去年有一篇利用好奇心驱动进行exploration的强化学习文章很有意思(Curiosity-driven Exploration by Self-supervised Prediction)。在大多数真实世界的问题中,外在世界的激励(reward)往往极其稀疏,甚至缺失。得不到反馈的agent则缺乏有效的机制更新自己的策略函数(policy)。 在这种情况下,文章提出了利用内在的好奇心来驱动对世界的探索。
文章举了一个例子:在一个阳光明媚的周末午后,一个三岁小孩在人生中的激励遥不可及的情况下(比如大学,工作,房子,家庭等等),仍然能够在游乐场上没心没肺的玩耍。作为人类主体(human agent),她的行为受到了心理学家称之为内在激励(intrinsic motivation)即好奇心的驱动。好奇心是一种学习新知识/技巧的方法,而这些新技巧在未来获得激励时会发挥作用。
好奇心驱动的探索
智能体由两个子系统组成:激励产生器(reward generator)和策略(policy)。前者产生好奇心驱动的内在激励,后者产生用来最大化激励信号的一系列行为。为了使算法不失一般性,假设智能体也可以从环境偶尔获得外在的激励。在时间t,假设内在激励为 ,外在激励为 。那么策略子系统用来最大化 。这里 在多数情况下为0。
具体而言,假设policy
被表达为一个参数为
的深度神经网络,我们需要找到最大化总激励期望值的
:
那么
应该是什么,或者说,什么才是好的好奇心驱动的激励函数?直觉上来讲,如果所见非所料,应该说好奇心会得到极大的满足,如果一个人总是料事如神,事事如愿,那么他应该不会有任何好奇心上的收获。
于是,基于当前状态
,给定动作
,智能体对下一个状态
的预测差(prediction error)可以作为好的内在激励函数。
预测差作为好奇心激励
但是…我们不能随意的定义状态 。以游戏为例,最简单的办法是以游戏动画的每一帧作为 。但是这会带来非常大的问题,且不说在像素级别的预测本身充满了难度,就是以预测像素作为目标函数都疑点丛生。假设智能体观察到了微风中树叶摇曳,从像素级别来看,很难预测每个树叶的位置。像素级别的预测差会非常高,智能体就会对树叶一直保持很高的好奇心。然而树叶运动对于智能体无关紧要,让智能体对树叶的运动规律充满探索精神并不可取。
文章把观测到的环境分为三种类型:
- 智能体可控的
- 智能体不能控制但是能够影响到智能体的(比如其他agent控制的赛车)
- 不可控也不影响智能体的(比如移动的树叶)
一个好的特征空间应该反映 1和2 但不能受3的影响。这是因为,对于那些充满变化又无关紧要的变量,智能体完全可以置之不理。
自监督预测
为了找到这样的特征空间,文章采取的做法是对动作(action)做自监督预测。具体而言,作者使用两个子模块:第一个子模块把 编码成 ,第二个子模块利用前一个模块编码的连续两个状态 和 来预测动作 。这有一点reverse engineering的意思。一般来讲人们利用 和 来预测下一个状态 ,这里反过来操作。这么做的好处是,模型必须能够从状态中抽象出对于决定动作有影响(即上文的1和2)特征,而摒弃无用的(即3)特征。
举个例子,假设我们在看一场足球赛,我们观察中国队球员射门,突然因为转播信号不好,我们失去了两秒钟的画面,当重新看到画面的时候中国队正在庆祝。那么我们能够做出的推测就是中国队进球了。如果画面切回时我们看到中国队员双手叉腰,低头吐痰再抬头望天,我们也可以猜到射门偏了。 注意,帮助我们做出推断的并不是看台上的观众或者场下的广告牌,也不是蓝天,白云,绿茵场,虽然它们也出现在了画面里面。最重要的信息是足球,球员,球门等等。我们的大脑一定是对这些信息进行了编码才做出了准确的推断。
用数学的语言,目标是最优化:
这里
定义为:
函数
就是逆动力学模型(inverse dynamics model)。
这里需要一个encoder对
编码产生
,这个当然是用卷积网络来完成。内在激励信号
可以表示为:
这正是对下一个状态的预测差。公式里的预测值
可以用另外一个前向网络来产生:
显然,如果系统对下一个状态预测的不准确,那么“惊讶”程度就越高,就越能满足好奇心,这正是我们想要的。然而如果我们满足于此,算法还是存在很大问题。问题出在哪里?
这是因为这里存在一个荒谬的最优解,这个最优解就是
, 因为它使得
永远取得最大值。所以我们必须对
施加某种限制(可以理解为regularization),最简单的限制就是最小化另一个loss function:
为了产生好奇心驱动的内在激励,我们需要同时优化上述的前向和反向动力Loss。反向模型能够帮助我们学习到对于预测动作(action)最有用的状态特征(feature space),而前向模型能够在这个特征空间中做出预测。作者把这个机制称为ICM(Intrinsic Curiosity Module)。如下图:
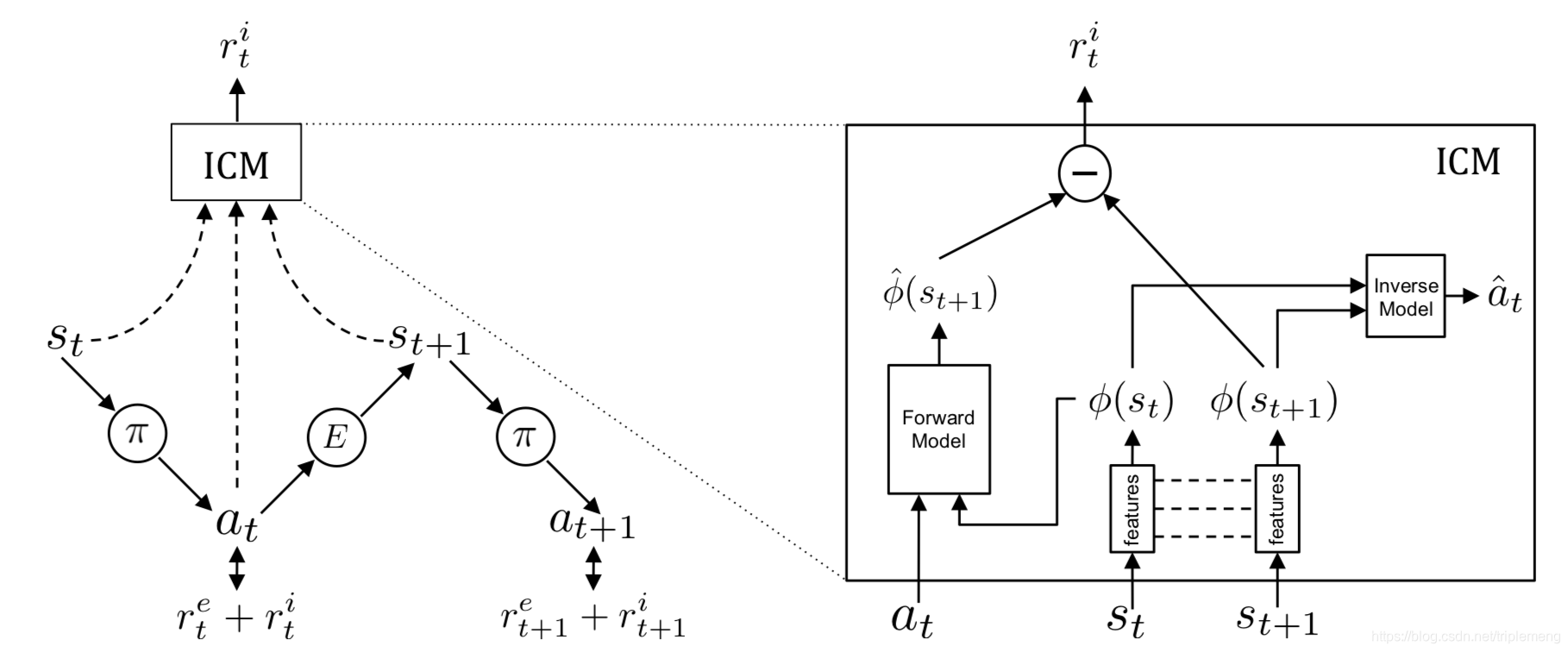
右边是ICM的详细图示:输入是当前状态,下一个状态和动作,输出是内在激励。
把上述内容放在一起,这个优化问题是:
我个人觉得这个Loss function有些精分 :)
它的前两项相互矛盾:一方面需要最大程度的满足好奇心,即达成现实和预测最大程度的脱节,另一方面又要保持良好的预测能力,不至于让前者产生荒谬解。这意味着要使预测尽可能的贴近现实。当然,从另外一个角度来看,第二项也可以被理解为regularization,避免对激励产生overfit。
实验设置和结果
文章用到的两个环境是VizDoom和大家熟悉的Super Mario Bros。作者作了很多有意思的实验。这里只简单列举几个。
(为了解决时间上的依赖性,作者用4个连续的frame串在一起作为一个状态。实验利用了A3C方法来训练20个workers。编码后的状态作为输入给LSTM,LSTM的输出上面有两个独立的全连接层用来分别预测值函数和动作。)


基线模型
作者提出的算法称为"ICM+A3C"。相应有三个基线模型:
- vanilla A3C算法,即使用 -greedy的算法。
- ICM-pixels+A3C: 没有inverse model,直接利用像素特征的算法
- 现在state of art的算法:VIME(+TRPO)
改变外在激励的稀疏程度
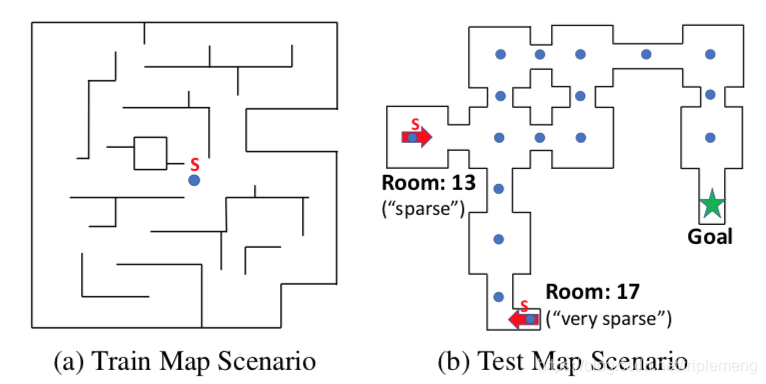
在右图中,9个房间由走道连接起来,智能体的目标是到达固定的目标地点(绿色星星)。智能体找到装备会得到1分。图中17个蓝点是初始化游戏时,智能体可能出现的地点,它们对应提供稠密激励的环境而且各自的texture不同。13号和17号房间分别对应稀疏激励和非常稀疏的激励环境。
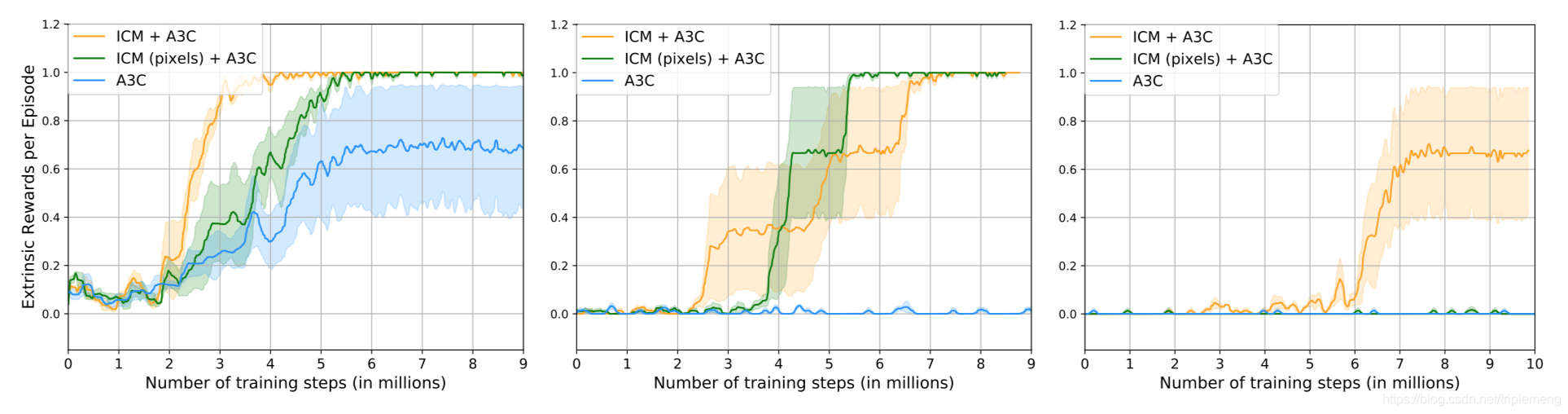
上图比较了三种情况:(a)稠密激励 (b)稀疏激励 ©非常稀疏的激励。首先作为baseline的A3C模型随着激励越来越稀疏表现越来越差。好奇心激励的A3C模型(ICM+A3C)在三种情况下表现都很好。它几乎不受外界激励的稀疏程度的影响,这是因为好奇心作为内在的激励可以很好的取代外在激励。像素级别的好奇心激励(ICM(pixels)+A3C)表现不错,但是在外在激励非常稀疏的情况下失效。
在稠密激励环境中,好奇心智能体学习的速度要快很多,这说明它的探索策略比基线方法更有效率。ICM-pixels在有着不同的texture的环境中显然会学习到很多和智能体动作无关的环境信息,这也是为什么效果不如ICM。
没有激励的环境
在没有外在激励的情况下,好奇心模型仍然会有非常好的表现。在VizDoom中没有外在激励的智能体能够探索很多房间,有些甚至穷尽了所有的房价并到达了距离出发地最远的地方。下图是一些实验的结果:

绿色是通过好奇心激励驱动的智能体的探索路线。
蓝色是随机探索的智能体。二者都没有任何外在的激励信号。显然好奇心模型能够支持智能体进行范围更大的探索。
相似的,在Mario游戏中,智能体(Mario)纯粹利用好奇心进行探索,而不从杀死敌人或者躲避危险中得到任何激励信号。这样的智能体仍然学会了如何杀死敌人和躲避攻击。原因是因为被敌人杀掉会导致智能体只能看到一小部分的游戏空间,从而迅速导致其好奇心饱和。为了保持"好奇心",智能体必须学会杀死敌人和躲避危险,以到达更多更新的游戏空间。
在新环境的泛化能力
好奇心驱动的智能体到底学习到了多少用来探索环境的泛化能力?还是说,智能体仅仅记住了其训练时的环境?为了了解这一点,作者在无激励的环境下训练了智能体,然后在三种不同的情况下检验了学习到的策略:a)直接在新环境中使用策略 b)用好奇心激励来fine-tuning策略 c)利用策略最大化外在激励。
在三种情况下, 作者都观察到了有效的泛化能力。这里不再一一介绍。
总结
这是去年的一篇论文,据作者称,这是第一个不通过任何外在激励,仅利用像素信息学习到如何在3D环境中探索和打游戏的智能体。今年,这些作者和OpenAI合作,出了一篇后续的论文(Large-Scale Study of Curiosity-Driven Learning),对好奇心激励进行了更深入的研究。我个人非常喜欢好奇心激励这个想法,我觉得不管是好奇心或是好胜心还是其他什么心,内源性的激励才能源源不断的提供给智能体学习的信号,依靠外在的激励束缚太多(比如令人们大为头疼的稀疏性)。再者,从生物学的角度来看,人脑并不是一个简单的刺激-响应系统(stimulus-response)。对激励的反应也是这样,它不能是单纯的响应外界刺激,而应该和人心理上的机制存在一个互动过程。在前面图示中有一个框表示ICM,其框住的内容应该相当于一个对人的心理机制或者人脑的一个概括: 当人脑接收到外界的状态信息( 和 )以及自己对外界的动作( )时,它首先对这些信息进行了处理,处理过程就是方框里所描述的,其输出 的方向是从内到外,即从内在心理指向外界。它的方向和传统的外界激励相反。传统上激励被认为环境给与智能体。
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关计算机视觉

