这篇文章是对自己学习的一个总结,学习资料是疯狂Java讲义第三版,李刚编,电子工业出版社出版。
注:本文只是对HashSet,TreeSet,LinkedHashSet和EnumSet中常使用到的方法进行总结,以及对他们的性质做总结。
这三个是继承Collection,Collection的常用方法在这个博客里面https://blog.csdn.net/sinat_38393872/article/details/90904958
先说一下HashSet的三个特点
- 排列顺序和添加顺序不一致
- 非同步集合:如果保持同步的话要手动添加代码
- 集合元素可以是null
说一下HashSet存储元素的过程。HashSet是在Set的基础上加上了Hash表的特性,所以HashSet的唯一有点就是存储和查找过程很快,时间开销是常数级。HashSet存储时,会调用存储存储对象的hashCode()方法获取hashCode,然后根据hashCode得到该存储对象的存储位置。
如果有两个元素值相等但是hashCode不相等,那么hashSet认为这两个是不同的元素。所以想要使用hashSet存储某个自定义类对象时,不仅要对equals()方法覆写,还要对hashCode()方法覆写。下面讲一下hashCode()的覆写规则。
假如我们的value有多个,根据value的类型,对应的hashCode的计算方式也不一样,下面是计算规则,设f就是value的值
| 实例变量类型 | 计算方式 |
| boolean | hashCode = (f ? 0 : 1) |
| byte, short, char, int | hashCode = (int) f |
| long | hashCode = (int) (f^(f>>>32)) |
| float | hashCode = Float.floatToIntBits(f) |
| double | long l = Double.doubleToLongBits(f); hashCode = (int) (l ^ (l >>> 32)); |
| 引用类型 | hashCode = f.hashCode() |
得到各value的hashCode之后,将这些hashCode乘以不同的数字再相加,最后得到的数就是要返回的hashCode。
比如我们自定义一个类
class A{
int value1;
long value2;
}这个类A的hashCode是要通过value1和value2计算出来的。那么根据上面的规则,value1和value2的hashCode如下代码
hashCode1 = value1;
hashCode2 = (int) (value2 ^ (value2 >>> 32));最终返回的hashCode就应该是
return ((hashCode1 << 5)- hashCode1) + ((hashCode2 << 3) - hashCode2); //乘31和乘7是随机选
//的两个数,也可以选其它的数字,只要是两个不同的质数就行完整代码如下
class A{
int value1;
long value2;
public int hashCode(){
hashCode1 = value1;
hashCode2 = (int) (value2 ^ (value2 >>> 32));
return ((hashCode1 << 5)- hashCode1) + ((hashCode2 << 3) - hashCode2);
}
}各自的value计算出对应hashCode后还要乘以不同质数相加的原因是,为了防止明明关键字不同,但相加结果恰好相等这样的情况。比如一个存储对象有两个value计算出的哈希值分别是1和2,另一个存储对象的两个value计算出的哈希值分别是2和1,这两个对象不一样计算出来的哈希值应该要不一样才对,直接相加的话就错了,所以要分别乘上不同的数,这样可以有效防止这样的情况发生。至于为什么要乘以质数,我还想不明白,最好先和书上写的保持一致。
现在开始将LinkedHashSet
LinkedHashSet没什么好讲的,只有它的性质值得提一下。
LinkedHashSet内部也是根据hashCode()来存储的,但是它内部是用链表进行维护的,所以性能略低于HashSet。但是遍历元素的时候比HashSet强。
现在是TreeSet的环节
TreeSet是自动排序的集合,和一般的Set相比,它还提供了更多的方法
Comparator comparator()如果TreeSet采用的是自定义的排序方法,那么这个方法返回的是自定义的comparator。如果是使用默认排序方式,那么返回的是null。
Object first();
Object last();分别是返回第一个和最后一个元素
Object lower(Object e);
Object higher(Object e);
分别是返回位于指定元素之前和之后的元素。其中的e可以不是TreeSet中的元素,e只是一个参照。
SortedSet subSet(Object fromElement, Object toElement)返回Set的子集,范围是从fromElement(包含)到toElement(不包含)。注意,这里返回的不是一个新的集合,只是源集合的一个View,一个视图,一个投影,Java文档里是这样写的
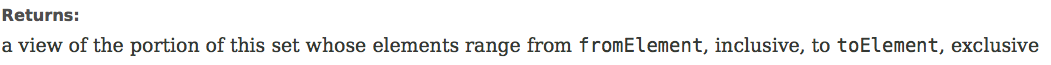
![]()
这意味着你改变这个子集的话,在源集合中也会遭受同样的改变。
代码验证如下
public class test{
public static void main(String[] args){
TreeSet c = new TreeSet(); //c是源集合
c.add(1);
c.add(2);
c.add(3);
c.add(4);
c.add(5);
//现在c中的元素是(1,2,3,4,5)
SortedSet a = c.subSet(1,3);
//a是(1,2)
a.remove(2);
//删除a中的[2]之后,源集合中的[2]也应该被删除了
Iterator it = c.iterator();
while(it.hasNext()) {
System.out.print(it.next() + " ");
}
}
}这段程序的输出是

这就验证了上面所说的内容。下面开始讲其它方法
SortedSet headSet(Object toElement); //小于
SortedSet tailSet(Object toElement); //大于等于分别是返回小于指定元素和大于等于指定元素的子集,返回的也是投影。
-
TreeSet定制排序
TreeSet是排序的一个集合,默认情况下是根据系统的compareTo(Object obj)方法进行排序。我们不想用默认方法想用定制方法是就要自定义排序规则,下面讲解如何自定义排序规则。
TreeSet排序是根据compareTo(Object obj)来排的,所以自定义排序规则时我们只要让欲添加到TreeSet里排序的元素继承Comparable接口,覆写其中的compareTo(Object obj)和equals(Object obj)方法即可。代码示例如下。
//我们要将A添加到TreeSet,就要对A添加排序规则。
class A implements Comparable{
private int value;
private String string;
A(int value, String string){
this.value = value;
this.string = string;
}
public int getValue() {
return value;
}
//两个A的对象相等的标准应该是值相等,即value和string都相等
public boolean equals(Object obj) {
if(this == obj) {
return true;
}
if(obj != null && obj.getClass() == A.class) {
A a = (A) obj;
if(a.value == this.value) {
if(a.string.equals(this.string)) {
return true;
}
}
}
return false;
}
//这里设定比较的规则是先比较value,value相等的情况再比较字符串
@Override
public int compareTo(Object obj) {
A a = (A) obj;
if(this.value > a.value) return 1;
if(this.value < a.value) return -1;
if(this.value == a.value) {
int result = this.string.compareTo(a.string);
if(result > 0) return 1;
if(result < 0) return -1;
}
return 0;
}
}现在开始讲EnumSet类
EnumSet是专门为枚举类设计的集合,集合内的元素是有序的,以枚举值在Enum类中的定义顺序相同。
Enum内部以位向量的形式存储,所以Enum占用的空间非常小,而且运行效率非常高。
Enum没有任何构造器来创建类的实例,程序只能通过Enum的类方法来创建实例。类方法如下所示。
EnumSet allOf(Class elementType) //创建一个包含指定枚举类里所有枚举值的EnumSet集合。
EnumSet complementOf(EnumSet s) //创建一个其元素类型和指定EnumSet里元素类型相同的EnumSet集合,新的