文章目录
普通查询语句
select 字段名1 as 别名1,字段名2 as 别名2 ... from 表名 [约束];
其中字段名代表表中的列名。
常用字段
常用字段经常出现在查询中,包括like,distinct,between and,in,is null等。
like(模糊查询)
模糊查询一般和通配符使用,通配符一般有2种,百分号(%)和下划线(_)。
- 百分号(%)代表任意多个字符,包括0个字符。
- 下划线(_)代表任意一个字符。
例子:
- 查找名字包含t的员工。
select * from employee where name like '%t%';
- 查找名字第二个字符为t的员工。
select * from employee where name like '_t%';
\与escape(转义字符)
在字符串中,某些序列具有特殊含义。这些序列均用反斜线(‘\’)开始,即所谓的转义字符。MySQL识别下面的转义序列
转义字符的为\,如果想替换转义字符可以使用escape关键字。
| 字符 | 含义 |
|---|---|
| \0 | ASCII 0(NUL)字符 |
| \’ | 单引号 |
| \" | 双引号 |
| \b | 退格符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | tab字符 |
| \\ | 反斜线字符 |
| \% | ‘%’字符 |
| _ | ‘_’字符 |
例子:
- 查找名字第二个字符为_的员工。
select * from employee where name like '_\_%';
同时也可以使用escape来替换转义字符。
select * from employee where name like ’_$_%’ escape ‘$’;
between and
一般加在where中,表示变量在某范围之间。
例如:
- 查找姓名在[20,30]岁的的员工。
select * from employee where age between 20 and 30;
- 等价于
select * from employee where age >= 20 and age <=30;
in
一般加在where中,表示变量在某个有限集合内。
例如:
- 查找姓名在集合(10,20,30)中的的员工。
select * from employee where age in (10,20,30);
- 等价于
select * from employee where age=10 or age=20 or age=30;
null
- 比较字符 ‘=’’>’ ‘<’ ‘<>’是不能用于查询null。如果需要查询空值(null),需使用is null 和is not null。
- 空值(null)是不能参与任何计算,因为空值参与任何计算都为空。所以,当程序业务中存在计算的时候,需要特别注意。如果非要参与计算,需使用ifnull函数,将null转换为”才能正常计算。
- null是尚未定义的值,表示未知。而”确定为一个空字符串。所以未知的值,无法进行各种比较(大于,小于,等于),也不能用于计算(加减乘除)。
例如:
- 查找年龄非空的的员工。
select * from employee where age is not null;
order by(排序查询)
该字段可以将结果集中的查询结果按照顺序排序。
- order by 字段 [asc] 按照字段升序排序输出。
- order by 字段 [desc] 按照字段降序排序输出。
例如:
- 查找所有员工,按照年龄降序排序。
select * from employee order by age desc;
limit(限制输出结果)
该字段可以查询结果集中的前几条信息,一般搭配order by使用。
例如:
- 查找所有员工,按照年龄降序排序,且显示前10条信息。
select * from employee order by age desc limit 10;
- 查找所有员工,按照年龄降序排序,且显示前6-15条信息。
select * from employee order by age desc limit 5,15;
- 查找所有员工,按照年龄降序排序,且显示前6-最后1条信息。
select * from employee order by age desc limit 5,-1;
常用函数
常用函数分为单行函数和分组函数。
单行函数
最常见的普通函数,输入+输出。
字符函数
对字符串操作常用函数。
| 函数 | 作用 |
|---|---|
| lenth(str) | 返回字符串的长度 |
| concat(str1,str2,…) | 拼接字符串 |
| upper(str) | 将字符串所有字符大写 |
| lower(str) | 将字符串所有字符小写 |
| substr(str,pos,len) | 截取str从pos开始的len字符长度的字符串(索引从1开始) |
| instr(str1,str2) | 返回str2在str1中起始索引 |
| trim(str) | 去掉前后空格 |
| trim(str1 from str) | 去掉前后指定字符串str1 |
| lpad(str,len,char) | 用指定字符(char)左填充指定长度(len) |
| rpad(str,len,char) | 用指定字符(char)右填充指定长度(len) |
| replace(str1,str2,str3) | 在str1中将所有str2的子字符串替换成str3 |
数学函数
常用对数值型数据进行操作的函数。
| 函数 | 作用 |
|---|---|
| round(num,n) | 四舍五入,保留n位 |
| truncate(num,n) | 截断n位 |
| ceil(num) | 向上取整 |
| Floor(num) | 向下取整 |
| Mod(a,b) | a%b |
日期函数
常用对数日期进行操作的函数。
-
字符串转时间类型
str_to_date(日期字符串,解析格式)
例子:
str_to_date(1997-10-23 10:10:10,%Y-%m-%d %H:%i:%s) -
时间类型转字符串
date_format(日期,转换出来的字符串格式)
例子:
date_format(date,%Y-%m-%d %H:%i:%s) -
日期格式符
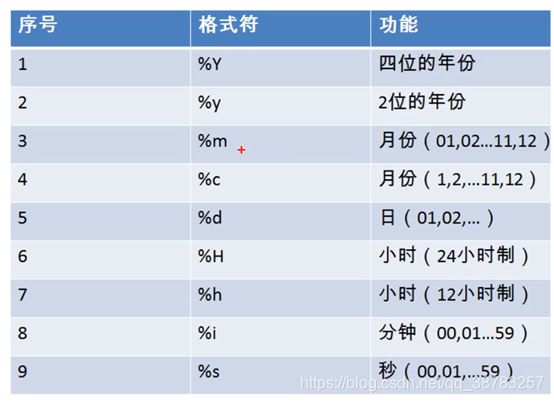
-
常见函数
| 函数 | 作用 |
|---|---|
| now() | 返回当前时间类型 |
| curdate() | 返回当前日期 |
| curtime() | 返回当前时间 |
| year(data) | 输入时间类型,返回当前年份(int) |
| month(data) | 输入时间类型,返回当前月份(int) |
| day(data) | 输入时间类型,返回当前天数(int) |
| hour(data) | 输入时间类型,返回当前小时数(int) |
| minute(data) | 输入时间类型,返回当前分钟数(int) |
| second(data) | 输入时间类型,返回当前秒数(int) |
流程控制函数
- if 函数
if(condition, value_if_true, value_if_false)
| 参数 | 描述 |
|---|---|
| condition | 必须,判断条件 |
| value_if_true | 可选,当条件为true值返回的值 |
| value_if_false | 可选,当条件为false值返回的值 |
- ifnull(expression, alt_value)
| 参数 | 描述 |
|---|---|
| expression | 必须,要测试的值 |
| alt_value | 必须,expression 表达式为 NULL 时返回的值 |
- case
case
when 条件1 then 要显示的内容1
when 条件2 then 要显示的内容2
when 条件3 then 要显示的内容3
...
else 要显示的内容
end
例子:
select salary,
case
when salary<5000 then '低'
when salary>=5000 and salary<30000 then '中'
else '高'
end
from employee
分组函数
作为统计使用,将多行的结果聚合成一行。
| 函数 | 作用 |
|---|---|
| sum(列名) | 求和,忽略nul |
| avg() | 求平均值,忽略null |
| min() | 求最小值,忽略null |
| max() | 求最大值,忽略null |
| count() | 计算不为null的个数 |
- count(1)和count(*)的区别
myisam存储引擎下,count()效率高
innode存储引擎下,count()和count(1)一样
分组查询
在进行分组统计时会用到分组查询,比如按部门统计人数、按工种统计工资情况等。分组查询一定会使用到分组函数,也一定会用到group by子句。
select 分组函数,列(必须出现在group by后面)
[where condition]
from 表
group by 列
having 分组后筛选条件
[order by]
[limit]
例子:
- 统计部门的人数大于2的部门
select count(*), department
from employee
group by department
having count(*)>2.
注意:
- 分组前筛选:用where,对原始表筛选。
- 分组后筛选:用having,对分组后表进行筛选。
联合查询
在查询时有时候我们需要对多张表的不同字段进行查询,这时候就要进行联合查询。
举例说明:
现有2张表,一张gril表,一张boy表。
- girl表
| id | name | age | boyid |
|---|---|---|---|
| 0 | 王昭君 | 19 | 2 |
| 1 | 花木兰 | 18 | 1 |
- boy表
| id | name | age |
|---|---|---|
| 0 | 程咬金 | 13 |
| 1 | 兰陵王 | 25 |
| 2 | 李白 | 22 |
内连接
inner join子句将一个表中的行与其他表中的行进行匹配,并允许从两个表中查询包含列的行记录。
使用inner join子句注意点:
- 在from子句中指定主表。
- 表中要连接的主表应该出现在inner join子句中。理论上说,可以连接多个其他表。 但是,为了获得更好的性能,应该限制要连接的表的数量(最好不要超过三个表)。
- 连接条件或连接谓词。连接条件出现在inner join子句的on关键字之后。连接条件是将主表中的行与其他表中的行进行匹配的规则。
INNER JOIN子句的语法如下:
select column_list
from 表1
inner join 表2 on join_condition1
inner join 表3 on join_condition2
...
[where where_conditions];
其中join_condition可以是多个条件,比如 gril.boyid=boy.id and gril.age=boy.age。本质其实就是两表做笛卡尔积,保留满足条件的信息。
根据join_condition的不同又分为等值连接、非等值连接、自然连接。
等值连接
join_condition中是等值条件的,比如gril.boyid=boy.id。
例子:
- 查询所有女生对应的男朋友所有信息。
select g.name as gril_name,b.name as boy_name
from gril as g
inner join boy as b on g.boyid=b.id;
最终结果:
| gril_name | boy_name |
|---|---|
| 王昭君 | 李白 |
| 花木兰 | 兰陵王 |
非等值连接
join_condition中是非等值条件的,比如gril.age<boy.age。
- 将所有男生年龄大于女生配对。
select g.name as gril_name,b.name as boy_name
from gril as g
inner join boy as b on g.age<b.age;
最终结果:
| gril_name | boy_name |
|---|---|
| 王昭君 | 兰陵王 |
| 王昭君 | 李白 |
| 花木兰 | 兰陵王 |
| 花木兰 | 李白 |
自然连接
只考虑那些在两个关系模式中都出现的属性上取值相同的元组对。它不能加连接条件,使用两个表共有的字段id来“自然”地链接,同时会省略共有的字段。
- 查询两表自然连接的结果。
select g.name as gril_name,b.name as boy_name
from gril as g
natural join boy as b;
结果为空集,这句话其实等价于:
select g.name as gril_name,b.name as boy_name
from gril as g
inner join boy as b on g.name=b.name and g.age=b.age;
因为name和age两表字段相同。
外连接
左外连接
left join=inner join+主表剩余部分右边补null
left join子句的语法如下:
select column_list
from 主表
left join 从表 on join_condition1
...
[where where_conditions];
例子:
select * from boy
left join gril on gril.id=boy.id;
结果:

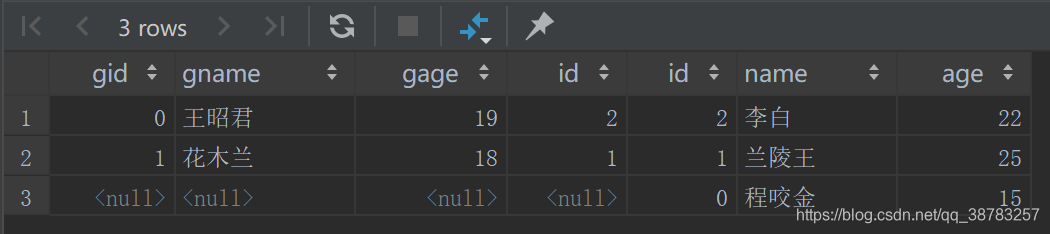
右外连接
right join=inner join+主表剩余部分左边补null
left join子句的语法如下:
select column_list
from 主表
right join 从表 on join_condition1
...
[where where_conditions];
例子:
select * from boy
left join gril on gril.id=boy.id;
结果:
全外连接
MySQL目前不支持此种方式,可以用其他方式替代解决。
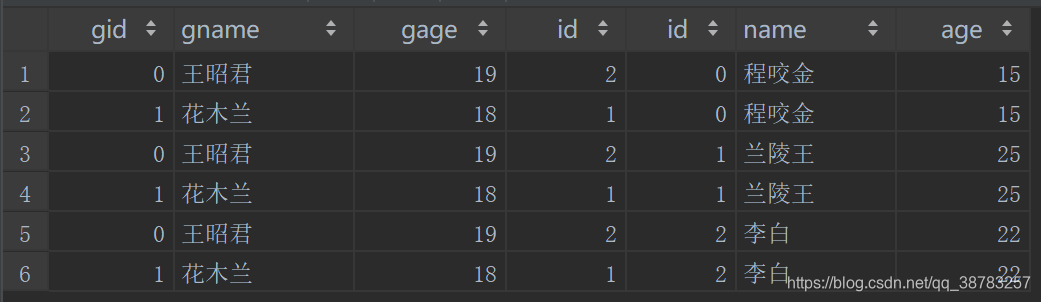
交叉连接
也就是笛卡尔积连接。
select column_list
from 主表
cross join 从表
...
[where where_conditions];
例子:
select *
from gril
cross join boy;
结果:
联合查询(union)
如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union(或称为联合)的作用是将多个结果合并在一起显示出来。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序。Union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表Union。
Union All:对两个结果集进行并集操作,包括重复行,不进行排序。
子查询
子查询的意思是一个select语句查询出来的结果集还可以作为另一个查询的条件使用。
按结果集生成的行列不同分为以下3中子查询:
- 标量子查询(一行一列)
- 列子查询(一列多行)
- 表子查询(多行多列或一行多列)
标量子查询
一般用于where中,可以跟在<, >, =, <>号后面当数字使用。
例如:
列出所有工资大于平均工资的员工。
select *
from employee
where salary>(
select avg(salary)
from employee
)
列子查询
一般用于where中,可以跟在in, any, all后面使用。
| 操作符 | 含义 |
|---|---|
| in/not in | 等于列表中任意一个 |
| some/any | 和返回的某个值比较 |
| all | 和列中所有元素比较 |
-
not in 是 “<>all”的别名,用法相同。
-
语句in 与“=any”是相同的。
表子查询
一般接在from后面,代表从子表中再次筛选。
