端到端(end-to-end)是什么
端到端指的是输入是原始数据,输出是最后的结果,原来输入端不是直接的原始数据,而是在原始数据中提取的特征
经典机器学习方式是以人类的先验知识将raw数据预处理成feature,然后对feature进行分类。分类结果十分取决于feature的好坏。所以过去的机器学习专家将大部分时间花费在设计feature上。那时的机器学习有个更合适的名字叫feature engineering 。
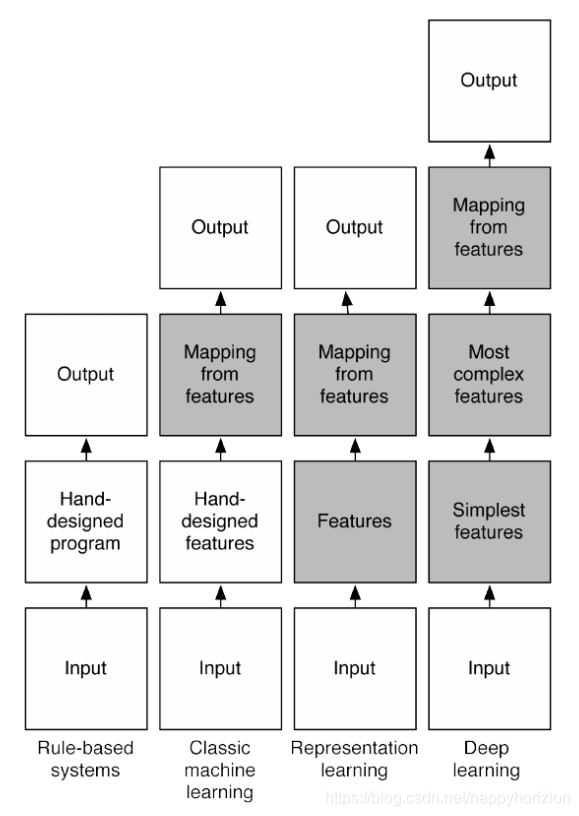
随着深度学习神经网络的发展,让网络自己学习如何抓取feature效果更佳。由于多层神经网络被证明能够耦合任意非线性函数,通过一些配置能让网络去做以前需要人工参与的特征设计这些工作,然后配置合适的功能如classifier,regression,而现在神经网络可以通过配置layers的参数达到这些功能,整个输入到最终输出无需太多人工设置,从raw data 到最终输出指标。于是兴起了representation learning。这种方式对数据的拟合更加灵活。
端到端(end to end)的好处
通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
不同应用场景下的端到端含义不同
end-end在不同应用场景下有不同的具体诠释。
计算机视觉CV中的端到端
对于computer vision视觉领域而言,end-end一词多用于基于视觉的机器控制方面,具体表现是,神经网络的输入为原始图片,神经网络的输出为(可以直接控制机器的)控制指令,如:
-
Nvidia的基于CNNs的end-end自动驾驶,输入图片,直接输出steering angle。从视频来看效果拔群,但其实这个系统目前只能做简单的follow lane,与真正的自动驾驶差距较大。亮点是证实了end-end在自动驾驶领域的可行性,并且对于数据集进行了augmentation。链接:https://devblogs.nvidia.com/parallelforall/deep-learning-self-driving-cars/
-
Google的paper: Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection,也可以算是end-end学习:输入图片,输出控制机械手移动的指令来抓取物品。这篇论文很赞,推荐:https://arxiv.org/pdf/1603.02199v4.pdf
-
DeepMind神作Human-level control through deep reinforcement learning,其实也可以归为end-end,深度增强学习开山之作,值得学习:http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html
-
Princeton大学有个Deep Driving项目,介于end-end和传统的model based的自动驾驶之间,输入为图片,输出一些有用的affordance(实在不知道这词怎么翻译合适…)例如车身姿态、与前车距离、距路边距离等,然后利用这些数据通过公式计算所需的具体驾驶指令如加速、刹车、转向等。链接:http://deepdriving.cs.princeton.edu/
语音识别中的端到端
传统的语音识别系统,由声学模型、发音词典、语言模型。其中声学模型和语言模型是需要训练的。
这些模块的训练一般都是独立进行的,各有各的目标函数。
比如声学模型的训练目标是最大化训练语音的概率;语言模型的训练目标是最小化 困惑度(perplexity)。
由于各个模块在训练时不能互相取长补短,训练的目标函数又与系统整体的性能指标(一般是词错误率 WER)有偏差,这样训练出的网络往往达不到最优性能。
在语音识别领域的端到端分为:
-
端到端训练(end-to-end training):
一般指的是在训练好语言模型后,将声学模型和语言模型接在一起,以 WER 或它的一种近似为目标函数去训练声学模型。由于训练声学模型时要计算系统整体的输出,所以称为「端到端」训练。可以看出这种方法并没有彻底解决问题,因为语言模型还是独立训练的。 -
端到端模型(end-to-end models):
系统中不再有独立的声学模型、发音词典、语言模型等模块,而是从输入端(语音波形或特征序列)到输出端(单词或字符序列)直接用一个神经网络相连,让这个神经网络来承担原先所有模块的功能。典型的代表如使用 CTC 的 EESEN、使用注意力机制的 Listen, Attend and Spell [2]。这种模型非常简洁,但灵活性就差一些:一般来说用于训练语言模型的文本数据比较容易大量获取,但不与语音配对的文本数据无法用于训练端到端的模型。因此,端到端模型也常常再外接一个语言模型,用于在解码时调整候选输出的排名(rescoring)。
