模型压缩原因
论文Predicting parameters in deep learning提出,其实在很多深度的神经网络中存在着显著的冗余。仅仅使用很少一部分(5%)权值就足以预测剩余的权值。该论文还提出这些剩下的权值甚至可以直接不用被学习。也就是说,仅仅训练一小部分原来的权值参数就有可能达到和原来网络相近甚至超过原来网络的性能(可以看作一种正则化)。
Krizhevsky在2014年的文章中,提出了两点观察结论:卷积层占据了大约90-95%的计算时间和参数规模,有较大的值;全连接层占据了大约5-10%的计算时间,95%的参数规模,并且值较小。
50个卷积层的ResNet-50需要超过95MB的存储器以及38亿次浮点运算(电脑的执行效能)。在丢弃了一些冗余的权重后,网络仍照常工作,但节省了超过75%的参数和50%的计算时间。
模型压缩分类
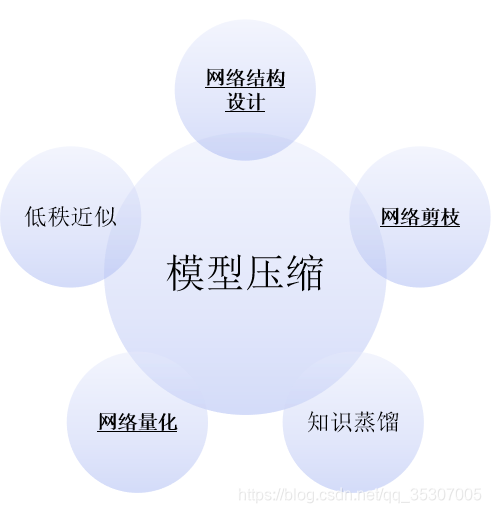
压缩已有的网络:
低秩近似
网络剪枝
网络量化
构建新的小网络:
知识蒸馏
在训练的初始阶段:
设计紧凑的网络结构
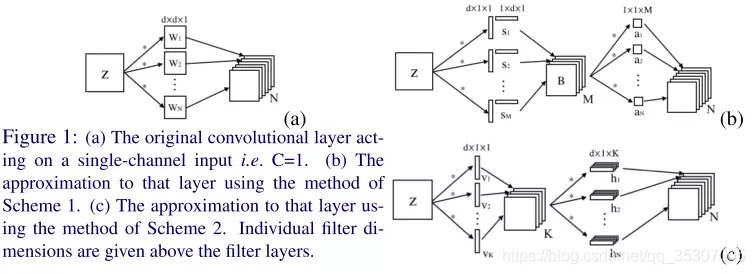
低秩近似(low-rank Approximation)
如果把原先网络的权值矩阵当作满秩矩阵来看,那么是不是可以用多个低秩的矩阵来逼近原来的矩阵,以达到简化的目的?答案是肯定的。原先稠密的满秩矩阵可以表示为若干个低秩矩阵的组合,低秩矩阵又可以分解为小规模矩阵的乘积。
存在的问题:
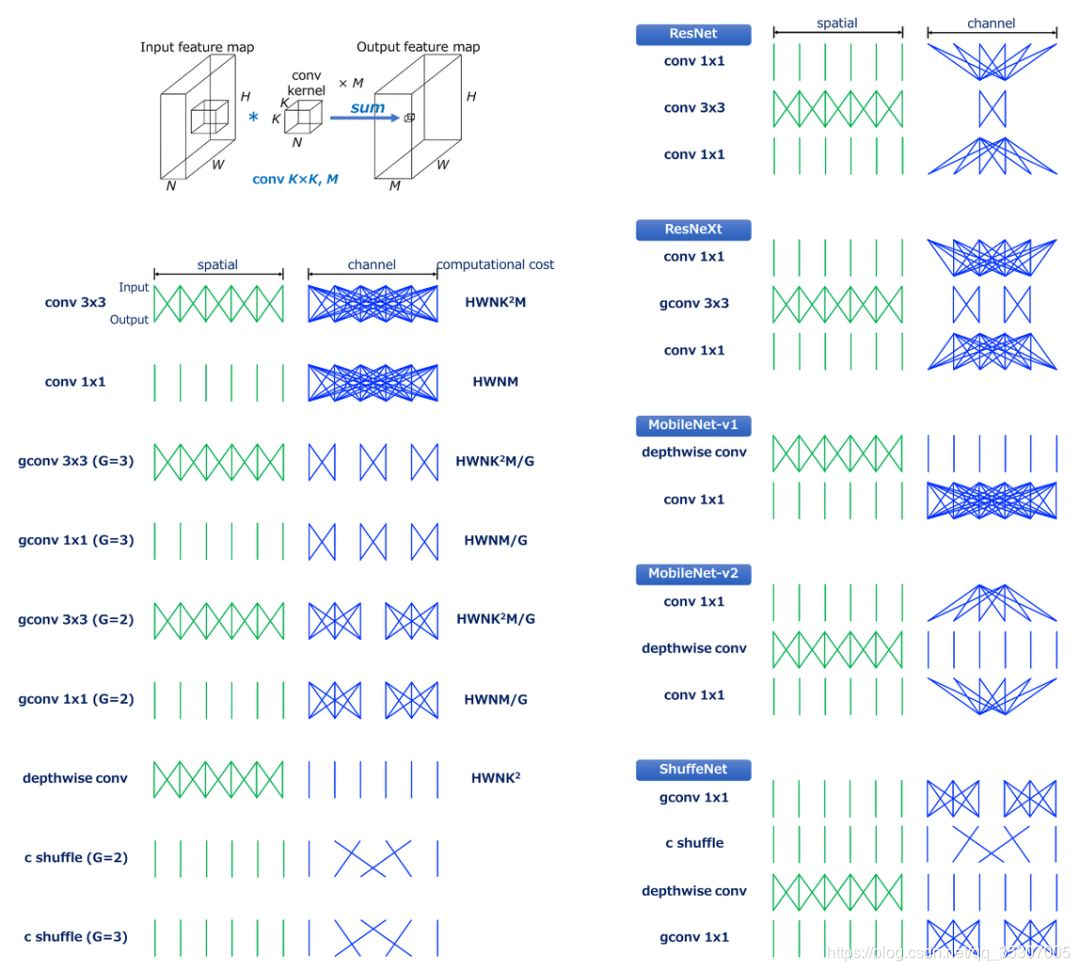
现在越来越多网络中采用1×1的卷积,而这种小的卷积使用矩阵分解的方法很难实现网络加速和压缩。
目前的主流:
2017、2018年的工作就只有Tensor Ring和Block Term分解在RNN的应用两篇相关文章了。
网络剪枝(network pruning)
网络剪枝的主要思想就是将权重矩阵中相对“不重要”的权值剔除,然后再重新fine tune 网络进行微调。
主要流程:
衡量神经元的重要程度
移除一部分不重要的神经元
对网络进行微调
返回第一步,进行下一轮剪枝
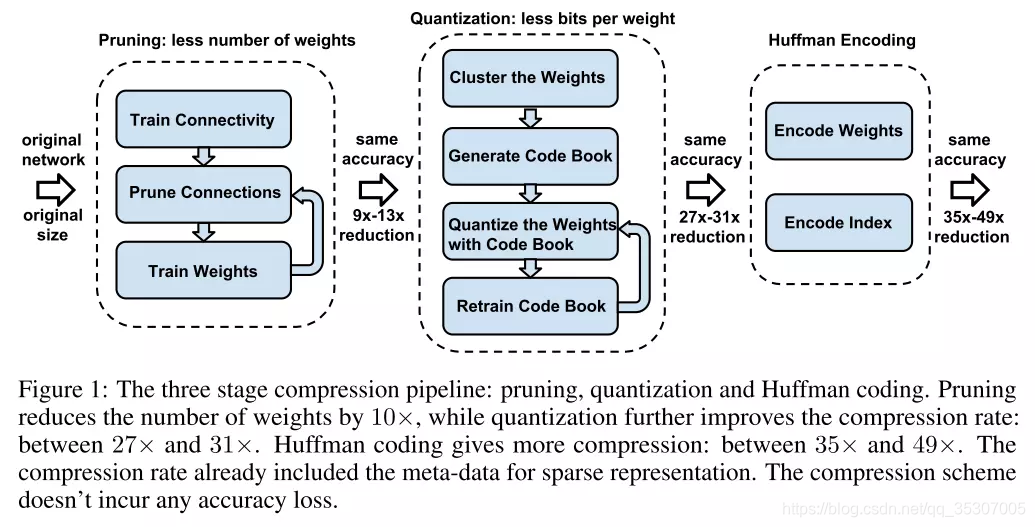
包含了三阶段的压缩方法:修剪、量化(quantization)和霍夫曼编码。修剪减少了需要编码的权重数量,量化和霍夫曼编码减少了用于对每个权重编码的比特数。对于大部分元素为0的矩阵可以使用稀疏表示,进一步降低空间冗余,且这种压缩机制不会带来任何准确率损失。这篇论文获得了ICLR2016 的Best Paper。
网络量化(network quantization)
神经网络模型的参数都是用的32bit长度的浮点型数表示,实际上不需要保留那么高的精度,可以通过量化,比如用0~255表示原来32个bit所表示的精度,通过牺牲精度来降低每一个权值所需要占用的空间。此外,SGD(Stochastic Gradient Descent)所需要的精度仅为6~8bit,因此合理的量化网络也可保证精度的情况下减小模型的存储体积。
最为典型就是二值网络、XNOR网络等。其主要原理就是采用1bit对网络的输入、权重、响应进行编码。减少模型大小的同时,原始网络的卷积操作可以被bit-wise运算代替,极大提升了模型的速度。但是,如果原始网络结果不够复杂(模型描述能力),由于二值网络会较大程度降低模型的表达能力。因此现阶段有相关的论文开始研究n-bit编码方式成为n值网络或者多值网络或者变bit、组合bit量化来克服二值网络表达能力不足的缺点。
知识蒸馏(knowledge distillation)
蒸馏模型采用的是迁移学习,通过采用预先训练好的复杂模型(Teacher model)的输出作为监督信号去训练另外一个简单的网络。这个简单的网络称之为student model。
存在的问题和研究的趋势
寻“知识”的不同形式,去除softmax的限制,研究趋向于选用中间特征层
如何选择特征层,如何设计损失函数
训练学生模型数据集的选择
学生模型的设计
如何和其他压缩方法集成
紧凑网络设计(compact Network design)
mobilenet一系列,以深度可分解卷积为基础的压缩网络模型设计