1、聊天机器人的类型
从应用目的或者技术手段进行抽象,可以有以下两种划分方法:
目标驱动(Goal –Driven)VS 无目标驱动(Non-Goal Driven)聊天机器人
目标驱动的聊天机器人指的是聊天机器人有明确的服务目标或者服务对象;无目标驱动聊天机器人指的是聊天机器人并非为了特定领域服务目的而开发的,称作为开放领域的聊天机器人。
检索式 VS 生成式聊天机器人
检索式聊天机器人指的事先存在一个对话库,聊天系统接收到用户输入句子后,通过在对话库中以搜索匹配的方式进行应答内容提取;生成式聊天机器人,在接收到用户输入句子后,采用一定技术手段自动生成一句话作为应答。
2、几种主流技术思路
常见的几种主流技术包括:基于人工模板的聊天机器人、基于检索的聊天机器人、基于机器翻译技术的聊天机器人、基于深度学习的聊天机器人。
基于人工模板的技术通过人工设定对话场景,并对每个场景写一些针对性的对话模板,模板描述了用户可能的问题以及对应的答案模板。目前市场上各种类似于Siri的对话机器人中都大量使用了人工模板的技术,主要是其精准性是其他方法还无法比拟的。
基于检索技术的聊天机器人则走的是类似搜索引擎的路线,事先存储好对话库并建立索引,根据用户问句,在对话库中进行模糊匹配找到最合适的应答内容。
基于深度学习的聊天机器人技术,绝大多数技术都是在Encoder-Decoder(或者称作是Sequence to Sequence)深度学习技术框架下进行改进的。使用深度学习技术来开发聊天机器人相对传统方法来说整体思路是非常简单可扩展的。
3、深度学习构建聊天机器人
目前对于开放领域生成式聊天机器人技术而言,多数技术采用了Encoder-Decoder框架,所以本节首先描述Encoder-Decoder框架技术原理。
Encoder-Decoder框架
Encoder-Decoder框架可以看作是一种文本处理领域的研究模式,可以直观地去理解:把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<X,Y>,我们的目标是给定输入句子X,期待通过Encoder-Decoder框架来生成目标句子Y。X和Y可以是同一种语言,也可以是两种不同的语言。而X和Y分别由各自的单词序列构成,如图:
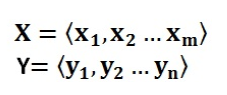
下图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示:

Encoder顾名思义就是对输入句子X进行编码,将输入句子通过非线性变换(如图)转化为中间语义表示C:
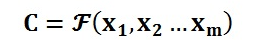
对于解码器Decoder来说,其任务是根据句子X的中间语义表示C和之前已经生成的历史信息来生成i时刻要生成的单词yi,如图:
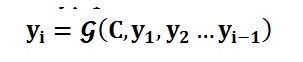
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子X生成了目标句子Y。
Encoder-Decoder框架应用-聊天机器人
对于聊天机器人来说,完全可以使用上述的Encoder-Decoder框架来解决技术问题。具体而言,对应的<X,Y>中,X指的是用户输入语句,一般称作Message,而Y一般指的是聊天机器人的应答语句,一般称作Response。其含义是当用户输入Message后,经过Encoder-Decoder框架计算,首先由Encoder对Message进行语义编码,形成中间语义表示C,Decoder根据中间语义表示C生成了聊天机器人的应答Response。这样,用户反复输入不同的Message,聊天机器人每次都形成新的应答Response,形成了一个实际的对话系统。
Encoder和Decoder采用的模型
在实际实现聊天系统的时候,一般Encoder和Decoder都采用RNN模型,RNN模型对于文本这种线性序列来说是最常用的深度学习模型,RNN的改进模型LSTM以及GRU模型也是经常使用的模型,对于句子比较长的情形,LSTM和GRU模型效果要明显优于RNN模型。尽管如此,当句子长度超过30以后,LSTM模型的效果会急剧下降,一般此时会引入Attention模型,这是一种体现输出Y和输入X句子单词之间对齐概率的神经网络模型,对于长句子来说能够明显提升系统效果。
采用Encoder-Decoder模型来建立对话机器人,一般的做法是采用收集Twitter(微博或媒体)或者微博中评论里的聊天信息来作为训练数据,用大量的此类聊天信息来训练Encoder-Decoder模型中RNN对应的神经网络连接参数。
下图,展示了利用微博评论对话数据训练好的聊天机器人的聊天效果,其中Post列指的是用户输入Message,其后三列是不同Encoder-Decoder方法产生的应答Response,而最后一列是基于传统检索方法的输出应答。
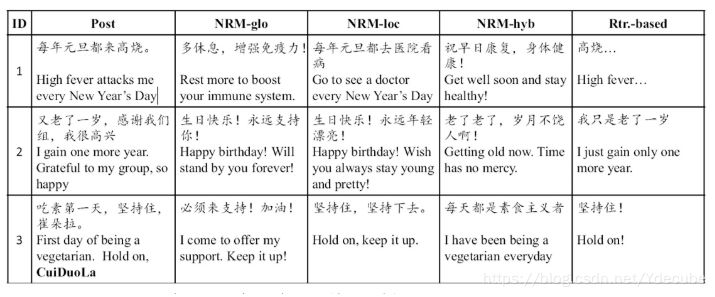
注:NRM,基于神经网络的对话模型“神经响应机”(Neural Responding Machine,NRM),用于人机之间的单轮对话(single-turn dialog)。
4、主要问题
针对聊天机器人研究领域需要特殊考虑的主要问题包括:多轮会话中的上下文机制问题、“安全回答”问题以及个性信息一致性问题。
多轮会话中的上下文问题
一般人们聊天并不是单纯的一问一答,在回答的时候到底说什么内容常常要参考上下文Context信息,也就是在用户当前输入问句Message之前两者的对话信息,因为存在多轮的一问一答,这种情形一般称为多轮会话。在多轮会话中,一般将上下文称作Context,当前输入称为Message,应答称作Response。
深度学习来解决多轮会话的关键是如何将上下文聊天信息Context引入到Encoder-Decoder模型中去的问题。很明显,上下文聊天信息Context应该引入到Encoder中,因为这是除了当前输入Message外的额外信息,有助于Decoder生成更好的会话应答Response内容。目前不同的研究主体思路都是这样的,无非在如何将Context信息在Encoder端建立模型或者说具体的融入模型有些不同而已。
在上文所述的Encoder-Decoder框架中,很容易想到一种直观地将Context信息融入Encoder的思路:只需要把上下文信息Context和信息Message拼接起来形成一个长的输入提供给Encoder,这样就把上下文信息融入模型中了。但是对于RNN模型来说,如果输入的线型序列长度越长,模型效果越差。
考虑到RNN对长度敏感的问题,文献3提出了针对聊天机器人场景优化的Encoder-Decoder模型,核心思想是将Encoder用多层前向神经网络来代替RNN模型,神经网络的输出代表上下文信息Context和当前输入Message的中间语义表示,而Decoder依据这个中间表示来生成对话Response。
下图是论文中提出的两种不同的融合方法,方法1对Context和Message不做明显区分,直接拼接成一个输入;而方法2则明确区分了Context和Message,在前向神经网络的第一层分别对其进行编码,拼接结果作为深层网络后续隐层的输入,核心思想是强调Message的作用,这个道理上是很好理解的,因为毕竟Response是针对Message的应答,Context只是提供了背景信息,所以应该突出Message的作用。


当然,除了Encoder从RNN替换为深层前向神经网络外,文献3与传统Encoder-Decoder还有一个显著区别,就是Decoder的RNN模型每个时刻t在输出当前字符的时候,不仅仅依赖t-1时刻的隐层状态和当前输入,还显示地将Encoder的中间语义编码直接作为t时刻RNN节点的输入,而不是像经典Encoder-Decoder模型那样把中间语义编码当做Decoder中RNN的最初输入。其出发点其实也是很直观的,就是在生成每个输出字符的时候反复强化中间语义编码的作用,这对于输出应答Response较长的时候无疑是有帮助作用的。
文献4给出了解决多轮会话上下文问题的另外一种思路(如下图所示),被称作层级神经网络(Hierarchical Neural Network,简称HNN)。HNN本质上也是Encoder-Decoder框架,主要区别在于Encoder采用了二级结构,上下文Context中每个句子首先用“句子RNN(Sentence RNN)”对每个单词进行编码形成每个句子的中间表示,而第二级的RNN则将第一级句子RNN的中间表示结果按照上下文中句子出现先后顺序序列进行编码,这级RNN模型可被称作“上下文RNN(Context RNN)”,其尾节点处隐层节点状态信息就是所有上下文Context以及当前输入Message的语义编码,以这个信息作为Decoder产生每个单词的输入之一,这样就可以在生成应答Response的单词时把上下文信息考虑进来。
如下图: 
如何解决“安全回答”(Safe Response)问题
采用经典的Encoder-Decoder模型构建开放领域生成式聊天机器人系统,一个比较容易产生的严重问题就是“安全回答”问题。什么是安全回答问题呢?就是说不论用户说什么内容,聊天机器人都用少数非常常见的句子进行应答,比如,中文的“是吗”、“呵呵”等。虽然说在很多种情况下这么回答也不能说是错误的,但是可以想象,如果用户遇到这样一位聊天对象会有多抓狂。这个现象产生的主要原因是聊天训练数据中确实很多回答都是这种宽泛但是无意义的应答,所以通过Encoder-Decoder模型机器人学会这种常见应答模式。如何解决聊天机器人“安全回答”问题,让机器产生多样化的应答是个很重要的课题。
文献5即在Sequence-to-Sequence框架下来解决“安全回答”问题。在聊天场景下,传统的使用Sequence-to-Sequence框架来进行模型训练时,其优化目标基本上是最大似然法(MLE),就是说给定用户输入Message,通过训练来最大化生成应答Response的概率,如下图(其中M代表message,R代表Response):
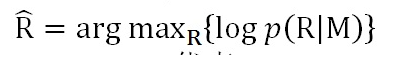
改进后的优化目标函数:最大化互信息(MMI),其目标函数如下图:
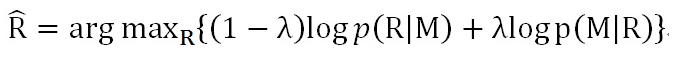
可以从公式差异中看出,MMI的优化目标除了最大化从Message生成应答Response的概率,同时加入了反向优化目标,即最大化应答Response产生Message的概率,其中lamda是控制两者哪个更重要的调节超参数。通过其名字“互信息”以及具体公式可以看出,这个优化目标函数要求应答Response和Message内容密切相关而不仅仅是考虑哪个Response更高概率出现,所以降低了那些非常常见的回答的生成概率,使得应答Response更多样化且跟Message语义更相关。
采用MMI作为目标函数明显解决了很多“安全回答”问题,下表是两个不同优化目标函数产生的应答Response的示例,其中Message列代表用户输入语句Message,S2S Response代表MLE优化目标产生的应答,MMI Response代表MMI优化目标产生的应答。

个性信息一致性问题
对于聊天助手等应用来说,聊天机器人往往会被用户当做一个具有个性化特性的虚拟人,比如经常会问:“你多大了”、“你的爱好是什么”、“你是哪里人啊”等。如果将聊天助手当做一个虚拟人,那么个性特征信息应该维护回答的一致性。利用经典的Sequence-to-Sequence模型训练出的聊天助手往往很难保持这种个性信息的一致性,这是因为Sequence-to-Sequence模型训练的都是单句Message对单句Response的映射关系,内在并没有统一维护聊天助手个性信息的场所,所以并不能保证每次相同的问题能够产生完全相同的应答。另外,不同的用户会喜欢不同聊天风格或者不同身份的聊天助手,所以聊天机器人应该能够提供不同身份和个性信息的聊天助手。
那么如何在Sequence-to-Sequence框架下采用技术手段维护聊天助手的个性一致性呢?文献6给出了一种比较典型的解决方案。参照文献6,我们可以改造出一个能够实现不同身份个性特征的聊天助手的思路。下图是其示意图:

其基本思路如下:聊天机器人系统可以定义不同身份和个性及语言风格的聊天助理身份,个性化信息通过Word Embedding的表达方式来体现,在维护聊天助手个性或身份一致性的时候,可以根据聊天对象的风格选择某种风格身份的聊天助手。整体技术框架仍然采用Sequence-to-Sequence架构,其基本思路是把聊天助手的个性信息导入到Decoder的输出过程中,就是说在采用RNN的Decoder生成应答Response的时候,每个t时刻,神经网络节点除了RNN标准的输入外,也将选定身份的个性化Word Embedding信息一并作为输入。这样就可以引导系统在输出时倾向于输出符合身份特征的个性化信息。核心思想是把聊天助手的个性信息在Decoder阶段能够体现出来,以此达到维护个性一致性的目的。
除此外,还有一些问题值得探讨,比如如何使得聊天机器人有主动引导话题的能力,因为一般聊天机器人都比较被动,话题往往都是由用户发起和引导,聊天机器人只是作为应答方,很少主动引导新话题。
5、TensorFlow
TensorFlow 是谷歌在DistBelief基础上发展的第二代人工智能学习系统。关于其名称来源:Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow是指张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
TensorFlow可广泛地应用于语音识别,自然语言理解,计算机视觉,广告等等。
