文章目录
1. 安装Centos与Java
修改hostname为hadoop-master
集群规划,将其加到hosts中
192.168.110.40 hadoop-master
192.168.110.41 hadoop-slave1
192.168.110.42 hadoop-slave2
1.1 关闭THP
不关闭THP,Hadoop的系统CPU使用率很高
出现以下情况启动了THP

永久关闭
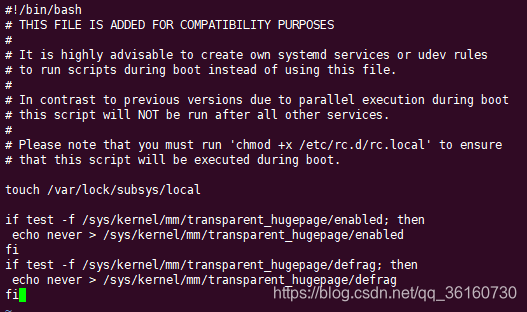
vi /etc/rc.d/rc.local
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
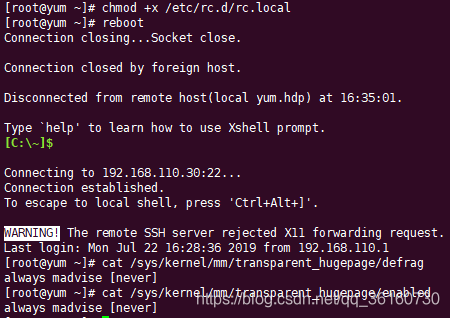
赋予执行权限,然后重启
chmod +x /etc/rc.d/rc.local
1.2 新增hadoop用户
直接使用root用户,权限过大,启动会失败,需要配置参数等,所以新增一个hadoop用户,加以权限控制,需要root权限时再使用sudo命令
无特殊说明,以下命令均使用hadoop用户执行
useradd hadoop
passwd hadoop
使用root权限,修改文件的写权限
chmod u+w /etc/sudoers
vi /etc/sudoers
hadoop ALL=(ALL) ALL
%hadoop ALL=(ALL) NOPASSWD: ALL

2. 克隆虚拟机
克隆两个虚拟机,创建完整克隆,然后修改mac地址

修改两个从节点虚拟机的ip地址和hostname
vi /etc/sysconfig/network-scripts/ifcfg-ens33
service network start
vi /etc/sysconfig/network
hostnamectl set-hostname hadoop-slavex
3. hadoop下载与安装


解压缩
mkdir -p /home/hadoop/softwares/hadoop/
tar -zxvf hadoop-3.1.2.tar.gz -C /home/hadoop/softwares/hadoop/
配置环境变量,修改 ~/.bashrc 文件,该文件中环境变量只对hadoop用户有效
export HADOOP_HOME=/home/hadoop/softwares/hadoop/hadoop-3.1.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让环境变量立即生效
source ~/.bashrc

4. hadoop使用
无特殊说明,以下命令均为在hadoop文件目录下,使用hadoop用户执行
4.1 独立模式
默认情况下,Hadoop配置为以非分布式模式运行,作为单个Java进程。
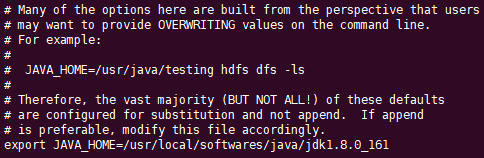
修改 etc/hadoop/hadoop-env.sh,设置为Java安装的根目录
export JAVA_HOME=/usr/local/softwares/java/jdk1.8.0_161
新建test文件夹,里面新建input文件夹,里面放input.txt
test mongodb mongodb test hdfs
hadoop hadoop hive hive hdfs
kafka elasticsearch es hdfs
kafka hbase hdfs map reduce map reduce
执行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount test/input test/output
查看结果
cat test/output/*

4.2 单节点伪分布式
修改 etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
修改 etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
免密登陆。ssh设置需要在集群上做不同的操作,如启动,停止,分布式守护shell操作。认证不同的hadoop用户,需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
检查是否可以在没有密码的情况下ssh到localhost:
ssh localhost
如果在没有密码短语的情况下无法ssh到localhost,请执行以下命令。下面的命令用于生成使用ssh键值对。复制公钥形成 id_rsa.pub 到authorized_keys 文件中,并提供拥有者具有authorized_keys文件的读写权限。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys

4.2.1 本地运行MapReduce作业
格式化文件系统
bin/hdfs namenode -format
启动NameNode守护程序和DataNode守护程序,警告提示将hadoop-master加到永久hosts中
sbin/start-dfs.sh
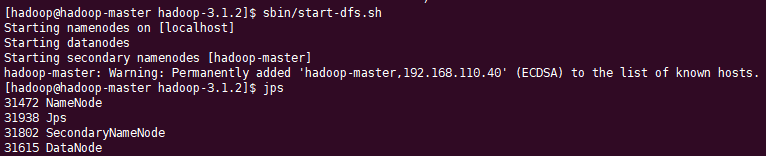
hadoop守护程序日志输出将写入$HADOOP_LOG_DIR目录(默认为$HADOOP_HOME/logs)。
浏览hdfs的Web界面,http://hadoop-master:9870
在页面新建文件夹报错,用户权限不够

修改 etc/hadoop/core-site.xml,设置静态用户为hadoop
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
重新启动hdfs
sbin/stop-dfs.sh
sbin/start.dfs.sh
添加用户后,可创建也可以上传文件


创建执行MapReduce作业所需文件夹
hdfs dfs -mkdir /hdfsTest
hdfs dfs -mkdir /hdfsTest/input
将inputx.txt复制到hdfs中
hdfs dfs -put test/input/input.txt /hdfsTest/input/

运行,注意:hdfsTest文件夹前不加/,会自动加上/user/hadoop,但hdfs上没有这个目录,就报错
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /hdfsTest/input /hdfsTest/output
检查输出文件:将输出文件从分布式文件系统复制到本地文件系统并检查它们
rm -rf test/output
hdfs dfs -get /hdfsTest/output test/output
cat test/output/*


如果要停止守护进程,运行
sbin/stop-dfs.sh
4.2.2 yarn 方式执行
确定执行了上方格式化文件系统的命令
修改 etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/* </value>
</property>
修改 etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
启动ResourceManager守护程序和NodeManager守护程序
start-yarn.sh
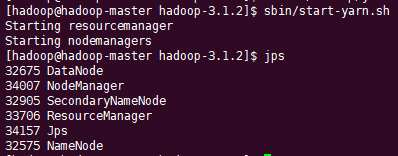
浏览ResourceManager的Web界面,http://hadoop-master:8088
运行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /hdfsTest/input /yarn/output


4.3 多节点集群
新建文件夹data
修改 etc/hadoop/core-site.xml,配置hadoop集群数据存放路径
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/softwares/hadoop/hadoop-3.1.2/data</value>
</property>
修改 etc/hadoop/hdfs-site.xml,将副本数改为2,NameNode指定为hadoop-master,SecondNameNode指定为hadoop-slave1
NameNode的存储目录树的信息,而目录树的信息则存放在fsimage文件中,当NameNode启动的时候会首先读取整个fsimage文件,将信息装载到内存中。SecondaryNameNode的作用是帮助NameNode合并fsimage和edits文件。
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hadoop-master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-slave1:9871</value>
</property>
修改 etc/hadoop/yarn-site.xml,设置resourcemanager
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
设置从节点地址,3.0后etc/hadoop下的slaves改为workers,修改etc/hadoop/workers
hadoop-slave1
hadoop-slave2
配置hadoop-master到hadoop-slave1,hadoop-slave2之间的免密通信,需要启动hadoop-slave1和hadoop-slave2并切换到hadoop用户
在hadoop-master中操作,之前在单节点伪分布式的时候已经生成了ssh,并设置了对hadoop-master的免密登录了,所以只要设置两个从节点的
ssh-copy-id hadoop-slave1
ssh-copy-id hadoop-slave2
测试是否需要密码,使用命令exit退出
ssh hadoop-slave1

分发hadoop文件目录
在hadoop-slave1和hadoop-slave2新建文件夹
mkdir -p /home/hadoop/softwares/hadoop
在hadoop-master分发
scp -r /home/hadoop/softwares/hadoop/hadoop-3.1.2/ hadoop-slave1:/home/hadoop/softwares/hadoop/hadoop-3.1.2/
scp -r /home/hadoop/softwares/hadoop/hadoop-3.1.2/ hadoop-slave2:/home/hadoop/softwares/hadoop/hadoop-3.1.2/
两台从节点添加hadoop环境变量,然后重启三台虚拟机
在hadoop-master执行命令,格式化文件系统,因为将fs.defaultFS的hdfs://localhost:9000改为了hdfs://hadoop-master:9000,否则启动hdfs会失败
hadoop namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
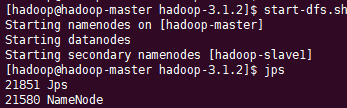
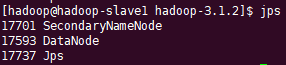
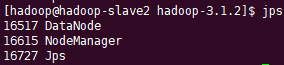
访问hdfs页面,http://hadoop-master:9870

访问yarn页面,http://hadoop-master:8088

在hdfs新建browerTest文件夹,再browerTest下新建input文件夹,然后上传input.txt,运行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /browerTest/input /yarn/output

查看结果

停止集群
sbin/stop-dfs.sh
sbin/stop-yarn.sh
参考:
hadoop文档 - 设置单节点集群
VMware 下Hadoop集群环境搭建之虚拟机克隆,Hadoop环境配置
Hadoop之SecondaryNameNode
