ONE.Set集合
one.Set集合的特点
无序,唯一
TWO.HashSet集合
1.底层数据结构是哈希表(是一个元素为链表的数组)
2.那么HashSet如何来实现元素的唯一性的呢?
通过一HashSet添加字符串的案例查看HashSet中add()的源码,看为什么相同的字符串没有被加入HashSet中
interface Collection {
...
}
interface Set extends Collection {
...
}
class HashSet implements Set {
private static final Object PRESENT = new Object();
private transient HashMap<E,Object> map;
//1.从这一步我们可以看出来,HashSet()其实使用HashMap()实现的
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) { //e=hello,world
//2.add()方法的内部也是HashMap的实例对象调用方法,这里e是被添加的对象,而PRESENT是一个
private static final Object PRESENT = new Object();对象。
return map.put(e, PRESENT)==null;
}
}
class HashMap implements Map {
//3.来到HashMap实现的put方法
public V put(K key, V value) { //key=e=hello,world
//4.看哈希表是否为空,如果空,就开辟空间
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//5.判断对象是否为null
if (key == null)
return putForNullKey(value);
//6_1.调用hash()方法,通过查看这个方法我们知道这个方法的返回值和对象的hashCode()方法相关
int hash = hash(key);
//7.在哈希表中查找hash值
int i = indexFor(hash, table.length);
//8.这里for循环的的初始条件是把table[i]赋值给e,如果在哈希表中找不到这个hash值得话,
就不会进入for循环比较,如果有的话,就会进入比较
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//9.如果hash值一样(说实话,这一步每太看懂,既然能够查询到,说明两者的hash值必然相等),
并且地址值或者equls一样的话,不会添加进来
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
//走这里其实是没有添加元素
}
}
modCount++;
//9.把元素添加
addEntry(hash, key, value, i);
return null;
}
transient int hashSeed = 0;
//6_2.这是HashMap中的hash方法,从这个方法的实现我们可以看出,这个方法的唯一变量是
hashCode()
final int hash(Object k) { //k=key=e=hello,
int h = hashSeed;//这个值默认是0
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode(); //这里调用的是对象的hashCode()方法
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}HashSet其实是用HashMap()来实现的,HashMap()是Map接口的实现类
调用HashSet的add()方法其实就是调用HashMap()中的put(),put()中主要涉及到两个方面
1).对象的hash值,通过调用hash()得到,这个方法是由hashCode()经过操作实现的,由hashCode()的值控制
2).创建了哈希表,哈希表会将每一个hash值收入
然后比较的方式是
A.先在hash表中查找看是否有这个hash值(第一次比较,看hash表中是否有当前元素的hash值(这个值有hashcode操作的得到)),如果没有,直接将这个hash值对应的对象添加到HashSet中,如果有还要进行第二次比较
B.如果hash表中有这个hash值,那么获取表中的这个hash对应的对象,如果这两个对象的地址值(e.key == key)或者key.equal(e.key)。(第二次比较,如果两个对象的hash值相同,还是不能认为是同一个对象,还要比较两个对象的地址值,或者是equals(),这里是一个||,只要有一个满足相等,就可以认为是同一个元素,不添加
3.现在可以回答开始的问题,为什么存储字符串的时候,字符串相同的时候,只存储了一个了,原因是String类中重写了hashCode()和equals()而String类的hashcode值和equals结果都是由字符串的内容决定的
我们来看一下String类中的hashCode()和equals()方法
1) public int hashCode()返回此字符串的哈希码。
String 对象的哈希码根据以下公式计算:
s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
使用 int 算法,这里 s[i] 是字符串的第 i 个字符,n 是字符串的长度,^ 表示求幂。(空字符串的哈希值为 0。)
2)public boolean equals(Object anObject)将此字符串与指定的对象比较。
当且仅当该参数不为 null,并且是与此对象表示相同字符序列的 String 对象时,结果才为 true。
所以当对象是String类型的时候,地址值(可能相等(字符串常量池知识点)),equals方法必然相等,所以不会加入
4.如果HashSet中收入的是自定义对象,那如何实现唯一呢?
1)通过上面String类的分析,我们知道,HashSet中实现唯一的两个比较,先是比较hash值(这个值由hashcode值控制),如果这个值相同,那么再比较地址值或者equals(),所以我们可以通过重写hashCode()和equals(),来实现对自定义对象的唯一性判断
2)这里开始的想法是,其实只要重写了equals,让这个方法比较的是对象的内容,那么就可以排除掉相同的对象
所以让hashCode()返回一个常数,这样hash就相等了,然后通过equals判断
但是这样会导致每一个新对象都要和老对象进行比较,太麻烦,所以我们可以仿照String类中对hashCode()重写的方式,同样的有对象的成员变量来决定这个对象的hashcode值,equals方法也是通过比较对象的成员变量
是否相等。这样我们就得到了最后的结论,其实eclipse提供了自定义类重写这两个方法的最终版本
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}3)开发的时候,代码非常的简单,自动生成即可。
THREE.TreeSet集合
1:底层数据结构是红黑树(是一个自平衡的二叉树)
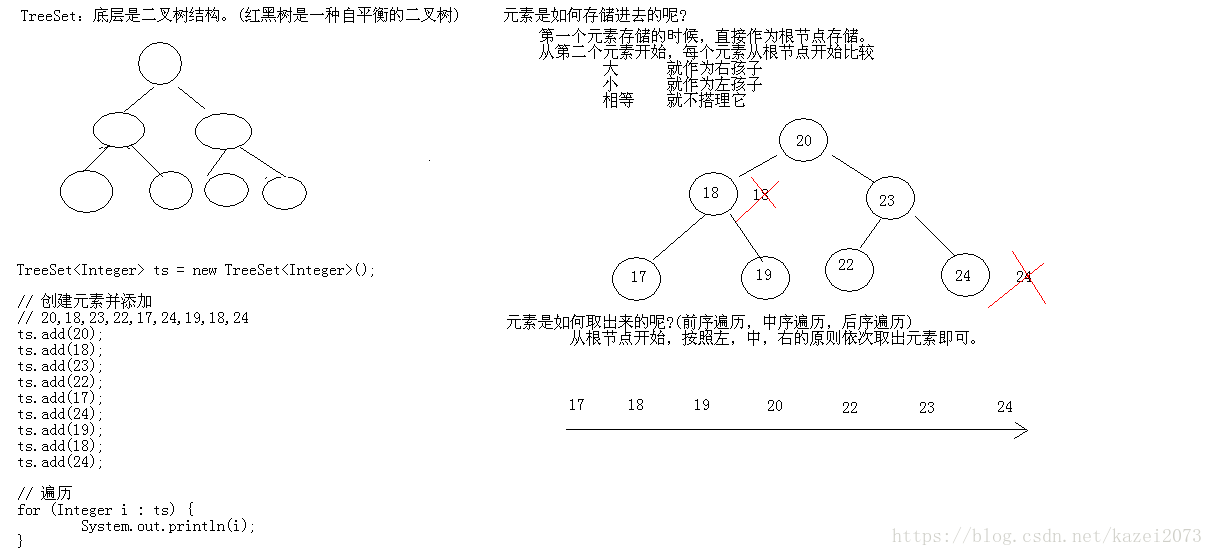
2:TreeSet底层是如何保证元素的排序方式,和元素的唯一性呢
同样的我们来看看看TreeSet的源码
interface Collection {...}
interface Set extends Collection {...}
interface NavigableMap {
}
class TreeMap implements NavigableMap {
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
}
class TreeSet implements Set {
private transient NavigableMap<E,Object> m;
public TreeSet() {
this(new TreeMap<E,Object>());
}
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
}
真正的比较是依赖于元素的compareTo()方法,而这个方法是定义在 Comparable里面的。
所以,你要想重写该方法,就必须是先 Comparable接口。这个接口表示的就是自然排序。根据源码,我们知道,TreeSet的底层代码可以通过两种方式来实现其元素的唯一性和有序
a:自然排序(元素具备比较性)
让元素所属的类实现Comparable接口,重写其中的compareTo方法
package cn.itcast_03;
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student s) {
int num = 0;
num = this.age - s.age;
int num2 = num == 0 ? this.name.compareTo(s.name) : num;
return num2;
}
}b:比较器排序(集合具备比较性)
让集合构造方法接收Comparator的实现类对象,在实现类中重写compare()方法
这种方法通过调用集合的带参构造来实现比较
public TreeSet(Comperator comparator)//比较器排序
Comperator 是一个接口,把接口作为参数其实就是需要这个接口的实现类的对象
通过API我们可以得知这个接口中方法的格式,另外,这种需要一个接口的实现类的对象作为参数的情况,开发中我们常常使用匿名内部类的格式
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
public int compare(Student s1,Student s2) {
//注意这个三目比较,赋值的优先级最小,==最大,三目中间
int num = s1.getName().length() - s2.getName().length();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
});3.需要注意的问题
1)根据对源码和底层数据结构红黑树的理解,我们知道无论是通过自然排序还是通过比较器排序,数据结构核心是通过将根节点和子节点比较,在红黑树的默认方法中,小的为左儿子,大的为右儿子,实现一颗平衡二叉树,而代码的体现是将成员变量进行某种比较得到一个int值,如果值大于1,就放右边,如果值小于1就放左边,如果值相等就不放入,通过这个int值来完成元素的收集
2)我们在考虑这个值的时候,对于大于,小于,相等的条件设定常常使用三目运算符来做判断,熟练使用这一三目运算符
//如果按照正常的二叉排序,那么会先输出小的,而我们要求先输出分高的,所以,可以将全部的s1,s2交换顺序
//就可以达到总分大的放左边(先输出),然后单科权重是语文——数学——英语
int num = s2.getSum() - s1.getSum();
int num2 = num ==0 ? s2.getChineseScore() - s1.getChineseScore() : num;
int num3 = num2 == 0 ? s2.getMathScore() - s1.getMathScore() : num2;
int num4 = num3 == 0 ? s2.getEnglishScore() - s1.getEnglishScore() : num3;
return num4;FOUR.Collection集合总结(掌握) Collection
|--List 有序,可重复
|--ArrayList
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高
|--Vector
底层数据结构是数组,查询快,增删慢。
线程安全,效率低
|--LinkedList
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高
|--Set 无序,唯一
|--HashSet
底层数据结构是哈希表。
如何保证元素唯一性的呢?
依赖两个方法:hashCode()和equals()
开发中自动生成这两个方法即可
|--LinkedHashSet
底层数据结构是链表和哈希表
由链表保证元素有序
由哈希表保证元素唯一
|--TreeSet
底层数据结构是红黑树。
如何保证元素排序的呢?
自然排序
比较器排序
如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
4:针对Collection集合我们到底使用谁呢?(掌握)
唯一吗?
是:Set
排序吗?
是:TreeSet
否:HashSet
如果你知道是Set,但是不知道是哪个Set,就用HashSet。
否:List
要安全吗?
是:Vector
否:ArrayList或者LinkedList
查询多:ArrayList
增删多:LinkedList
如果你知道是List,但是不知道是哪个List,就用ArrayList。
如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。
如果你知道用集合,就用ArrayList。
5:在集合中常见的数据结构(掌握)
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序