split()
切割字符串,返回列表
#str为分隔符,默认为所有的空字符,包括空格、换行'\n'、制表符'\t'等;num为分割次数
str.split(str = ' ', num = string.count(str))strip()、lstrip()、rstrip()
删除特定字符,返回字符, 默认删除空白符,包括'\n','\r','\t',' '
#删除字符串s中开头、结尾的'ab'字符
s.strip('ab')
#删除字符串s中开头的'ab'字符
s.lstrip('ab')
#删除字符串s中结尾的'ab'字符
s.rstrip('ab') 列表、元组
当定义只有一个元素的元组(),需要在元素后加逗号,而定义列表不需要

修改列表的元素,列表地址不变
tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的。
外部参数
sys.argv[]从程序外部获取参数的桥梁,其实就是一个列表, sys.argv[0]表示代码本身文件路径,sys.argv[1]或a=sys.argv[2:]等为用户输入的参数。
「argv」是「argument variable」参数变量的简写形式,一般在命令行调用的时候由系统传递给程序。
SMTP
smtp发送的过程:初始化smtp对象、connect、helo、ehlo(helo和ehlo是smtp协议中可选内容,在登录前提供校验,qq要求发送该消息 )、login、sendmail、quit。基本原理就是建立连接后校验身份,通过后登陆并发送邮件,发送完quit
Content-Type:用于定义用户的浏览器或相关设备如何显示将要加载的数据,或者如何处理将要加载的数据。
MIME:MIME类型:就是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。
text/html:将文件的content-type设置为text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。
text/plain:将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理。
switch语句
#!/usr/bin/python
#coding:utf8
from __future__ import division #申明之后3/2 = 1.5
def jia(x, y):
return x + y
def jian(x, y):
return x - y
def cheng(x, y):
return x * y
def chu(x, y):
return(x / y)
def operator(x, o, y):
if o == '+':
print jia(x,y)
elif o == '-':
print jian(x,y)
elif o == '*':
print cheng(x,y)
elif o == '/':
print chu(x,y)
else:
pass
operator (2,'/',4)
#用字典代替if判断
operator = {'+':jia, "-":jian, '*':cheng, '/':chu}
print operator['/'](3,2)
print chu(3,2)
operator = {'+':jia, "-":jian, '*':cheng, '/':chu}
def f(x,o,y):
print operator.get(o)(x,y)
f(3,'/',2)
模块
在一文件夹中添加__init__.py文件,则该文件夹变为函数包,包由多个模块组成
重命名:
import cal as c #重命名使用__future__把下一个新版本的特性导入到当前版本,为升级代码做测试。比如测试python3中的除法:

时间
from datetime import *
date.today() #2018-08-21
import time
time.strftime('%Y%m%d-%H%M%S') #20180821-171601
迭代器
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。

可以直接作用于for循环的对象统称为可迭代对象(Iterable)。
可以被next()函数调用并不断返回下一个值的对象称为迭代器(Iterator)。
items()
将字典中的每个项分别作为元组,添加到一个列表中,形成了一个新的列表容器。空间换时间
a = {'a':1,'b':3}
a.items() #返回[('a',1),('b',3)]iteritems()
返回一个迭代器,一次返回一个数据项,直到没有为止。时间换空间
b = a.iteritems()
list(b)
返回 [('a',1),('b',3)]
for x in b:
print x
返回('a', 1)
('b', 3)
for k,v in b:
print k,v
返回a 1
b 2采用b=(x for x in a.iteritems())和c=(x for x in a.items())方式构造出来的b和c都是一个generator object,它们的内容一样(基于a的内容进行构造),所以用b.next()和c.next()输出时结果显示是一样的。
如果用b=a.iteritems()和c=a.items()方式构造出来b和c之后,用print b和print c输出内容时就会发现c是一个list,可以直接输出,而b是一个dictionary-itemiterator,可以用 for x in b: print x输出b中的内容。
生成器(generator)
为节省空间,采用一边循环一边计算的机制,构建方法:
- 只要把一个列表生成式的[]改成(),就创建了一个generator,通过for循环来迭代它。

- 如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:

![]()
参数引用
print "serving http on port {0}...".format(str(port))python标准异常
http://naotu.baidu.com/file/585ce6893e5e9290b157bf48caf41dcc?token=66ae1670e2bbcd8d
进程和线程
多任务的实现有3种方式:
- 多进程模式;
- 多线程模式;
- 多进程+多线程模式。
在Unix/Linux下,可以使用fork()调用实现多进程。
要实现跨平台的多进程,可以使用multiprocessing模块。
进程间通信是通过Queue、Pipes等实现的。
多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
事件驱动模型:利用操作系统提供的异步IO支持,可实现单进程单线程来执行多任务。
协程:Python中单进程的异步编程模型。
常用内建模块
- Base64
是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
- 哈希算法
MD5,SHA1,更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
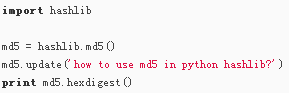
md5.update 会将每次字符串拼接,每次使用update之前都要重新定义:md5=hashlib.md5()