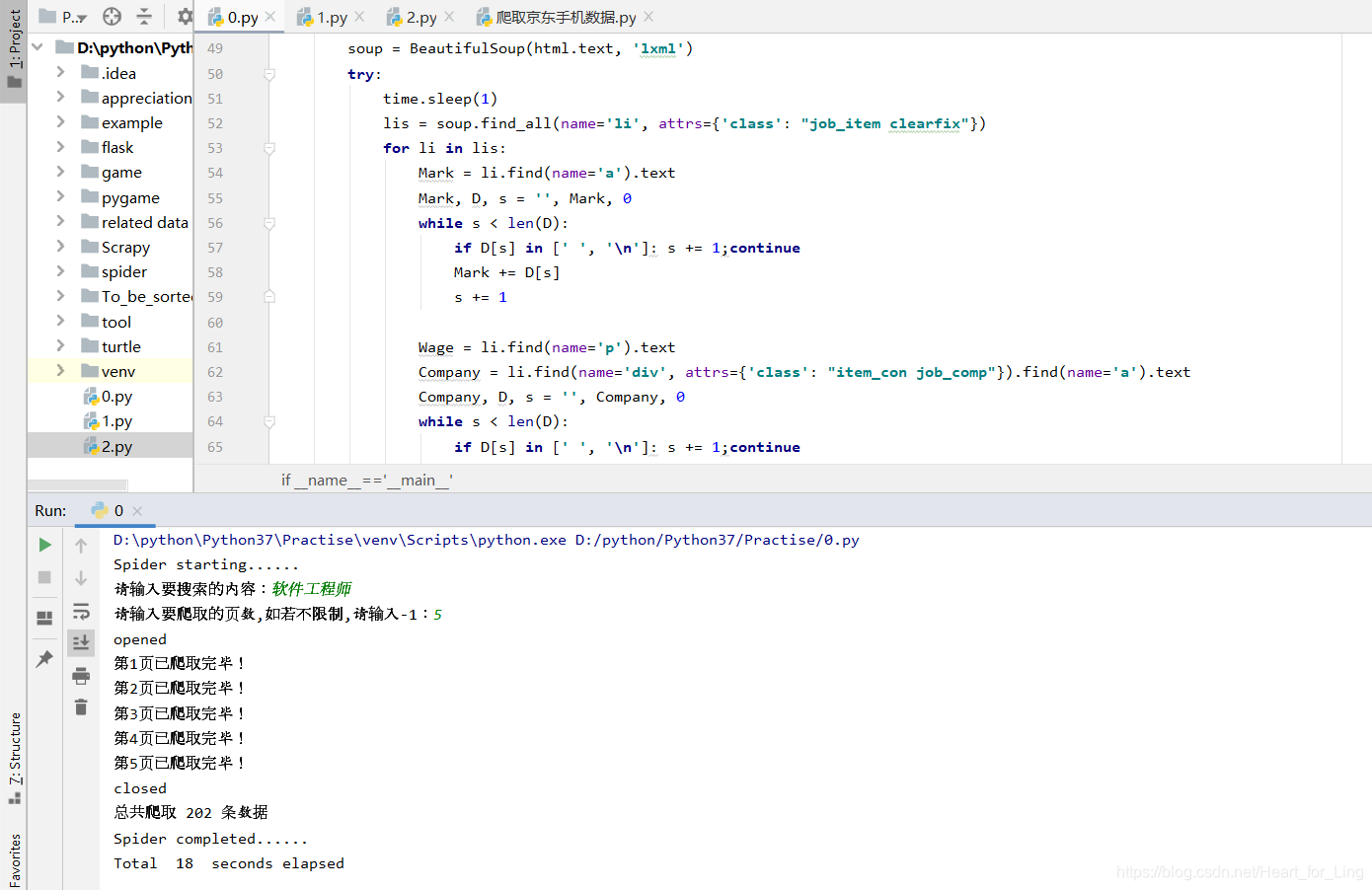
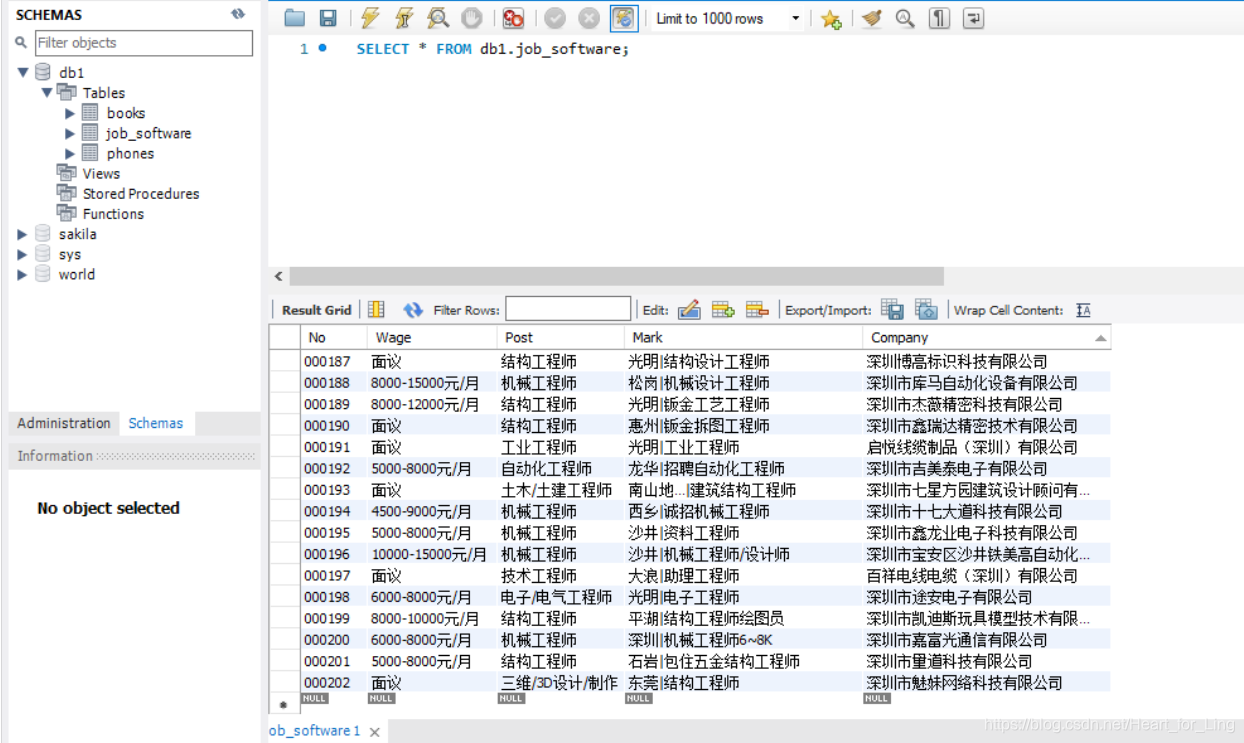
本次的模块类似:爬取京东的手机类商品数据 | selenium,但是是使用的requests库和BeautifulSoup库。
1、import
from bs4 import BeautifulSoup
import pymysql.cursors
import requests,urllib.parse,time,datetime
2、class Spider:
爬虫源码创建了一个爬虫类。如下简略:
class Spider:
#打开数据库,初始化
def opneDB(self):...
#关闭数据库
def closeDB(self):...
#数据插入数据库
def insertDB(self,No,Wage,Post,Mark,Company):...
#主要过程
def processSpider(self,url,Page,page=0):...
#执行爬虫,即主程序
def executeSpider(self,url):
2.1 opneDB
def startUp(self, url, key):
# Initializing Chrome browser
chrome_options = Options()
#下面两项为无头与禁止gpu加速;
#--headless比较重要,执行selenium时不会弹出浏览器窗口
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#创建Chrome浏览器
self.driver = webdriver.Chrome(chrome_options=chrome_options)#
# Initializing variables
self.No = 0
数据库的初始化
def openDB(self):
#初始化编号
self.No=0
print('opened')
try:
#连接数据库
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db='db1',charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#建表
try:
self.cursor.execute("drop table job_software")
except Exception as err:
print(err)
try:
sql = """
create table job_software(No varchar(32) primary key,Wage varchar(256),Post varchar(256),Mark text,Company text)"""
self.cursor.execute(sql)
except Exception as err:
print(err)
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
2.2 closeUp
关闭数据库,并输出爬取数据数量。
def closeUp(self):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条数据")
2.3 insertDB
数据库插入数据语句。每执行一次,count+1
def insertDB(self,No,Wage,Post,Mark,Company):
try:
if self.opened:
sql = "insert into job_software(No,Wage,Post,Mark,Company) values (%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(No,Wage,Post,Mark,Company))
self.count+=1
except Exception as err:
print(err)
2.4 progressSpider
这个模块主要是Spider执行的具体内容,读取源码,SP解码
def processSpider(self,url,Page,page=0):
kv = {'user-agent': 'Mozilla/5.0'}
html = requests.get(url, headers=kv)
soup = BeautifulSoup(html.text, 'lxml')
观察58搜索页的源代码,可以发现所需要的数据都在属性为class='job_item clearfix的标签li里,使用find_all即可得到所有的li标签。
BeautifulSoup查找元素的具体语法。
try:
time.sleep(1)
lis = soup.find_all(name='li', attrs={'class': "job_item clearfix"})
for li in lis:
Mark = li.find(name='a').text
Mark, D, s = '', Mark, 0
while s < len(D):
if D[s] in [' ', '\n']: s += 1;continue
Mark += D[s]
s += 1
Wage = li.find(name='p').text
Company = li.find(name='div', attrs={'class': "item_con job_comp"}).find(name='a').text
Company, D, s = '', Company, 0
while s < len(D):
if D[s] in [' ', '\n']: s += 1;continue
Company += D[s]
s += 1
Post = li.find(name='div', attrs={'class': "item_con job_comp"}).find(name='p').find(name='span').text
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
self.insertDB(no,Wage,Post,Mark,Company)
遍历完li标签后,即执行翻页的命令。观察得到下一页在class=next的a标签里,通过find语句提取其中的超链接,然后递归 progressSpider即可。
x = soup.find(name='a', attrs={'class': "next"})['href']
page+=1
print('第%d页已爬取完毕!'%page)
if page==Page:return
self.processSpider(x,Page,page)
2.5 executeSpider