基本信息:Dirichlet-based Histogram Feature Transform for Image Classification,作者:Takumi Kobayashi, National Institute of Advanced Industrial Science and Technology,发表于CVPR2014。
摘要:基于直方图的特征被广泛的用于图像分类,比如SIFT局 部描述子。本文针对此直方图特征提出了一种有效的变换能显著提高图像分类的正确率。该直方图特征用Dirichlet分布来表征并推导出了针对此特征变换的Dirichlet fisher核。本文所提出的方法能用很低的运算代价就能增强原始直方图特征的辨别能力。另一方面,在特征袋框架下,通过对局部描述子变换能将Dirichlet混合模型扩展为高斯混合模型,因此提出了Dirichlet-derived GMM fisher 核。在不同的图像分类任务下包括从属对象和材质纹理的识别,本方法能显著提高基于特征直方图和基于特征袋的fisher核的分类正确率,并且与当前已提出的方法具有可比性。
1. 引言
直方图特征在图像分类中扮演着重要角色。比如SIFT特征作为局部描述子,HOG特征用于用于目标检测和词袋模型,比如视觉单词直方图,在近十年中被广泛用于图像分类中。在特征袋框架下,SIFT局部描述子通常引入fisher核提高分类器性能。
通过对显著特征的计数,直方图能有效捕获特征的统计特性。另外,也能通过投票权重来衡量选择特征的重要性。在SIFT或HOG中,一般通过梯度幅值对相邻的bins进行投票来构造梯度方向直方图。并且软权重被有效的用于离散化连续的输入空间来生成直方图,比如BoW中的软编码。这种软权重降低了直方图的属性,但是在文本中BoW本质上为可计数单词的直方图。因此,直方图特征针对图像分类需要一个合适的变换生成一个有效的特征向量。
为了将特征转换为可用于图像分类的特征,一些基于统计的方法比如PCA,ICA,LDA等等都被大量应用。这些方法都是基于特定的任务基于统计准则将特征向量投影到另一个空间。另一方面,不同类型的归一化方法也被用于直方图特征的转换,比如1- 范数归一化,可以看作是直方图bins中的概率,而最常用的当属2-范数归一化和近来提出的
一般核函数或核方法都可应用于直方图特征的转换。除了高斯核被广泛应用于特征向量,还有
因此本文提出了一种高效的直方图特征转换方法。从概率角度看,1-范数归一化的特征可以看作是概率函数,可以用Dirichlet分布来表征这种概率。基于概率模型,我们推导出了对直方图特征变换的Dirichlet fisher核,不但增强了辨别能力而且不会带来特征向量维数的增加。而且该方法不需要繁琐的参数调整,并且基于SIFt描述子的统计特性。注意本文提出的方法可应用于不同类型的直方图特征,比如BoW,SIFT。
另一方面,在BoF框架下,很多的SIFT局部描述子被Dirichlet混合模型建模。我们通过特征转换将其推广到高斯混合模型,因此本文又提出了Dirichlet-derived GMM fisher核。该方法能通过低运算开销产生高效的图像特征表示用于图像分类,显著提高了分类正确率。
我们的主要贡献是:1)基于SIFT局部描述子统计的Dirichlet fisher核, 2)Dirichlet-derived GMM fisher核应用于一般的图像分类,和3)在图像分类任务中的可比性。
2. Dirichlet fisher核
我们提出了基于Dirichlet fisher核的直方图特征转换,其转换的特征向量保持相同的维度且具有辨别性,更加适合于随后的线性分类。
2.1. 定义
1-范数归一化的直方图特征
其中
其中
其中
值得注意的是基于Dirichlet fisher核产生的特征与原始特征
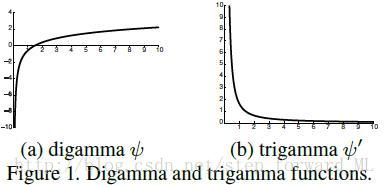
2.2. 对角逼近
在Dirichlet fisher核中,使用fisher矩阵将导致运算很高的复杂度。因此,使用下面的形式来逼近
因为trigamma函数
由单个元素操作组成。
2.3. 经验近似
在上面的式子中,参数
由于
fisher信息矩阵的对角元素为
那么这些均值和标准差可以通过训练数据
其中
这种表达形式简单和高效,且不会像核映射那样带来维度的增加。可以看作是对
2.4. 改进的对数函数
对数函数在Dirichlet fisher核中扮演重要角色,但是当

Dirichlet分布的边缘分布
其中假设
比如,图展示了SIFT局部描述子的经验分布,其中剔除了为0的特征。忽视数据集,我们可以发现边缘分布与Beta 分布相似这可以认为是SIFT局部描述子的统计特性,类似于自然场景图像的统计特性。基于这种分布,我们给出
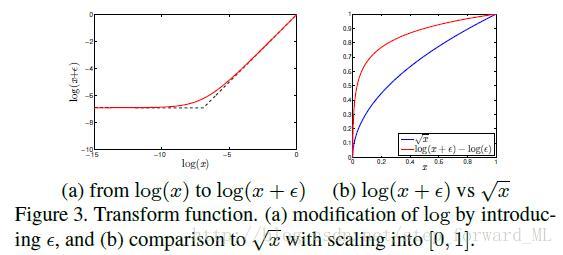
将
被转换的SIFT特征的经验分布如图所示。函数
2.5. 讨论
Dirichlet fisher核与tf-idf类似。粗略的,digamma函数
其中
这有些tf-idf的形式。除了常量
Dirichlet fisher核与Polya Fisher核类似,其中Polya Fisher核用于文本分类和视觉分类。Polya模型计数突发特性的单词通过Dirichlet 和多项式分布。因此,非常适用于BoW直方图的转换,但是不利于投票权重,比如SIFT/HOG。相比较而言,提出的方法适用于不同类型的特征。另外,Polya方法必须学习超参数,而这个过程在高维直方图特征下是非常耗时的。
3. 基于特征袋fisher核的扩展
在第二节,我们提出了Dirichlet fisher核用于单个的直方图特征。而这一节在特征袋框架下将其扩展到基于特征袋fisher核的方法,被证明了在图像分类中的显著效果。
特征袋表示图像中在不同尺度下的局部描述子的集合。假设我们使用基于直方图的局部描述子,比如SIFT,而通过前面介绍的Dirichlet分布来建立模型。
3.1. Dirichlet混合模型(DMM)
直接使用DMM来描述局部描述子。
其中
注意DMM fisher核的第k部分是D维向量因为Dirichlet模型只包含参数
3.2. Dirichlet推导的GMM
我们通过式子
其中
其中
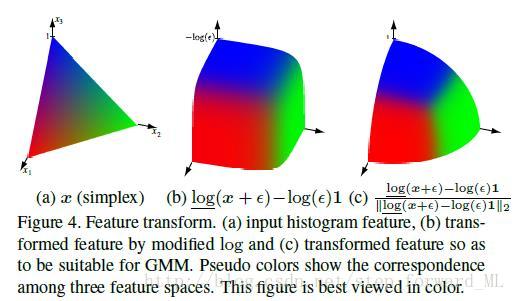
相比GMM建模局部描述子有以下优势。第一,von mises fisher核,推导与Dirichlet分布,是关于圆心对称并且不能用于表征各向异性的分布,然而高斯模型能充分利用方差。第二,GMM fisher 核能产生两种类似于均值和方差的特征,那么维数为DMM fisher 核的两倍。DMM fisher核类似于提出的基于均值的fisher核
其中
从SIFT描述子转换这个角度看,我们的方法与RootSIFT相似,同样被用于fisher核。RootSIFT是SIFT通过L2-Hellinger归一化。在RootSIFT 中,对特征中较小值周围的偏差将会通过均方根操作增强,
4. 实验结果
我们使用线性SVM分类器来评估提出方法的分类正确性。注意
4.1. 与梯度方向直方图的联合
提出的Dirichlet fisher核(2.1节)用于局部自动相关梯度(GLAC)的转换用于行人的检测。这特征使用联合无计数投票权重的局部梯度方向直方图,而对于Polya模型无能为力。
Daimler-Chrysler行人。该任务是将局部块(
正如2.4节所示,在行人与非行人数据集上的经验特征分布导致一定偏差的相同分布,
分类结果与比较如图所示。图展示了通过ROC与EER测定的分类正确率。可以看出本文提出的方法在性能上超越了其它归一化方法。但需注意的是kernel map方法通过将特征维数增长7倍来达到了高的分类正确率,但是本文方法在不增加特征维数下降低了运算消耗。

4.2. 词袋直方图
我们下一步将运用Dirichlet fisher核与基于统计单词个数的BoW特征,在PASCAL-VOC2007数据集上进行测试。
SIFT局部描述子通过步长为4像素和3个尺度密集采样,并通过k-means算法在训练数据集上构造了16384个视觉单词。将每一副图像分为3个层次的子区域并分别计算BoW特征,在连接起来构成该图像的特征表示,并最终通过SVM进行分类。
PASCAL-VOC2007。该数据集包含20个不同类别,并具有不同的视觉效果,位置和各种复杂的背景。我们建立与标准的VOC评估相同的实验环境。
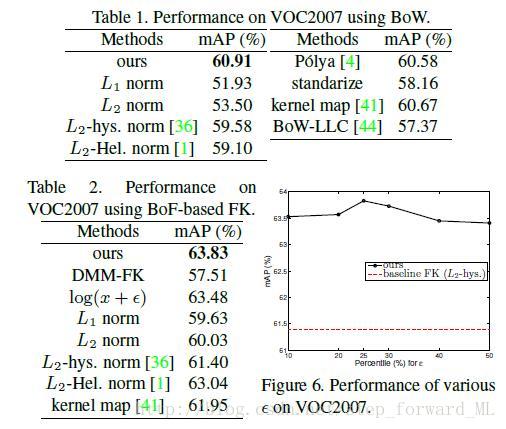
比较结果如表所示,同样验证了提出方法的优越性,但略微比Polya模型高,尽管我们的方法不但能适用于BoW还适用于不同类型的直方图特征。为了比较,本文方法同样略微超越了LLC。
4.3. 在特征袋框架下的fisher核
我们也将Dirichlet推导的GMM fisher 核用于不同类型的图像分类任务,目标识别,目标分类,场景归类,遥感图像分类和材料分类。实验搭建类似于4.2节,除了K=256。
我们从不同角度分析了提出方法在VOC07数据集上的性能,并与DMM fisher 核和其他的转换方法。在这种情况下,L2-hysteresis归一化为基准的fisher 核,L2-hellinger归一化为RootSIFT。比较结果如表所示。DMM-FK表现最次是由于其只对应均值部分,而GMK-FK使用变换
我们还验证了
提出的方法在VOC07数据集上能达到63.83\%,优于该数据集上的冠军59.4\%和当前最优的63.5\%,然而此最优的方法在目标检测时很耗时。
在以下不同数据集上的实验,提出的基于Dirichlet GMM FK与其他不同类型的归一化方法及当前效果最优的方法进行比较。
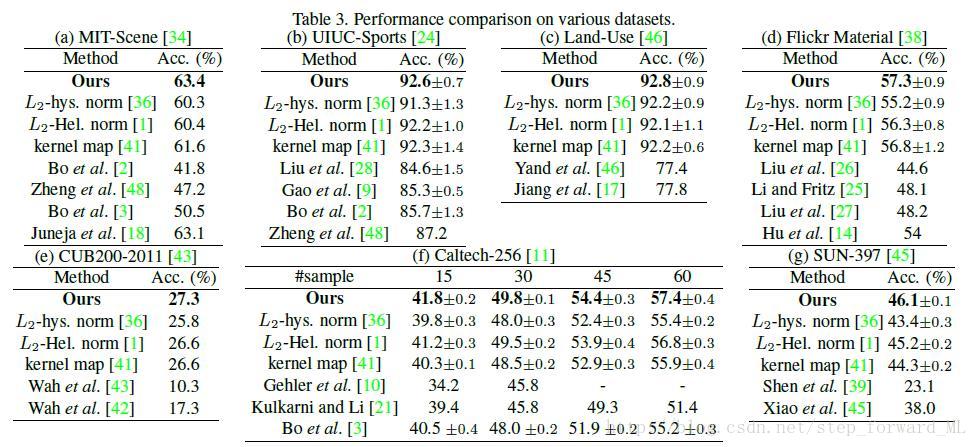
MIT-Scene。该数据集包含67类在不同的屋内场景下的共15620副大的类内方差/小的类间方差图像。我们在方法相同的环境下测试其分类正确率。
UIUC-Sports。基于图像的分类,包含大的位置,尺寸偏差并且在同类别下具有不同的背景。
Land-Use。从USGS上下载的21类不同的地物图像。每一类别包含100副
Flickr Material。10个类别1000副图像并且附带人工标记的目标位置。我们在前景上提取局部的sift描述子作为材料识别的二值掩模。
CUB200-2011。这是一个挑战性的数据集,包含200个品种的鸟用于物体识别。
Caltech-256。该数据集包含256类别共30607副图像。针对目标位置,尺寸,位置有着很大的差异性,因此使得目标识别具有挑战性。我们随机选取每一个类别中15,30,45,60作为训练图像,50作为测试图像。
SUN-397。包含397个不同场景类别共100K图像,囊括了不同的视觉场景。它任然是一个挑战性的数据集因为当前性能最好的AMT达到平均正确率为68.5\%。我们同样选取50幅图像作为训练,50作为测试。
这些数据集上的分类结果如表所示。提出的方法相较其他方法具有可比性。对于L2-hellinger归一化,性能提升
5. 结论
我们提出直方图特征转换方法能显著提升分类性能。将基于1-范数归一化的直方图特征作为概率函数通过Dirichlet分布进行建模,在此基础上我们推导了Dirichlet fisher核单独用于直方图特征转换和用于特征袋框架下的Dirichlet GMM fisher核。提出的方法不需要繁琐的参数调整,只取决于特征的统计特性。在实验中,提出的方法能大幅提升基于直方图的特征和基于BoF的fisher 核。