Python的高级特性
1. 生成式
列表 (集合、字典) 生成式:一个用来快速生成列表 (集合、字典) 的特定语法形式的表达式。语法格式包括有:
# - 普通的语法格式:
temp = [exp for iter_var in iterable]
# - 带过滤功能语法格式:
temp = [exp for iter_var in iterable if _exp]
# - 循环嵌套语法格式:
temp = [exp for iter_var_A in iterable_A for iter_var_B in iterable_B]
1.1 列表生成式示例
import math
def circle_C_L():
C = lambda r: math.pi * pow(r, 2)
L = lambda r: 2 * math.pi * r
# 利用列表生成式,求以r为半径的圆的面积和周长(r的范围从1到10)。
C_L = [(C(r), L(r)) for r in range(1, 11)]
return C_L
if __name__ == '__main__':
print(circle_C_L())
1.2 集合生成式示例
import random
# 集合生成式
print({random.randint(1, 20) for num in range(10)})
1.3 字典生成式示例
def fun(user_dic: dict):
# 将字典的key值和value值调换。
return {user_value: user_key for user_key, user_value in user_dic.items()}
if __name__ == '__main__':
user_dic = dict(xiaohong=10010, xiaogang=10011, xiaowang=10012)
print(fun(user_dic))
2. 生成器
生成器(Generator):Python中,一边循环一边计算的机制称为生成器 。
- 创建生成器的方法:
1). 列表生成式的改写,即将[]改成()
2).yield关键字。 - 访问生成器中元素的方法:
1). 通过for循环, 依次计算并生成每一个元素。
2). 也可通过next()函数获得生成器的下一个返回值。(每调用一次next() 函数便获得一个返回值) - 生成器的特点:
1). 解耦。爬虫与数据存储解耦;
2). 减少内存占用。随时生产,即时消费,不用堆积在内存当中;
3). 可不终止调用。写上循环, 即可循环接收数据,对在循环之前定义的变量,可重复使用;
4). 生成器的循环在 yield 处中断,不会那么占 cpu
2.1 生成器应用案例_智能聊天机器人
# requests库是python实现的最简单易用的HTTP库,多用于网络爬虫。(is an HTTP library, written in Python, for human beings)
import requests
# json库是python中实现json的序列化与反序列化的模块。
import json
def robot_API(word):
# 青云客智能聊天机器人API接口:api.qingyunke.com,
# 由梅州市青云客网络科技有限公司提供技术支持,
# 青云客网站链接: www.qingyunke.com
url = "http://api.qingyunke.com/api.php?key=free&appid=0&msg=%s" % (word)
try:
# 访问URL, 获取网页响应的内容。
response_text = requests.get(url).text
# 将json字符串转成字典, 并获取字典的‘content’key对应的value值
# eg: {'result': 0, 'content': '有做广告的嫌疑,清静点别打广告行么'}
return json.loads(response_text).get("content", "无相应")
except Exception as e:
# 如果访问失败, 响应的内容为''
return ""
def chart_robot():
response = ""
while True:
# yield response: response就是生成器执行next方法或者send方法的返回值。
# request:保存的是利用生成器的send方法传入的参数
request = yield response
if "姓名" in request:
response = "姓名暂时保密"
elif "你好" in request:
response = "你好鸭~~"
else:
response = robot_API(request)
if __name__ == '__main__':
# 生成生成器对象 Robot
Robot = chart_robot()
# 令其停靠在yield处,等待传值
next(Robot)
while True:
request = input("Me: >> ")
if request == "再见":
print("Robot >> 再见,下次再聊~")
break
# send方法传递参数
response = Robot.send(request)
print("Robot >> ", response)
执行结果:

2.2 return关键字和yield关键字的区别
- return:在程序函数中返回某个值,返回之后函数不再执行return 后面的代码,彻底结束。
- yield:若带有yield,则表示该函数是一个生成器,函数在yield 处返回某个值后,会停留在某个位置,下次调用时,会在前面停留的位置继续执行,直到程序结束。
3. 生成器、迭代器与可迭代对象
- 生成器(Generator): Python中,
一边循环一边计算的机制称为生成器 。 - 迭代器(iterator):可以被next() 函数调用并不断返回下一个值的对象,即一个可以记住遍历位置的对象。
- 可迭代对象(iterable):能够进行for 循环的对象。
可迭代对象与迭代器的关系:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> from collections import Iterator
# list、dict、str虽然是Iterable,却不是Iterator。
>>> isinstance([], Iterator)
False
# 把list、dict、str等Iterable变成Iterator可以使用iter() 函数
>>> isinstance(iter([]), Iterator)
True
【小结】结合生成器的元素访问方法可以推得三者的关系:
4. 闭包
闭包:是指有权访问另一个函数作用域中的变量的函数。创建闭包最常见方式,就是在一个函数内部创建另一个函数。
常见形式:内部函数使用了外部函数的临时变量,且外部函数的返回值是内部函数的引用。
常用场景:装饰器。
示例:
import matplotlib.pylab as plt
# 闭包,内部函数使用了外部函数的临时变量,且外部函数的返回值是内部函数的引用。
def fun(a: int, b: int):
def fun_in(x):
return a * x + b
return fun_in
# line1 = fun_in --> 指向内存中一块代码,关于一个函数的定义
line1 = fun(2, 3)
line2 = fun(3, 4)
line3 = fun(4, 5)
x = list(range(1, 100, 2))
# 列表生成式
y1 = [line1(num) for num in x]
y2 = [line2(num) for num in x]
y3 = [line3(num) for num in x]
# plot:画折线图
plt.plot(x, y1, label='y=2x+3')
plt.plot(x, y2, label='y=3x+3')
plt.plot(x, y3, label='y=4x+3')
# 显示
plt.title('line display') # 标题
plt.legend() # 图例
plt.show()
执行结果:

5. 装饰器
装饰器:指为被装饰器对象添加额外功能的工具/函数。
为什么使用装饰器:存在一个已上线的项目,需要对项目中的某一个方法进行改进 (修改),因为对该方法的调用以完成,所以不可以对该方法的调用方式进行修改,这时可以使用装饰器。因为软件的维护应该遵循开放封闭原则,即软件一旦上线运行后,软件的维护对修改源代码是封闭的,对扩展功能是开放的。
装饰器的实现必须遵循两大原则:
- 封闭: 对已经实现的功能代码块封闭。 不修改被装饰对象的源代码
- 开放: 对扩展开发装饰器其实就是在遵循以上两个原则的前提下为被装饰对象添加新功能。
5.1 装饰器通用模板
整个装饰器的执行顺序如注解所示
def decorator(func): # step2: 此时func = my_test
"""装饰器的通用模板"""
# @wraps保留被装饰函数的函数名和帮助文档, 否则是wrapper的信息.
@wraps(func)
def wrapper(*args, **kwargs): # step5:args=('haha', ), kwargs={}
result = func(*args, **kwargs) # step6: 基于step2,执行func()函数实质上是执行my_test()函数
return result # step8:如果被装饰函数存在返回值,将结果返回
return wrapper # step3: 将函数名 wrapper返回,因为step1中 my_test = decorator(my_test),所以 my_test == wrapper
@decorator # step1: @decorator <==> my_test = decorator(my_test)
def my_test(arg): # step7:打印 "我是被装饰函数,这是我的参数: haha"
print("我是被装饰函数,这是我的参数: ", arg)
if __name__ == '__main__':
my_test("haha") # step4:基于step1和step3,此时对my_test()的调用实质上是对wrapper()的调用
5.2 装饰器的典型应用场景
装饰器经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等应用场景。
5.3 有参装饰器
有参装饰器的实现:因为无参装饰器实质上只套了两层函数,为实现装饰器的传参在原有装饰器外层再套一层函数,即有参装饰器 --> 套三层的装饰器
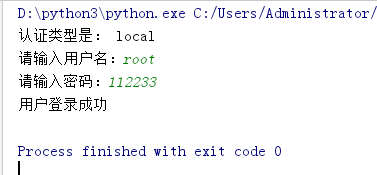
代码示例:
from functools import wraps
def auth(type):
"""有参装饰器"""
print("认证类型是:", type)
def is_login(func):
"""判断用户是否登录的装饰器"""
# @wraps(func),用来保留被装饰func函数原有的函数名和帮助文档
@wraps(func)
def wrapper(*args, **kwargs):
"""闭包函数"""
if type == "local":
user = input("请输入用户名:")
passwd = input("请输入密码:")
if user == "root" and passwd == "112233":
result = func(*args, **kwargs)
return result
else:
print("用户/密码输入错误")
else:
print("暂不支持远程登录")
return wrapper
return is_login
@auth("local")
def home():
print("用户登录成功")
if __name__ == '__main__':
home()
执行结果:
6. 内置高阶函数
内置高阶函数:把函数名作为参数传入,这样的函数称为高阶函数,函数式编程就是指这种高度抽象的编程范式。
6.1 map 函数
map():会根据提供的函数对指定序列做映射。当序列多于一个时,map可以并行(注意是并行)地对每个序列执行映射。
代码示例:
# 1). map的传递函数名可以是内置函数
map_object = map(int, ['1', '2', '3'])
for item in map_object:
print(item, type(item))
# 2). map的传递函数名可以是匿名函数
map_object = map(lambda x: x ** 2, [1, 2, 3, 4])
print(list(map_object)) # [1, 4, 9, 16]
def data_process(x):
return x + 4
# 3). map的传递函数名可以是非匿名函数
map_object = map(data_process, [1, 2, 3, 4])
print(list(map_object)) # [1, 4, 9, 16]
# 4). map的传递的可迭代对象可以是多个
"""
x, y = 1, 1 2
x, y = 2, 2 6
x, y = 3, 3 12
"""
map_object = map(lambda x, y: x ** 2 + y, [1, 2, 3], [1, 2, 3])
print(list(map_object))
6.2 reduce 函数
reduce() :函数会对参数序列中元素进行累积。
代码示例:
# reduce() 函数会对参数序列中元素进行累积。
# py2中, reduce是内置高阶函数;
# py3中, reduce函数需要导入;
from functools import reduce
# 需求: 通过reduce函数实现累加
nums_add = reduce(lambda x, y: x + y, list(range(1, 101)))
print(nums_add)
# 需求: 通过reduce函数实现阶乘
N = 5
result = reduce(lambda x, y: x * y, list(range(1, N + 1)))
print(result)
6.3 filter 函数
filter(): 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
代码示例:
# 拿出1~100之间所有的素数
def is_prime1(x):
"""素数判断器,该判断器时间复杂度较高,需改进..."""
if x == 1:
return False
for div_num in range(2, x):
if x % div_num == 0:
return False
else:
return True
prime_filter_obj = filter(is_prime, list(range(1, 101)))
print(list(prime_filter_obj))
6.4 sorted 函数
sorted():函数对所有可迭代的对象进行排序操作。返回重新排序的列表。
使用规则:
sorted(iterable, key=None, reverse=False)
# key: 主要是用来进行比较的元素,只有一个参数,
# reverse: 排序规则,True 降序 ,False 升序(默认)。
li.sort() 和sorted() 的区别:
排序(作用) 对象不同。li.sort() 为列表的内置方法,为列表对象进行排序;sorted() 为可迭代对象进行排序,包括:字符串、列表、字典等返回值不同。li.sort() 无返回值,排序结果直接作用在输入;sorted() 方法会返回一个新的列表对象。
