常用查询:
查看表的全部数据(select * from 表名):

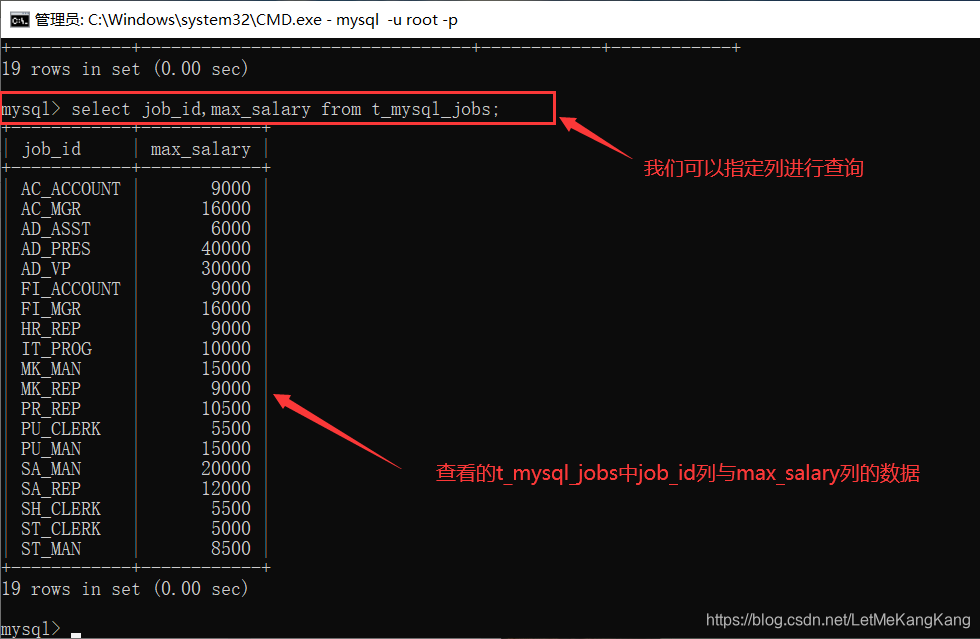
查询指定列(select 字段 from 表名):
过滤查询

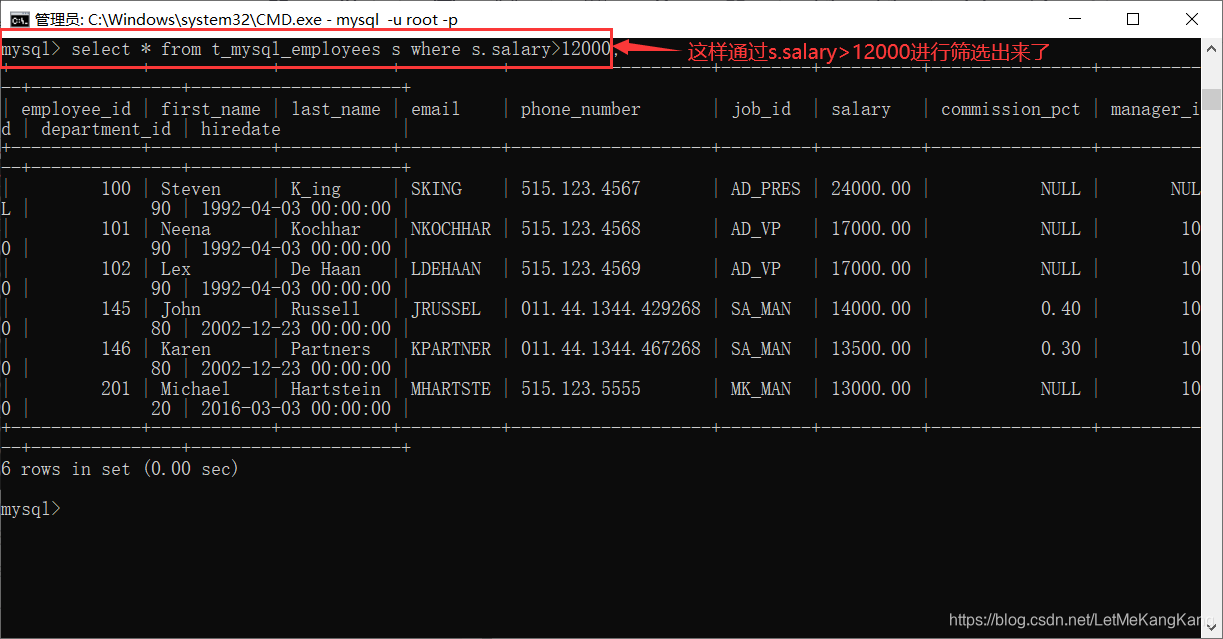
我们将salary(薪资)>12000筛选出来:
这里的s是别名!
模糊查询:mysql 中一般使用like 来进行模糊查询,但like 的效率非常的低,容易导致全表扫描,因此不推荐使用。
那有木有其他的方法代替like来进行模糊查询呢?
替代方法肯定是有的,以下是几个可替代like 进行模糊查询的 关键词
instr
locate
position
find_in_set

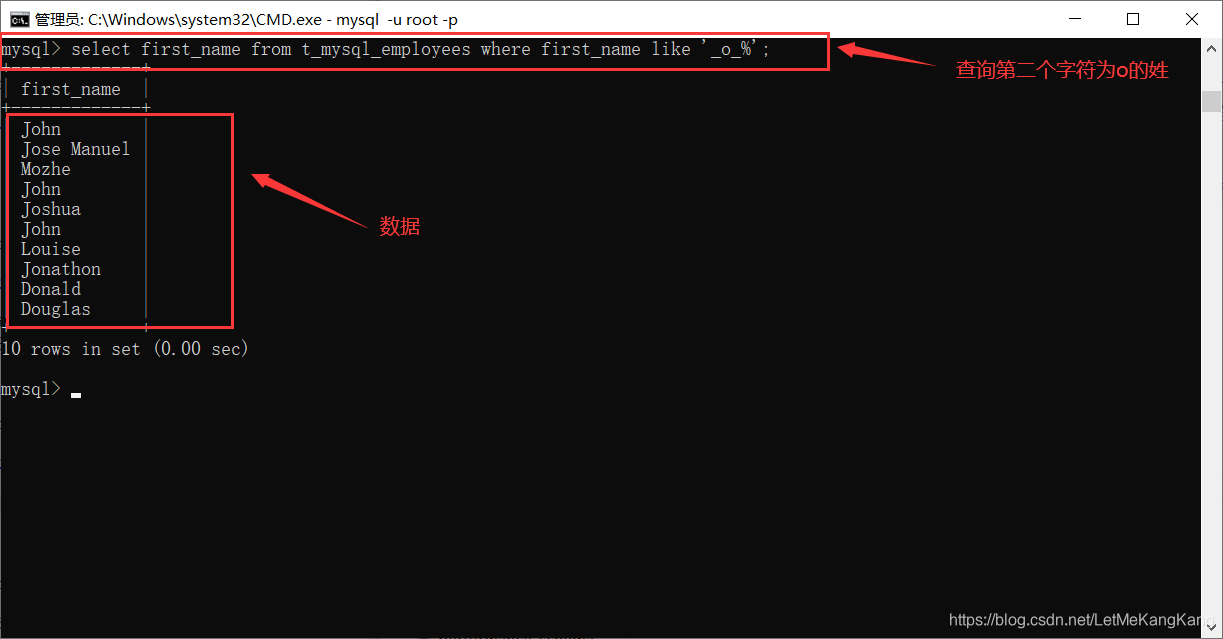
下面我们就对上面的姓名进行模糊查询(表中的first——name是表示的姓last——name代表的是名):
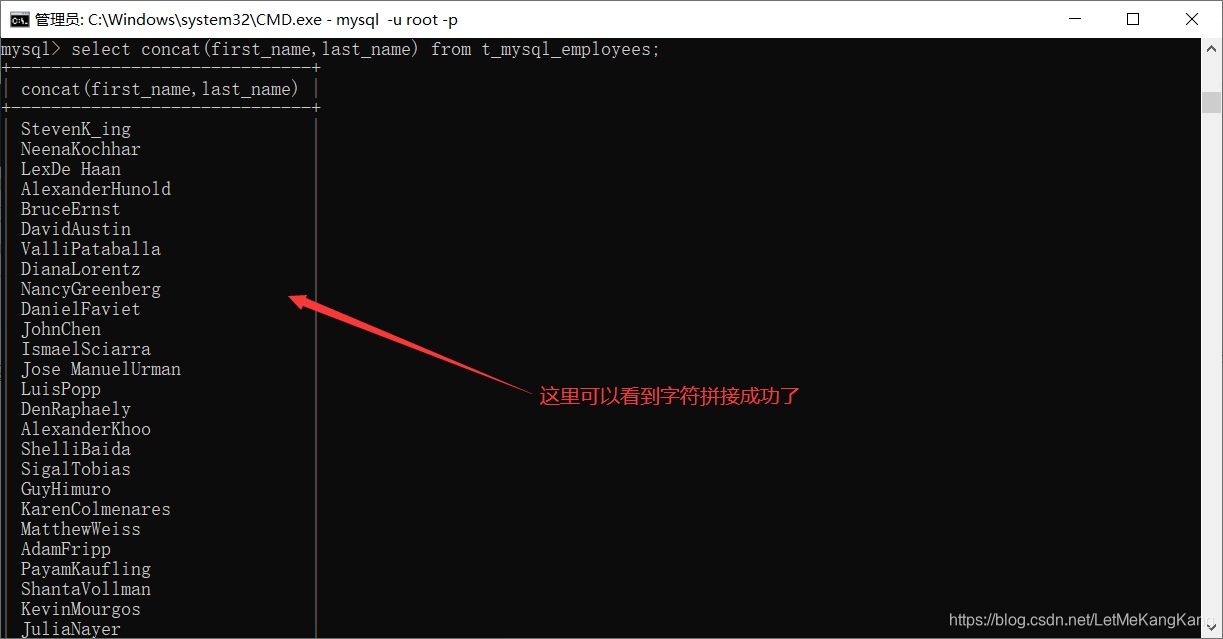
#字符串(配合字符串函数使用):我们将first_name与last_name进行拼接
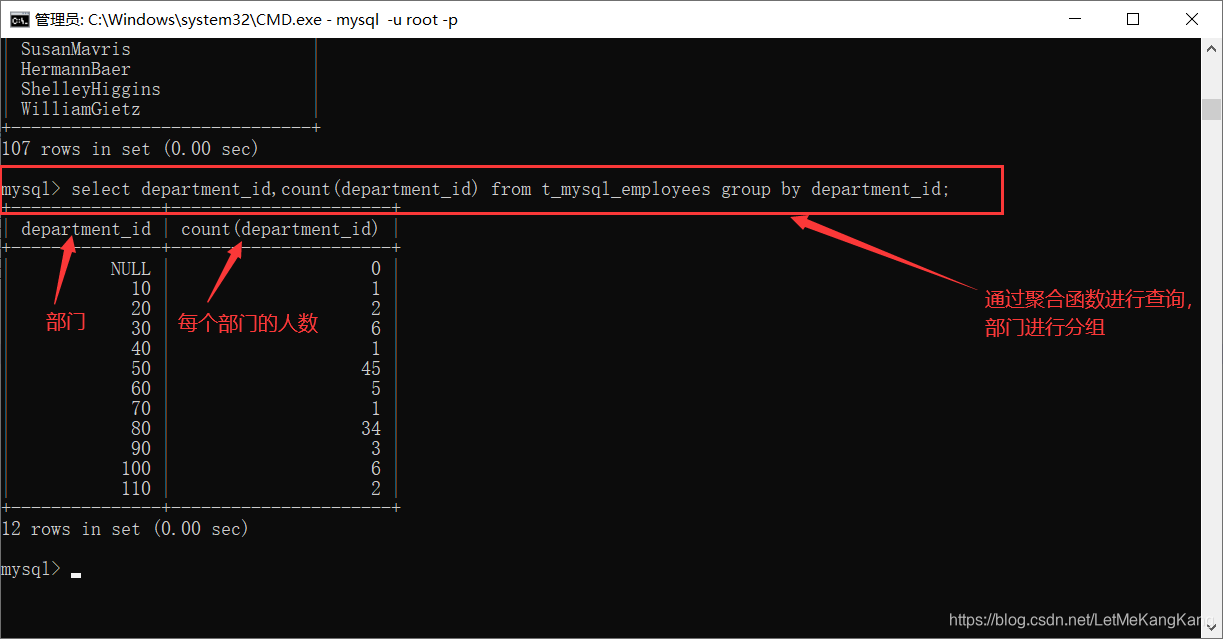
分组查询:
我们通过分组查询进行查找每个部门的员工个数:
分部门统计员工信息,筛选出工资大于12000的员工:
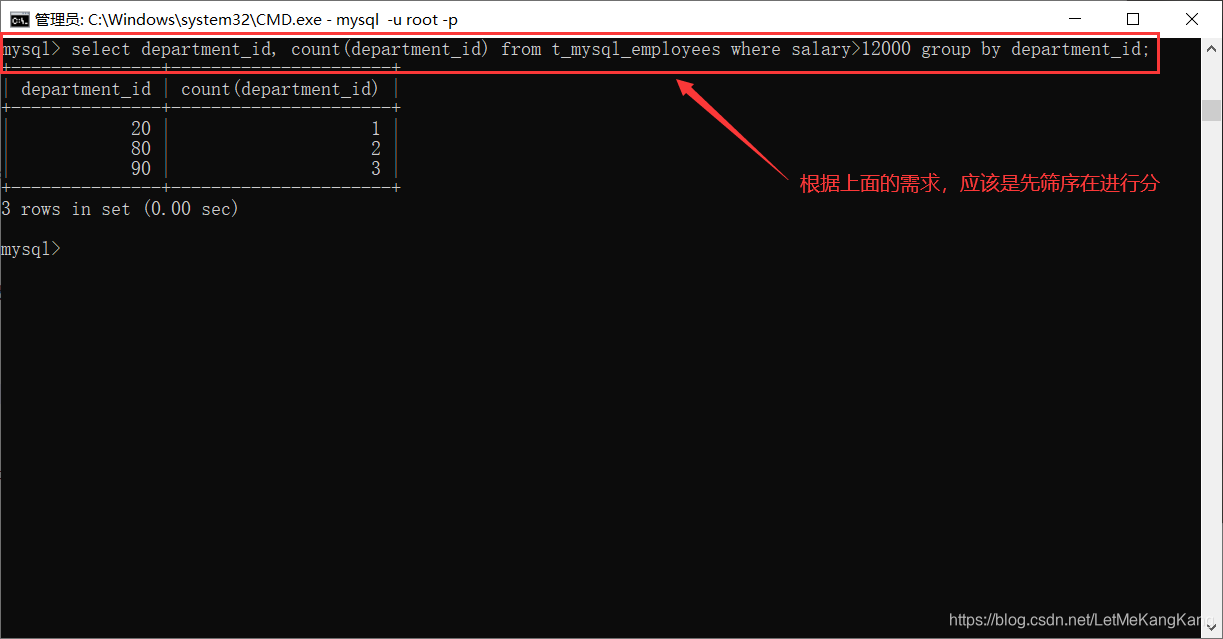
写这里我们可以看下where与having的使用场景:虽然很多情况下,where使用与having使用的结果是一样的,但是会有不一样的情况。
#统计部门编号大于90的部门人数:
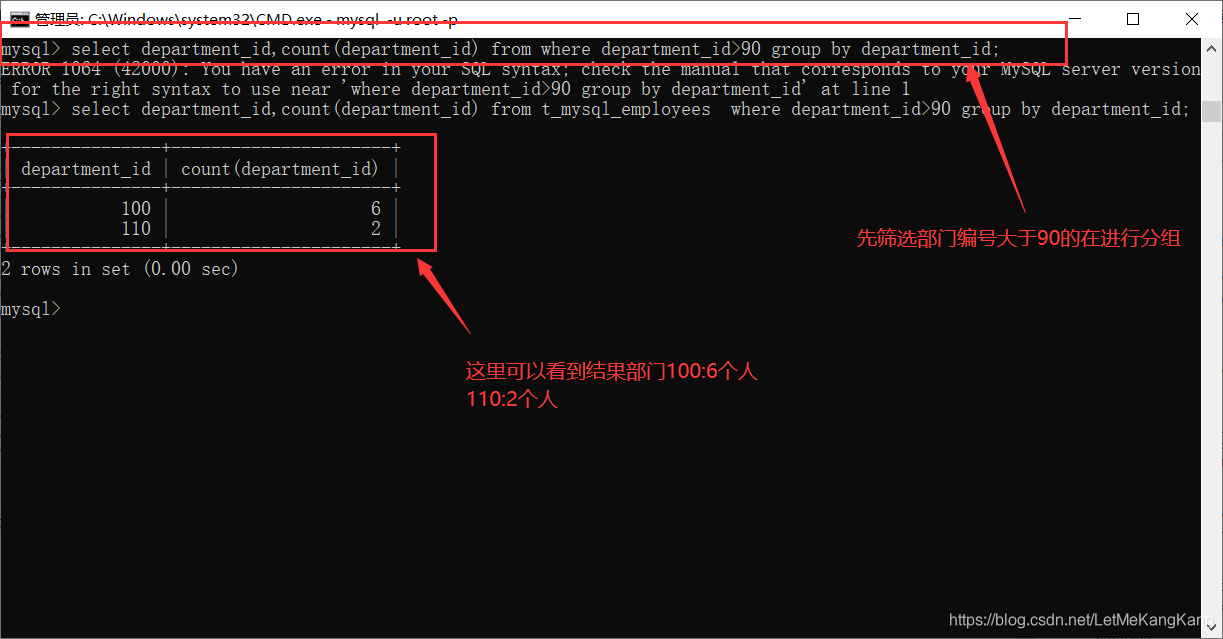
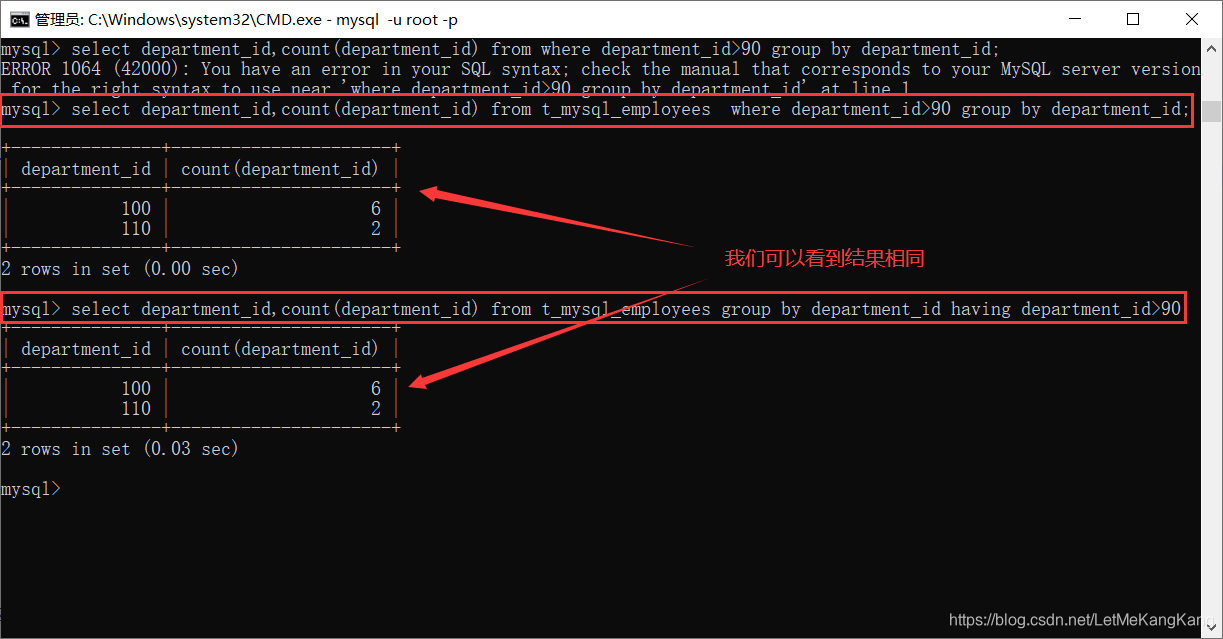
这里我们先进行分组在看(having):
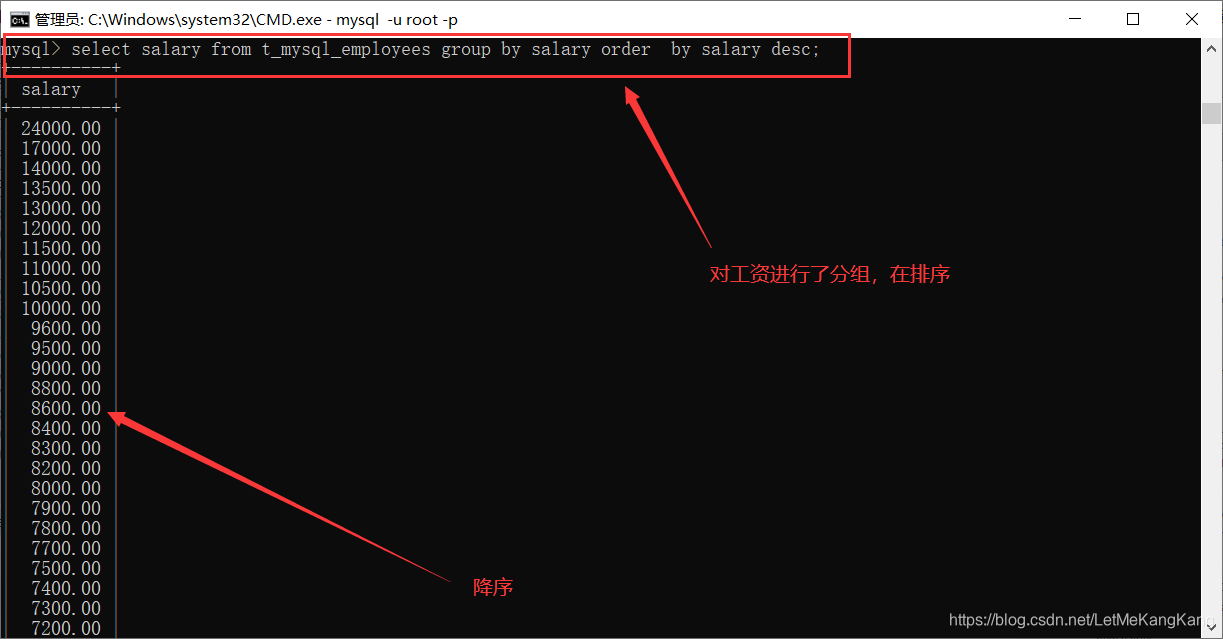
排序(order by 列名 DESC降序/ASC升序默认):
查询所有员工工资,并进行降序:
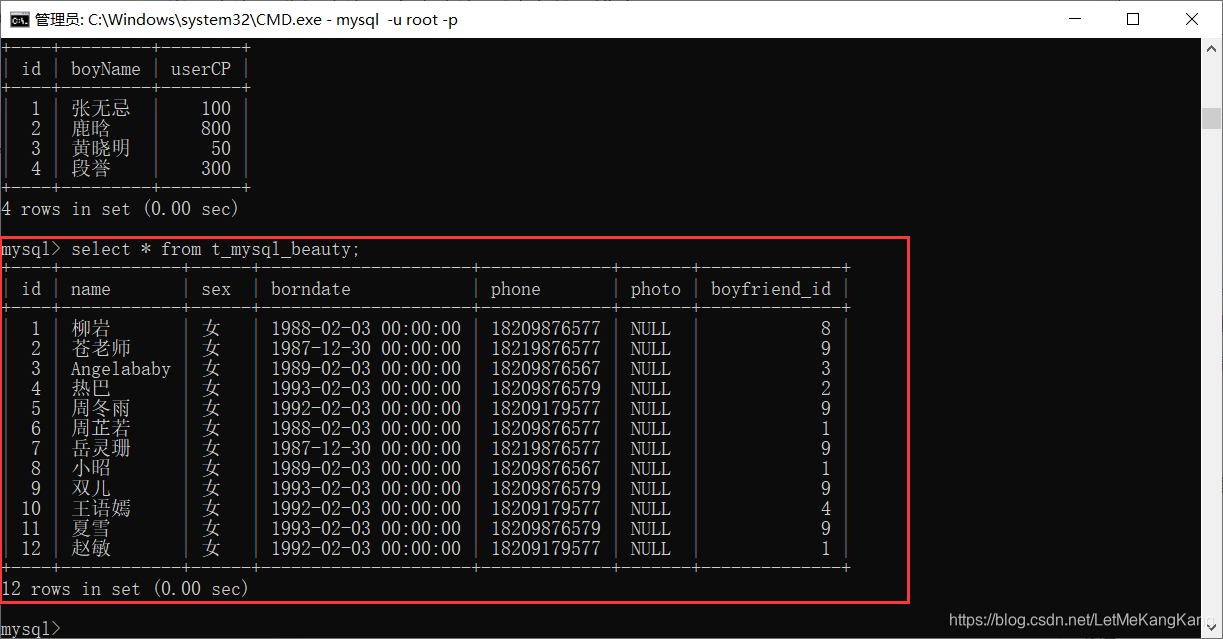
多表查询:现在这里有两张表1.t_mysql_boys,2.t_mysql_beauty;我们先看下这两张表中的数据:
1.t_mysql_boys:

2.t_mysql_beauty:
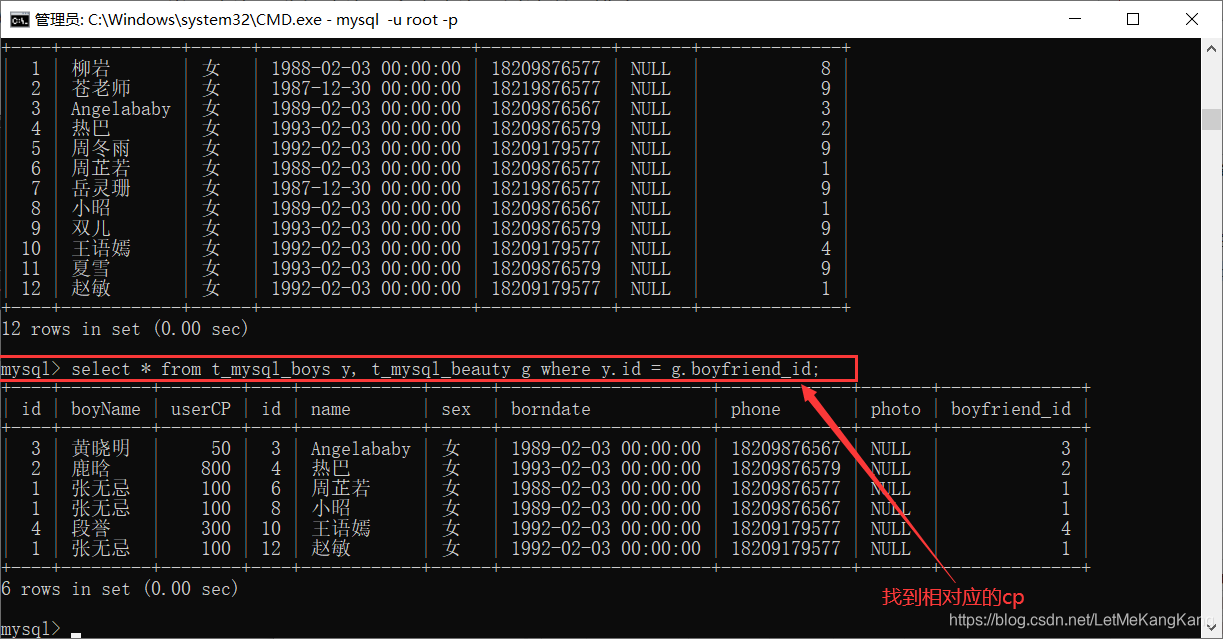
我们用过外键的方式查询相对应的cp:
我们在看几个综合性案例(下面使用的表都是以上使用的!):
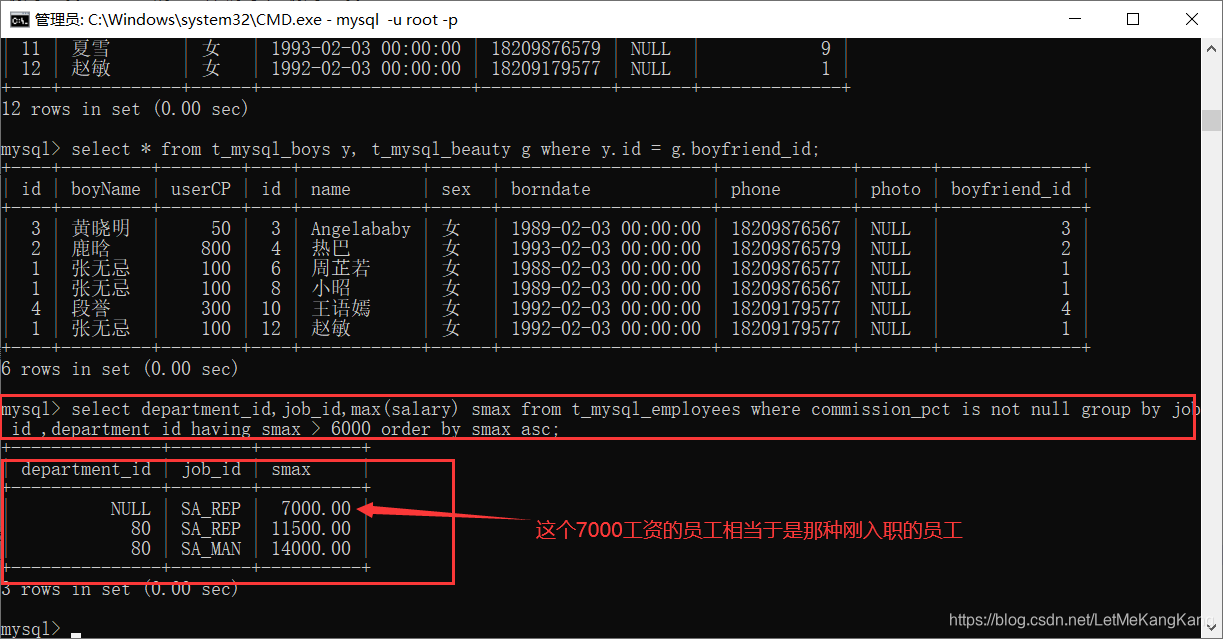
1.案例:每个工种 有奖金 的员工的 最高工资>6000 的 工种编号和最高工资,按最高工资升序;
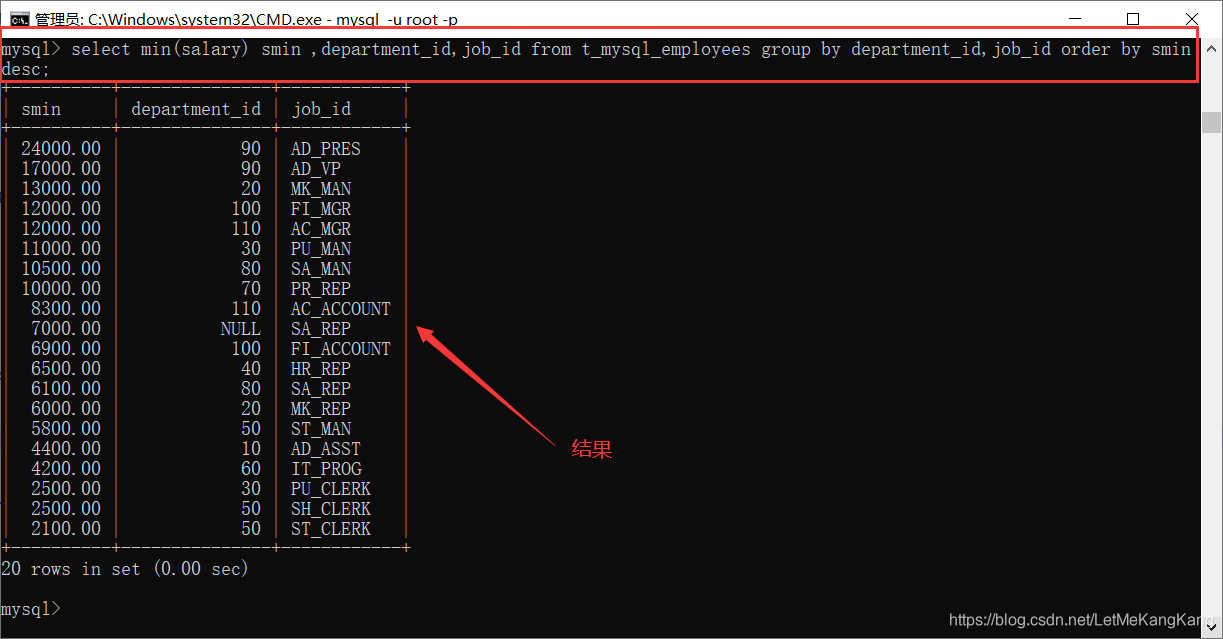
2.#案例:查询 每个工种 每个部门 的 最低工资,并按 最低工资降序: