论文研读系列汇总:
1.AlexNet论文研读
2.VGG论文研读
3.GoogLeNet论文研读
4.Faster RCNN论文研读
5.ResNet 论文研读
6.SENet 论文研读
7.CTPN 论文研读
8.CRNN 论文研读
9.EAST 论文研读
文本检测领域,有一篇经典的论文,是旷世科技在2017年提出来的EAST模型,论文的全称为《EAST: An Efficient and Accurate Scene Text Detector》,论文的下载地址如下:
论文地址:https://arxiv.org/pdf/1704.03155.pdf
本文将对该方法进行具体介绍,为解释详细并通俗,这篇文章基本涵盖了网上能找到的大部分热门east讲解文章
EAST模型介绍
1.EAST模型结构
通过下图我们知道,一个文本检测有多个阶段,就以region proposals系的检测算法为例,他们通常包含候选框提取、候选框过滤、bouding box回归、候选框合并等阶段,EAST的作者认为,一个文本检测算法被拆分成多个阶段其实并没有太多好处,实现真正端到端的文本检测网络才是正确之举。所以EAST的pipeline相当优雅,只分为FCN生成文本行参数阶段和局部感知NMS阶段,网络的简洁是的检测的准确性和速度都有了进一步的提高。

2.全文贡献
- 提出了一个由两阶段组成的场景文本检测方法:FCN阶段和NMS阶段。FCN直接生成文本区域,不包括冗余和耗时的中间步骤。
- 该pipeline可灵活生成wordlevel或line level预测,其几何形状可为旋转框或矩形。
- 所提出的算法在准确性和速度上明显优于最先进的方法。
3. 模型原理
EAST的网络结构总共包含三个部分:feature extractor stem(特征提取分支), feature-merging branch(特征合并分支) 以及 output layer(输出层)。

-
在特征提取分支部分,主要由四层卷积层组成,可以是一些预训练好的卷积层,作者采用的是VGG16中pooling-2到pooling-5每一层得到的feature map。记每一层卷积层卷积后得到feature map为fi,如图1所示,从上到下。
-
在特征合并分支部分,其实作者借鉴了U-net的思想,只是U-net采用的是反卷积的操作,而这里采用的是反池化的操作,具体的计算大致如下,对于一个fi,首先经过一层反池化操作,得到与上一层卷积feature map同样大小的特征,然后将其与fi+1进行拼接,拼接后再依次进入一层和的卷积层,以减少拼接后通道数的增加,得到对应的,在特征合并分支的最后一层,是一层的卷积层,卷积后得到的feature map最终直接进入输出层。具体的计算公式如下:
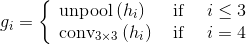
其中,gi被称为合并基,hi是合并后得到feature map。之所以要引入特征合并分支,是因为在场景文字识别中,文字的大小非常极端,较大的文字需要神经网络高层的特征信息,而比较小的文字则需要神经网络浅层的特征信息,因此,只有将网络不同层次的特征进行融合才能满足这样的需求。
#代码实现该部分
for i in range(4):
print('Shape of f_{} {}'.format(i, f[i].shape))
g = [None, None, None, None]
h = [None, None, None, None]
num_outputs = [None, 128, 64, 32]
for i in range(4):
if i == 0:
h[i] = f[i] # 计算h
else:
c1_1 = slim.conv2d(tf.concat([g[i-1], f[i]], axis=-1), num_outputs[i], 1)
h[i] = slim.conv2d(c1_1, num_outputs[i], 3)
if i <= 2:
g[i] = unpool(h[i]) # 计算g
else:
g[i] = slim.conv2d(h[i], num_outputs[i], 3)
print('Shape of h_{} {}, g_{} {}'.format(i, h[i].shape, i, g[i].shape))
-
在输出层部分,主要有两部分,一部分是用单个通道的卷积得到score map(分数图),记为Fs,另一部分是多个通道的卷积得到geometry map(几何形状图),记为Fg,在这一部分,几何形状可以是RBOX(旋转盒子)或者QUAD(四边形)。(即可以检测水平文本的数据集(如IC2013)标注也可以是几何图形(IC2015)标注)
对于RBOX,主要有5个通道,其中四个通道表示每一个像素点与文本线上、右、下、左边界距离记为R,另一个通道表示该四边形的旋转角度。
对于QUAD,则采用四边形四个顶点的坐标表示,每个点的坐标为,因此,总共有8个通道。关于RBOX和QUAD的表示可以见表1:


RBOX的参数解释如图所示,从像素位置到矩形的顶部,右侧,底部,左侧边界的4个距离和通道角度 -
(a) 中黄色的为人工标注的框,绿色为对黄色框进行0.3倍边长的缩放后的框,这样做可以进一步去除人工标注的误差,拿到更准确的label信息。
-
(b) 为根据(a)中绿色框生成的label信息
-
(c )中先生成一个(b)中白色区域的最小外接矩,然后算每一个(b)中白色的点到粉色最小外接矩的上下左右边的距离,即生成(d),然后生成粉色的矩形和水平方向的夹角,即生成角度信息(e),e中所有灰色部分的角度信息一样,都是同样的角度。
# 计算score_map
F_score = slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None)
# 4 channel of axis aligned bbox and 1 channel rotation angle
# 计算RBOX的geometry_map
geo_map = slim.conv2d(g[3], 4, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) * FLAGS.text_scale
# angle is between [-45, 45] #计算angle
angle_map = (slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) - 0.5) * np.pi/2
F_geometry = tf.concat([geo_map, angle_map], axis=-1)
3.1模型结构全代码
#获得文本框的预测分数和几何图形
def model(images, weight_decay=1e-5, is_training=True):
'''
define the model, we use slim's implemention of resnet
'''
images = mean_image_subtraction(images)
with slim.arg_scope(resnet_v1.resnet_arg_scope(weight_decay=weight_decay)):
logits, end_points = resnet_v1.resnet_v1_50(images, is_training=is_training, scope='resnet_v1_50')
with tf.variable_scope('feature_fusion', values=[end_points.values]):
batch_norm_params = {
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'is_training': is_training
}
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
weights_regularizer=slim.l2_regularizer(weight_decay)):
#提取四个级别的特征图(记为fi)
f = [end_points['pool5'], end_points['pool4'],
end_points['pool3'], end_points['pool2']]
for i in range(4):
print('Shape of f_{} {}'.format(i, f[i].shape))
#基础特征图
g = [None, None, None, None]
#合并后的特征图
h = [None, None, None, None]
#合并阶段每层的卷积核数量
num_outputs = [None, 128, 64, 32]
#自下而上合并特征图
for i in range(4):
if i == 0:
h[i] = f[i]
else:
#先合并特征图,再进行1*1卷积 3*3卷积
c1_1 = slim.conv2d(tf.concat([g[i-1], f[i]], axis=-1), num_outputs[i], 1)
h[i] = slim.conv2d(c1_1, num_outputs[i], 3)
if i <= 2:
#上池化特征图
g[i] = unpool(h[i])
else:
g[i] = slim.conv2d(h[i], num_outputs[i], 3)
print('Shape of h_{} {}, g_{} {}'.format(i, h[i].shape, i, g[i].shape))
#输出层
# here we use a slightly different way for regression part,
# we first use a sigmoid to limit the regression range, and also
# this is do with the angle map
#获得预测分数的特征图,与原图尺寸一致,每一个值代表此处是否有文字的可能性
F_score = slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None)
# 4 channel of axis aligned bbox and 1 channel rotation angle
#获得旋转框像素偏移的特征图,有四个通道,分别代表每个像素点到文本矩形框上,右,底,左边界的距离
geo_map = slim.conv2d(g[3], 4, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) * FLAGS.text_scale
#获得旋转框角度特征图 angle is between [-45, 45]
angle_map = (slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) - 0.5) * np.pi/2
#按深度连接旋转框特征图和角度特征图
F_geometry = tf.concat([geo_map, angle_map], axis=-1)
return F_score, F_geometry
4.标签生成
Geometry Map生成(图c~e)
对于其文本区域以QUAD格式标注的数据集(例如ICDAR 2015),我们首先生成一个旋转矩形,以最小面积覆盖该区域。然后,对于每个有正分数的像素,我们计算它与文本框4个边界的距离,并将它们放到RBOX ground truth的4个通道中。对于QUAD ground truth,8通道几何图形每个像素的正分数值是它与四边形4个顶点的坐标偏移
5.局部感知NMS算法
当预测结束后,需要对文本线进行构造,为了提高构造的速度,作者提出了一种局部感知NMS算法。在假设来自附近像素的几何图形倾向于高度相关的情况下,提出逐行合并几何图形,并且在合并同一行中的几何图形时,我们将迭代合并当前遇到的几何图形与最后一个合并图形。这种改进的技术在场景中以O(n)运行。合并的四边形坐标是通过两个给定四边形的得分进行加权平均的。是平均而非选择,充当了投票机制,采取这种方法可以将所有框的坐标信息都加以利用,而不像常规NMS一样直接弃掉得分低的框,也许会丢失信息。

当合并完成后,会将合并后的几何形状作为一个整体继续合并下去,直到不满足合并条件,将此时合并后的几何形状作为一个文本线保存到当中,重复该过程,直到所有的几何形状都遍历一遍为止
代码实现如下:
def weighted_merge(g, p):
g[:8] = (g[8] * g[:8] + p[8] * p[:8])/(g[8] + p[8])
g[8] = (g[8] + p[8])
return g
6.损失函数设计
损失函数分为两种,QUAD和RBOX,在真正实现上,选择的是RBOX,实验评估放在ICDAR2015和ICDAR2017上。QUAR也可以被使用。下面介绍RBOX的损失函数设计。
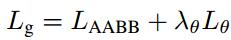
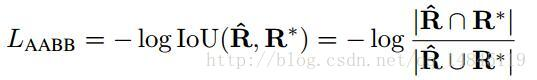

角度误差为:
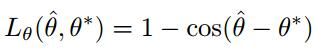
回归有2个loss,分别回归边框的上下左右距离L_AABB,和边框与水平方向的夹角L_theta。
其中,
L_AABB=-log(area_intersect/area_union),
L_theta = 1 - tf.cos(theta_pred - theta_gt)
其中,
d1_pred, d2_pred, d3_pred, d4_pred分别为距离上,右,下,左,边框的预测的距离。
d1 -> top, d2->right, d3->bottom, d4->left分别为距离上,右,下,左,边框的label的距离。
theta_pred为预测的角度。
theta_gt为label的角度。
6.1损失函数代码解读
#获得预测得分损失
def dice_coefficient(y_true_cls, y_pred_cls,
training_mask):
'''
dice loss
:param y_true_cls:
:param y_pred_cls:
:param training_mask:
:return:
'''
eps = 1e-5
intersection = tf.reduce_sum(y_true_cls * y_pred_cls * training_mask)
union = tf.reduce_sum(y_true_cls * training_mask) + tf.reduce_sum(y_pred_cls * training_mask) + eps
loss = 1. - (2 * intersection / union)
tf.summary.scalar('classification_dice_loss', loss)
return loss
#获得总损失
def loss(y_true_cls, y_pred_cls,
y_true_geo, y_pred_geo,
training_mask):
'''
define the loss used for training, contraning two part,
the first part we use dice loss instead of weighted logloss,
the second part is the iou loss defined in the paper
:param y_true_cls: ground truth of text
:param y_pred_cls: prediction os text
:param y_true_geo: ground truth of geometry
:param y_pred_geo: prediction of geometry
:param training_mask: mask used in training, to ignore some text annotated by ###
:return:
'''
classification_loss = dice_coefficient(y_true_cls, y_pred_cls, training_mask)
# scale classification loss to match the iou loss part
classification_loss *= 0.01
# d1 -> top, d2->right, d3->bottom, d4->left
d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = tf.split(value=y_true_geo, num_or_size_splits=5, axis=3)
d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = tf.split(value=y_pred_geo, num_or_size_splits=5, axis=3)
#计算真实旋转框、预测旋转框面积
area_gt = (d1_gt + d3_gt) * (d2_gt + d4_gt)
area_pred = (d1_pred + d3_pred) * (d2_pred + d4_pred)
#计算相交部分的高度和宽度 面积
w_union = tf.minimum(d2_gt, d2_pred) + tf.minimum(d4_gt, d4_pred)
h_union = tf.minimum(d1_gt, d1_pred) + tf.minimum(d3_gt, d3_pred)
area_intersect = w_union * h_union
#获得并集面积
area_union = area_gt + area_pred - area_intersect
#计算旋转框IOU损失、角度 加1为了防止交集为0
L_AABB = -tf.log((area_intersect + 1.0)/(area_union + 1.0))
L_theta = 1 - tf.cos(theta_pred - theta_gt)
tf.summary.scalar('geometry_AABB', tf.reduce_mean(L_AABB * y_true_cls * training_mask))
tf.summary.scalar('geometry_theta', tf.reduce_mean(L_theta * y_true_cls * training_mask))
L_g = L_AABB + 20 * L_theta
return tf.reduce_mean(L_g * y_true_cls * training_mask) + classification_loss
7.参考
全论文翻译:https://blog.csdn.net/zhangwl27/article/details/86542160
参考链接(推荐)****
https://blog.csdn.net/qq_14845119/article/details/78986449
拥有advancedeast改进思路:https://blog.csdn.net/linchuhai/article/details/84677249
参考链接:https://blog.csdn.net/attitude_yu/article/details/80724187
参考链接:https://blog.csdn.net/weixin_38708130/article/details/83789457
参考链接:https://blog.csdn.net/attitude_yu/article/details/80724187
参考链接:https://blog.csdn.net/zhangwei15hh/article/details/79899300
参考链接:https://blog.csdn.net/sdlypyzq/article/details/78425128
