概述
本篇博文将以比赛–知识图谱大赛为例,详解命名实体识别的代码部分,大赛旨在通过糖尿病相关的教科书、研究论文来做糖尿病文献挖掘并构建糖尿病知识图谱,分为初赛和复赛,初赛旨在实体识别,复赛重在关系抽取,本文主要讲解实体识别部分。实体类别共十五类,定义如下所示:
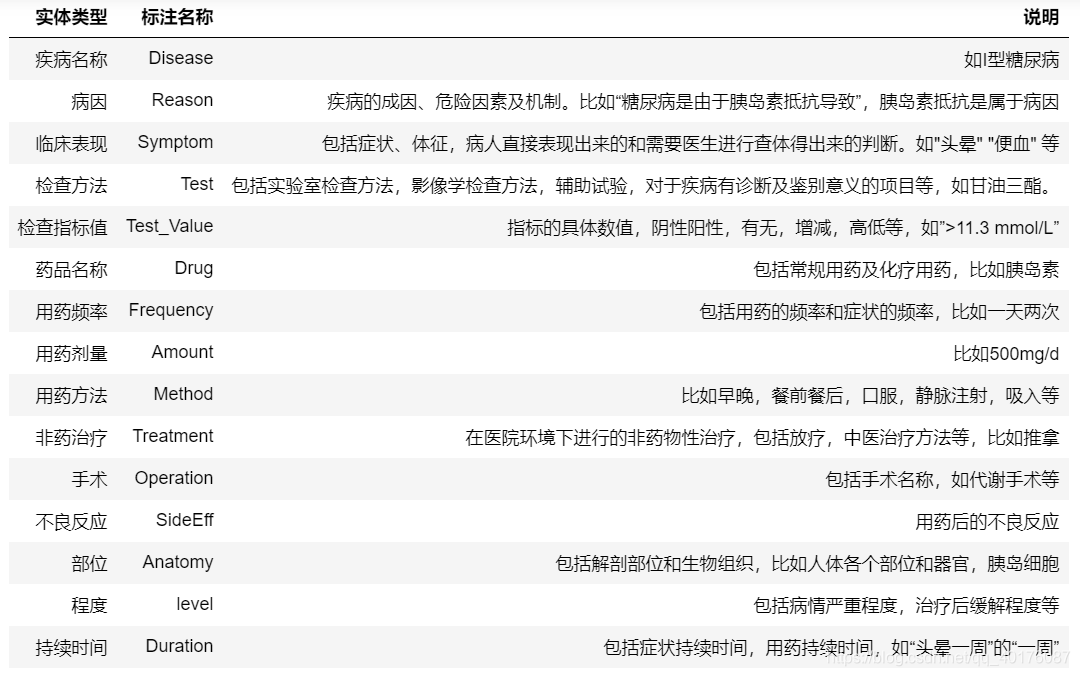
数据使用 brat 进行标注,每个 .txt 文件对应一个 .ann 标注文件。
数据样例
0.txt
中国成人2型糖尿病HBA1C c控制目标的专家共识
目前,2型糖尿病及其并发症已经成为危害公众
健康的主要疾病之一,控制血糖是延缓糖尿病进展及
其并发症发生的重要措施之一。虽然HBA1C 。是评价血
糖控制水平的公认指标,但应该控制的理想水平即目
标值究竟是多少还存在争议。糖尿病控制与并发症试
验(DCCT,1993)、熊本(Kumamoto,1995)、英国前瞻性
糖尿病研究(UKPDS,1998)等高质量临床研究已经证
实,对新诊断的糖尿病患者或病情较轻的患者进行严
格的血糖控制会延缓糖尿病微血管病变的发生、发展,
0.ann
T1 Disease 1845 1850 1型糖尿病
T2 Disease 1983 1988 1型糖尿病
T4 Disease 30 35 2型糖尿病
T5 Disease 1822 1827 2型糖尿病
T6 Disease 2055 2060 2型糖尿病
T7 Disease 2324 2329 2型糖尿病
T8 Disease 4325 4330 2型糖尿病
T9 Disease 5223 5228 2型糖尿病
T10 Disease 5794 5799 2型糖尿病
T11 Disease 5842 5847 2型糖尿病
…
.ann 文件有3列,以 \t 分隔,第一列为实体编号,第二列为实体类别,第三列为实体位置信息。实体位置信息共3列, 以空格分隔,分别代表实体的开始位置,结束位置,实体文本。
解决方案
处于以下几个原因:
- 我们是对一篇文章去做实体标注,文章的字数可能很长(几千到上万字),不可能直接输入到一个 RNN 中;
- 样本中文章可能由于格式转换的一些原因,没有一个很好的句子边界,甚至一个词汇当中存在换行符 \n 或者句号 。 的情况,因此用换行 符或者句号去切割句子不一定合适。如果按照固定窗口大小的滑动窗口去切句子,刚好把一个实体切分成2个部分怎么办?
- 中文文本,面临是否要分词的选择;
最终我采用一种比较特殊的滑动窗口去切句子:
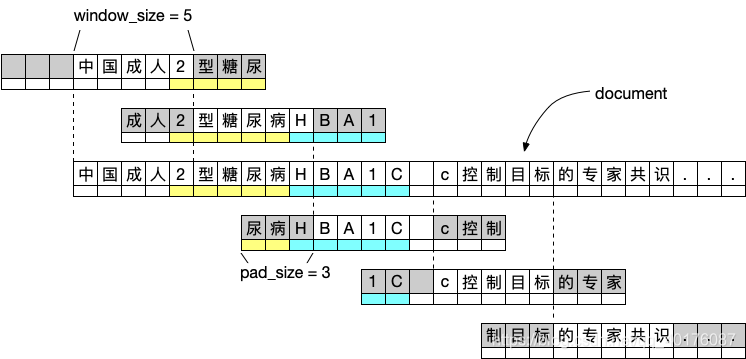
即使用一个窗口大小与步长相等的滑动窗口去切句子,切完的句子再分别想左右伸展一定数量的文字。这样做的好处是每个句子出来的长度是相等的,并且每个句子都得到了一些上下文的内容。譬如上面的例子是用一个窗口大小与步长都为5的滑动窗口去切割,之后分别再向左右展开3个字,变成长度 11 的句子。实际 training 的时候,我会要求模型输出对这11个字的类别做预测,但在做 inference 的时候,会将左右展开的部分去除,只保留中间5个字的输出。这样一来可以较好的解决切分点刚好卡在一个 entity 当中的情况,并且做预测的时候得到了周围2个句子的部分上下文信息。
考虑到如果使用分词方案,需要不少前处理工作,因为存在不少 entity 当中包含 \n 的例子,并且测试样例当中新词可能较多的情况,因此我没有对文章进行分词,而是直接使用所有数据训练一个字符级别的字向量的做法。

代码部分
代码主要分为三个部分,实体的定义和处理、句子的切分和处理、模型的搭建,除此之外还有预测评估的部分,代码中都做了注解。
句子的切分和处理
class Sentence(object):
"""
定义被切分的句子的类:
text:句子的文本
doc_id:句子所述文档id
offset:句子相对文档的偏移距离
ents:句子包含的实体列表
"""
def __init__(self, doc_id, offset, text, ents):
self.text = text
self.doc_id = doc_id
self.offset = offset
self.ents = ents
def __repr__(self):
"""
内部魔法函数:以text显示类
:return:
"""
return self.text
def __gt__(self, other):
#内部魔法函数:按类的offset偏移距离对类进行排序
return self.offset > other.offset
def __getitem__(self, key):
"""
内部魔法函数:预测结果评估时,去除句子两端延申的部分
:param key:
:return:
"""
if isinstance(key, int):
return self.text[key]
if isinstance(key, slice):
text = self.text[key]
start = key.start or 0
stop = key.stop or len(self.text)
if start < 0:
start += len(self.text)
if stop < 0:
stop += len(self.text)
#改变实体相对于句子的偏移距离
ents = self.ents.find_entities(start, stop).offset(-start)
#改变句子相对于文档的偏移距离
offset = self.offset + start
return Sentence(self.doc_id, offset, text, ents)
def _repr_html_(self):
"""
内部函数:网页显示不同的实体以不同的颜色区分
:return:
"""
ents = []
for ent in self.ents:
ents.append({'start': ent.start_pos,
'end': ent.end_pos,
'label': ent.category})
ex = {'text': self.text, 'ents': ents, 'title': None, 'settings': {}}
return displacy.render(ex,
style='ent',
options={'colors': COLOR_MAP},
manual=True,
minify=True)
class SentenceExtractor(object):
#句子切分器,窗口为windows,两端分别延申pad_size
def __init__(self, window_size=50, pad_size=10):
self.window_size = window_size
self.pad_size = pad_size
def extract_doc(self, doc):
#句子切分函数,切分的时候注意每个切分的句子相对于文档的偏移距离,预测的时候还需要还原
num_sents = math.ceil(len(doc.text) / self.window_size)
doc = doc.pad(pad_left=self.pad_size, pad_right=num_sents * self.window_size - len(doc.text) + self.pad_size)
sents = []
for cur_idx in range(self.pad_size, len(doc.text) - self.pad_size, self.window_size):
sent_text = doc.text[cur_idx - self.pad_size: cur_idx + self.window_size + self.pad_size]
ents = []
for ent in doc.ents.find_entities(start_pos=cur_idx - self.pad_size,
end_pos=cur_idx + self.window_size + self.pad_size):
ents.append(ent.offset(-cur_idx + self.pad_size))
sent = Sentence(doc.doc_id,
offset=cur_idx - 2 * self.pad_size,
text=sent_text,
ents=Entities(ents))
sents.append(sent)
return sents
def __call__(self, docs):
#内部函数:将类当成函数形式的调用
sents = []
for doc in docs:
sents += self.extract_doc(doc)
return sents
实体定义和处理
class Entity(object):
#自定义实体类
def __init__(self, ent_id, category, start_pos, end_pos, text):
self.ent_id = ent_id
self.category = category
self.start_pos = start_pos
self.end_pos = end_pos
self.text = text
def __gt__(self, other):
#同上
return self.start_pos > other.start_pos
def offset(self, offset_val):
#实体位置偏移(相当于句子)
return Entity(self.ent_id,
self.category,
self.start_pos + offset_val,
self.end_pos + offset_val,
self.text)
def __repr__(self):
#内部函数:实体显示内容
return '({}, {}, ({}, {}), {})'.format(self.ent_id,
self.category,
self.start_pos,
self.end_pos,
self.text)
class Entities(object):
#自定义实体列表
def __init__(self, ents):
#按照实体起始位置排序
self.ents = sorted(ents)
self.ent_dict = dict(zip([ent.ent_id for ent in ents], ents))
def __getitem__(self, key):
if isinstance(key, int) or isinstance(key, slice):
return self.ents[key]
else:
return self.ent_dict.get(key, None)
def offset(self, offset_val):
#实体起始位置偏移
ents = [ent.offset(offset_val) for ent in self.ents]
return Entities(ents)
def vectorize(self, vec_len, cate2idx):
#实体的向量化,注意,这里实体的标注方式并没有采用BIO的方式,而是
#直接以实体id填充,非实体以0表示,简单粗暴,如果用BIO的方式标注,可能效果会更好
res_vec = np.zeros(vec_len, dtype=int)
for ent in self.ents:
res_vec[ent.start_pos: ent.end_pos] = cate2idx[ent.category]
return res_vec
def find_entities(self, start_pos, end_pos):
#找出句子中指定位置范围内的实体
res = []
for ent in self.ents:
if ent.start_pos > end_pos:
break
sp, ep = (max(start_pos, ent.start_pos), min(end_pos, ent.end_pos))
if ep > sp:
new_ent = Entity(ent.ent_id, ent.category, sp, ep, ent.text[:(ep - sp)])
res.append(new_ent)
return Entities(res)
def merge(self):
#如果同一种类型的实体发生交叉,就合并实体
merged_ents = []
for ent in self.ents:
if len(merged_ents) == 0:
merged_ents.append(ent)
elif (merged_ents[-1].end_pos == ent.start_pos and
merged_ents[-1].category == ent.category):
merged_ent = Entity(ent_id=merged_ents[-1].ent_id,
category=ent.category,
start_pos=merged_ents[-1].start_pos,
end_pos=ent.end_pos,
text=merged_ents[-1].text + ent.text)
merged_ents[-1] = merged_ent
else:
merged_ents.append(ent)
return Entities(merged_ents)
模型搭建
def build_lstm_crf_model(num_cates, seq_len, vocab_size, model_opts=dict()):
opts = {
'emb_size': 256,
'emb_trainable': True,
'emb_matrix': None,
'lstm_units': 256,
'optimizer':keras.optimizers.Adam()
}
opts.update(model_opts)
input_seq = Input(shape=(seq_len,), dtype='int32')
if opts.get('emb_matrix') is not None:
#word2vec预训练词向量,其实可以试试Elmo,可能效果更好
embedding = Embedding(vocab_size, opts['emb_size'],
weights=[opts['emb_matrix']],
trainable=opts['emb_trainable'])
else:
embedding = Embedding(vocab_size, opts['emb_size'])
x = embedding(input_seq)
lstm = LSTM(opts['lstm_units'], return_sequences=True)
x = Bidirectional(lstm)(x)
crf = CRF(num_cates, sparse_target=True)
output = crf(x)
model = Model(input_seq, output)
model.compile(opts['optimizer'], loss=crf.loss_function, metrics=[crf.accuracy])
return model
运行状态
.............
1344/47577 [..............................] - ETA: 10:32 - loss: 1.0440 - crf_viterbi_accuracy: 0.7363
1408/47577 [..............................] - ETA: 10:40 - loss: 1.0243 - crf_viterbi_accuracy: 0.7402
1472/47577 [..............................] - ETA: 10:49 - loss: 1.0085 - crf_viterbi_accuracy: 0.7427
1536/47577 [..............................] - ETA: 10:56 - loss: 0.9877 - crf_viterbi_accuracy: 0.7468
1600/47577 [>.............................] - ETA: 11:00 - loss: 0.9712 - crf_viterbi_accuracy: 0.7499
1664/47577 [>.............................] - ETA: 11:07 - loss: 0.9637 - crf_viterbi_accuracy: 0.7501
1728/47577 [>.............................] - ETA: 11:13 - loss: 0.9472 - crf_viterbi_accuracy: 0.7539
1792/47577 [>.............................] - ETA: 11:20 - loss: 0.9389 - crf_viterbi_accuracy: 0.7547
1856/47577 [>.............................] - ETA: 11:26 - loss: 0.9252 - crf_viterbi_accuracy: 0.7576
1920/47577 [>.............................] - ETA: 11:29 - loss: 0.9160 - crf_viterbi_accuracy: 0.7589
1984/47577 [>.............................] - ETA: 11:35 - loss: 0.9049 - crf_viterbi_accuracy: 0.7610
2048/47577 [>.............................] - ETA: 11:40 - loss: 0.8926 - crf_viterbi_accuracy: 0.7635
2112/47577 [>.............................] - ETA: 11:44 - loss: 0.8826 - crf_viterbi_accuracy: 0.7652
2176/47577 [>.............................] - ETA: 11:49 - loss: 0.8742 - crf_viterbi_accuracy: 0.7667
2240/47577 [>.............................] - ETA: 11:55 - loss: 0.8623 - crf_viterbi_accuracy: 0.7693
2304/47577 [>.............................] - ETA: 11:57 - loss: 0.8563 - crf_viterbi_accuracy: 0.7706
2368/47577 [>.............................] - ETA: 11:59 - loss: 0.8469 - crf_viterbi_accuracy: 0.7726
2432/47577 [>.............................] - ETA: 12:00 - loss: 0.8401 - crf_viterbi_accuracy: 0.7740
2496/47577 [>.............................] - ETA: 12:02 - loss: 0.8342 - crf_viterbi_accuracy: 0.7747
2560/47577 [>.............................] - ETA: 12:04 - loss: 0.8241 - crf_viterbi_accuracy: 0.7769
.......................以上是部分代码,若需要完整代码和数据集,欢迎留言,或者访问链接:链接:https://pan.baidu.com/s/1hXTiBj7JZRD8eS-qHS7bqA
提取码:2egn,即可获得。
