HashSet:
HashSet顾名思义,是与hash值有密切关联的一种集合。特点是元素唯一,无序。HashSet是对HashMap的一层封装,HashMap它可以看成是一个一维数组,而一维数组里的元素又是一个单链表,类似下图所示:
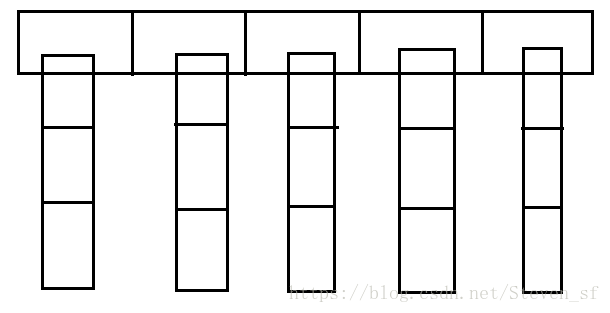
HashMap是如何保证元素唯一的呢?是根据元素的hash值以及调用equals()方法实现的。HashMap在添加元素时,首先会先计算元素的hash值,得到的结果作为一维数组的索引,然后会去调用equals()方法,来比较元素的值是否相同,如果相同,则表示同一个对象,不再添加进去,这样就保证了HashMap的唯一性,对HashSet的函数调用都会转换成合适的HashMap方法,不再赘述HashSet了。
注:这里计算处理的hash值只是类似于数组的索引,不一定就是数组的索引,这样只是便于理解。在new HashMap的时候,建议指定大小,因为如果使用默认的大小,当元素填满时,会自动扩容,这时会重新计算hash值,占用大量资源,影响效率。
TreeSet:
TreeSet是一种树形结构,是一种红黑树,这是一种近似平衡的二叉树。TreeSet除了具有HashSet的唯一性之外,它还具有有序性。同样,TreeSet是对TreeMap的一层封装,所以,在这里介绍一下TreeMap的原理。
TreeMap保证元素唯一的特点与HashMap相似,这里不再赘述。简单介绍一下如何做到有序的。前面说到,TreeSet是对TreeMap的一层封装,所以,TreeMap也是一个红黑树,在添加元素时,有可能会破坏树的平衡,这时会自动的做相应的旋转,来保持树的平衡。就类似于天平那样,要保证这颗树平衡。保证平衡的规则就是:父节点的值要比左子树的值大,比右子树的值小。如果添加进来的一个元素破坏了这种平衡,就会自动左相应的调整,从而保证元素的有序性。对TreeSet的函数调用都会转换成合适的TreeMap方法,所以这里也不再赘述TreeSet了。
注: TreeSet在添加元素时,元素必须有可比较性。由于基本类型的包装类以及String类已经重写了hashCode()和equals()方法,所以可以直接添加,如果添加的是自定义实体类的话,必须要实现Comparable接口,或者自定义一个比较器,实现Comparator接口,才能添加进去。
以上内容仅代表个人观点!
HashSet和TreeSet集合学习总结
猜你喜欢
转载自blog.csdn.net/Steven_sf/article/details/80336297
今日推荐
周排行