是维护更新对话状态和动作选择,然后对用户的输入作出响应。所谓对话状态是一种机器能够处理的对聊天数据的表征,对话状态中包含所有可能会影响下一步决策的信息,如自然语言理解模块的输出、用户的特征等;所谓动作选择,是指基于当前的对话状态,选择接下来合适的动作,例如向用户追问需补充的信息、执行用户要求的动作等。举一个具体的例子,用户说“帮我妈妈预定一束花”,此时对话状态包括自然语言理解模块的输出、用户的位置、历史行为等特征,根据上述内容core模块对及其下一步动作进行预测。Core部分的对话管理模块主要是负责协调聊天机器人的各个模块,起到维护人机对话的结构和状态的作用。对话管理模块涉及到的关键技术包括对话行为识别、对话状态识别、对话策略学习以及行为预测、对话奖励等。下面是Rasa Core消息处理流程:
首先,将用户输入的Message传递到Interpreter(NLU模块),该模块负责识别Message中的"意图(intent)“和提取所有"实体”(entity)数据;
其次,Rasa Core会将Interpreter提取到的意图和识别传给Tracker对象,该对象的主要作用是跟踪会话状态(conversation state);
第三,利用policy记录Tracker对象的当前状态,并选择执行相应的action,其中,这个action是被记录在Track对象中的;
最后,将执行action返回的结果输出即完成一次人机交互。
Rasa nlu和rasa core模块的结合可以实现完整的多轮对话内容,但是现阶段的研究还不是很透彻有很多不确定的因素,所以未来需要更加深入的研究和学习。
参靠文献
[1] https://rowl1ng.com/blog/%E6%8A%80%E6%9C%AF/chatbot.html
[2] https://blog.csdn.net/AndrExpert/article/details/92805022
[3] https://rasa.com/docs/rasa/core/about/
[4] https://www.cnblogs.com/huangqihui/p/10978837.html
[5] https://mubu.com/doc/19aK8HlxFw
