1.介绍
1.1.介绍
本文基于《Shape Robust Text Detection with Progressive Scale Expansion Network》翻译总结。PSENet(Progressive Scale Expansion Network)称为渐进尺度扩展网络,主要是进行任意形状的文字定位。可以处理不同的光照条件、不同的颜色、不同的尺度大小。甚至可以处理文字区域非常接近,以及有部分重合的图片。
Code will be available in https://github.com/whai362/PSENet.
2.网络结构
2.1.网络整体介绍

1.首先是FPN,获取4组256 channels特征集合(P2,P3,P4,P5).
2.为了进一步结合从低到高的语义特征,混合上面的4个特征集合到特征集合F,F有1024channels。
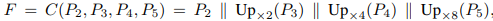
其中||代表连接,Up代表上采样。
3.F后面是Conv(3*3)-BN-ReLU 层,减少到256channels。接着它通过组合的Conv(1,1)-Up-Sigmoid层,产生n个分割结果S1,S2,…Sn. 将这个分割结果S称为kernels。
4.为了获取最终的检测结果,采用了progressive scale expansion 算法。从最小尺度的kernel开始,通过在更大的kernel加入更多的像素逐渐扩大区域,直到最大的kerne被找到。
2.2.渐进尺度扩展算法
比如下图,b图融合kernel S2的像素,扩展成c图;C图融合kernel S3的像素,扩展成d图。下图是两个尺度的扩展示意图。


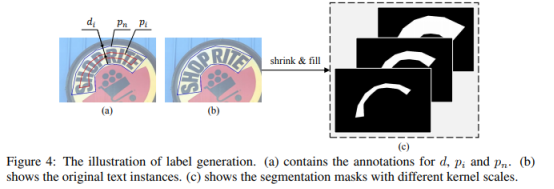
2.3.标签生成


2.4.损失函数
分为两部分Lc和Ls,Lc关注于整体的文字区域与非文字区域;Ls关注于收缩后的文字区域,即去掉了非文字区域。因为有许多相似的图像可能类似文字符号,比如格子等,故采用了OHEM(Online Hard Example Mining)方法。OHEM算法的核心是选择一些hard example作为训练的样本从而改善网络参数效果,hard example指的是有多样性和高损失的样本。
整体损失函数如下:
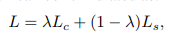
先介绍下D(dice coefficient骰子系数)如下定义:
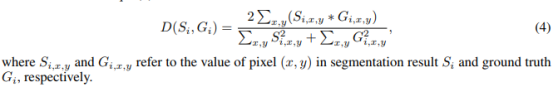
其中,M代表OHEM,Lc公式如下
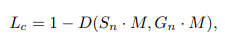
Ls公式如下

3.实验结果
3.1.m与n的选择
下面左图是m=0.5情况下,可见n=6时就表现足够好;右图是n=6时,可见m=0.5表现最好。


3.2.效果展示
第3列是CTD+TLOC弯曲文字检测算法(在论文Detecting Curve Text in the Wild: New Dataset and New Solution中描述的),最后一列是PSENet效果。
