搭建 Hadoop 3.1.2 windows单节点安装与使用
使用管理员身份运行IDEA
添加Maven依赖,虽然hadoop-client中有hadoop-mapreduce-client-jobclient,但不单独添加,IDEA控制台日志不会打印
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.2</version>
</dependency>
添加log4j.properties到resource文件夹中
log4j.rootLogger=INFO, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%m%n
将hdfs-site.xml和core-site.xml复制到resource文件夹
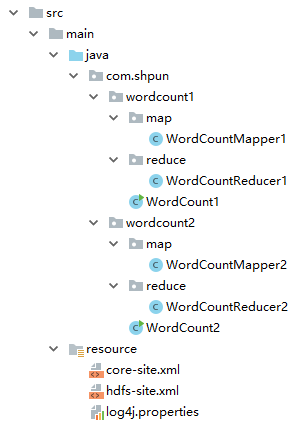
项目结构
1. WordCount V1.0
map1
public class WordCountMapper1 extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 读取一行
String line = value.toString();
// 空格分隔
StringTokenizer stringTokenizer = new StringTokenizer(line);
// 循环空格分隔,给每个计数1
while(stringTokenizer.hasMoreTokens()){
word.set(stringTokenizer.nextToken());
context.write(word, one);
}
}
}
reduce1
public class WordCountReducer1 extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 根据key对values计数
int sum = 0;
for(IntWritable intWritable : values){
sum += intWritable.get();
}
result.set(sum);
context.write(key, result);
}
}
WordCount V1.0,路径写死可直接在IDEA中run,也可以设置参数
public class WordCount1 {
public static void main( String[] args ) {
// 读取hdfs-site.xml,core-site.xml
Configuration conf = new Configuration();
try{
Job job = Job.getInstance(conf,"WordCount V1.0");
job.setJarByClass(WordCount1.class);
job.setMapperClass(WordCountMapper1.class);
job.setCombinerClass(WordCountReducer1.class);
job.setReducerClass(WordCountReducer1.class);
// job 输出key value 类型,mapper和reducer类型相同可用
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// hdfs
FileInputFormat.addInputPath(job, new Path("/hdfsTest/input"));
FileOutputFormat.setOutputPath(job, new Path("/hdfsTest/output"));
//FileInputFormat.addInputPath(job, new Path(args[0]));
//FileOutputFormat.setOutputPath(job, new Path(args[1]));
// windows 本地目录
//FileInputFormat.setInputPaths(job, "D:\\hadoop-test\\input");
//FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop-test\\output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}catch (Exception e){
e.printStackTrace();
}
}
}
可打成jar包运行,使用参数,需要增加命名空间
hadoop jar mapreduce-test-1.0-SNAPSHOT.jar com.shpun.wordcount1.WordCount1 /hdfsTest/input /hdfsTest/output
2. WordCount V2.0
map2
public class WordCountMapper2 extends Mapper<LongWritable,Text, Text, IntWritable> {
enum MapperCounterEnums{
INPUT_WORDS
}
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
// 区分大小写
private boolean caseSensitive;
// 用于存需要过滤的pattern
private Set<String> patternsToSkip = new HashSet<>();
private Configuration conf;
private BufferedReader bufferedReader;
/**
* 此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。
* 1.读取配置文件中的wordcount.case.sensitive,赋值给caseSensitive变量
* 2.读取配置文件中的wordcount.skip.patterns,如果为true,将CacheFiles的文件都加入过滤范围
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
conf = context.getConfiguration();
// 获取是否区分大小写的值
caseSensitive = conf.getBoolean("wordcount.case.sensitive",true);
// 获取是否需要过滤
if(conf.getBoolean("wordcount.skip.patterns", false)){
// 读取缓存文件,在main函数中添加
URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();
for(URI patternsURI : patternsURIs){
Path patternsPath = new Path(patternsURI.getPath());
String fileName = patternsPath.getName();
parseSkipFile(fileName);
}
}
}
/**
* 根据文件名读取每行,添加到需要过滤的set中
* @param fileName
*/
private void parseSkipFile(String fileName){
try{
bufferedReader = new BufferedReader(new FileReader(fileName));
String patternLine;
//读取文件每一行,并添加
while((patternLine = bufferedReader.readLine()) != null){
patternsToSkip.add(patternLine);
}
}catch (IOException e){
e.printStackTrace();
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = (caseSensitive) ? value.toString() : value.toString().toLowerCase();
// 过滤
for(String pattern : patternsToSkip){
line = line.replaceAll(pattern,"");
}
StringTokenizer stringTokenizer = new StringTokenizer(line);
while(stringTokenizer.hasMoreTokens()){
word.set(stringTokenizer.nextToken());
context.write(word, one);
// 定义计数器,枚举类型的名称即为组的名称,枚举类型的字段就是计数器名称
Counter counter = context.getCounter(MapperCounterEnums.class.getName(),MapperCounterEnums.INPUT_WORDS.toString());
counter.increment(1);
}
}
}
reduce2
public class WordCountReducer2 extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value : values){
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
WordCount V2.0
public class WordCount2 {
public static void main( String[] args ) {
// 读取hdfs-site.xml,core-site.xml
Configuration conf = new Configuration();
try{
// 获取参数
GenericOptionsParser genericOptionsParser = new GenericOptionsParser(conf,args);
String[] remainingArgs = genericOptionsParser.getRemainingArgs();
// 若命令为 $ bin/hadoop jar wc.jar WordCount2 /user/joe/wordcount/input /user/joe/wordcount/output
// genericOptionsParser.getRemainingArgs() 获取到的就是
// /user/joe/wordcount/input /user/joe/wordcount/output
// 若命令为 $ bin/hadoop jar wc.jar WordCount2 -Dwordcount.case.sensitive=false /user/joe/wordcount/input /user/joe/wordcount/output -skip /user/joe/wordcount/patterns.txt
// -Dwordcount.case.sensitive=false 设置不区分大小写
// genericOptionsParser.getRemainingArgs() 获取到的就是
// /user/joe/wordcount/input /user/joe/wordcount/output -skip /user/joe/wordcount/patterns.txt
if(remainingArgs.length != 2 && remainingArgs.length != 4){
System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]");
System.exit(2);
}
Job job = Job.getInstance(conf,"WordCount V2.0");
job.setJarByClass(WordCount2.class);
job.setMapperClass(WordCountMapper2.class);
job.setCombinerClass(WordCountReducer2.class);
job.setReducerClass(WordCountReducer2.class);
// job 输出key value 类型,mapper和reducer类型相同可用
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
List<String> otherArgList = new ArrayList<>();
for(int i = 0;i < remainingArgs.length;i++){
if("-skip".equals(remainingArgs[i])){
// 获取过滤文件的地址,将hdfs文件路径转成完整的路径,scheme://authority/path
URI patternURI = new Path(remainingArgs[++i]).toUri();
// 加入本地化缓存中
job.addCacheFile(patternURI);
// 需要过滤
job.getConfiguration().setBoolean("wordcount.skip.patterns", true);
}else{
otherArgList.add(remainingArgs[i]);
}
}
FileInputFormat.addInputPath(job, new Path(otherArgList.get(0)));
FileOutputFormat.setOutputPath(job, new Path(otherArgList.get(1)));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}catch (Exception e){
e.printStackTrace();
}
}
}
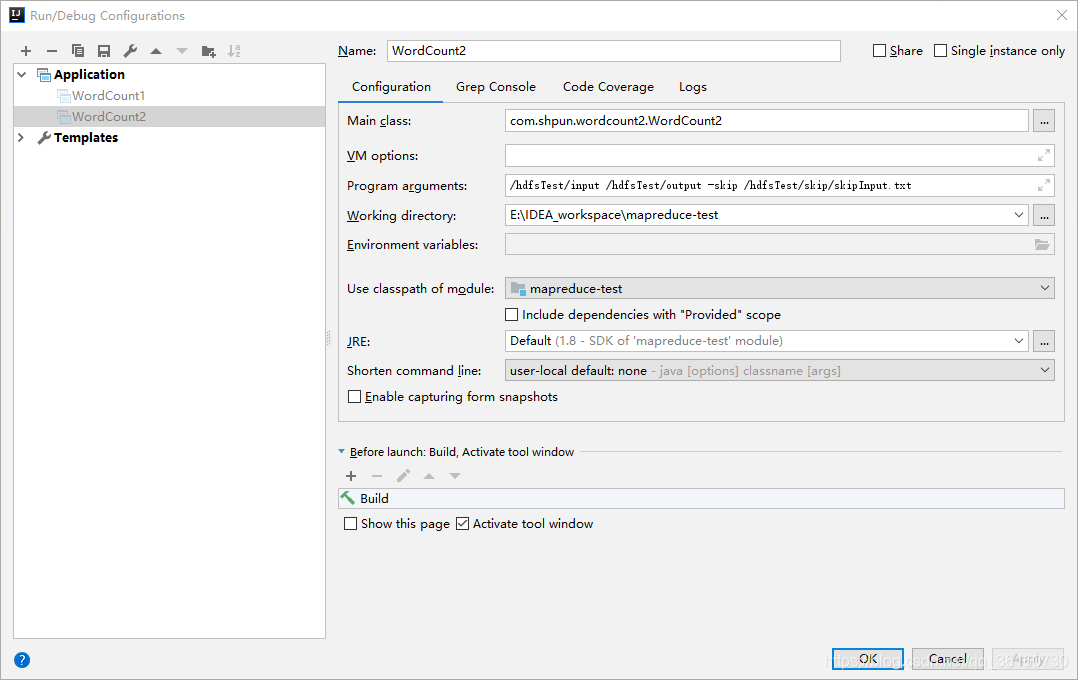
IDEA赋值参数,在Program arguments中空格间隔开
可打成jar包运行
hadoop jar mapreduce-test-1.0-SNAPSHOT.jar com.shpun.wordcount2.WordCount2 /hdfsTest/input /hdfsTest/output
hadoop jar mapreduce-test-1.0-SNAPSHOT.jar com.shpun.wordcount2.WordCount2 -Dwordcount.case.sensitive=false /hdfsTest/input /hdfsTest/output
hadoop jar mapreduce-test-1.0-SNAPSHOT.jar com.shpun.wordcount2.WordCount2 -Dwordcount.case.sensitive=false /hdfsTest/input /hdfsTest/output -skip /hdfsTest/skip/skipInput.txt
3. 坑
- 在WordCount V1.0中,在IDEA上运行时,切换注释的HDFS和Windows路径时,Maven要进行Clean再Compile,然后再Rebuild Project。不然会出现路径类型识别出错。HDFS路径识别成本地路径,Windows路径识别成HDFS路径。
参考:
hadoop MapReduce Tutorial
初识MapReduce的应用场景(附JAVA和Python代码)
自己编译WordCount编译通过执行报错
官网MapReduce实例代码详细批注
