前面的章节中,我们说到了如何发送发送,对应的,回顾之前的爬虫流程,在发送完请求之后,能够获取响应,这个时候就需要从响应中提取数据了.
1. 爬虫中数据的分类
在爬虫爬取到的数据中有很多不同类型的数据,我们需要了解数据的不同类型来规律的提取和解析数据.
根据响应的内容,我们可以将获得到的数据分为以下两类:
-
结构化数据:json,xml等
- 处理方式:直接转化为python类型
-
非结构化数据:HTML
- 处理方式:正则表达式、xpath
下面以某条的首页为例,介绍结构化数据和非结构化数据
-
结构化数据例子:
-
非结构化数据:

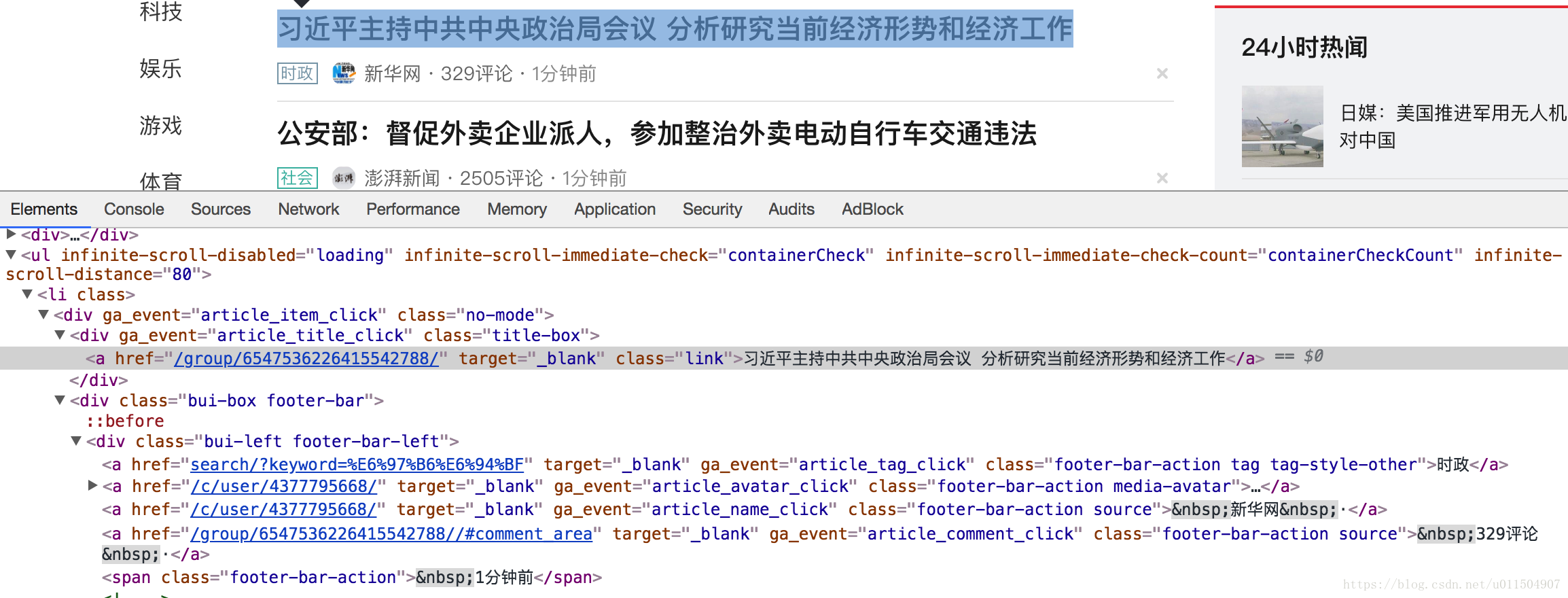
我们可以看到,第一张图我们捕获到的信息是JSON格式的,那什么是JSON呢?
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
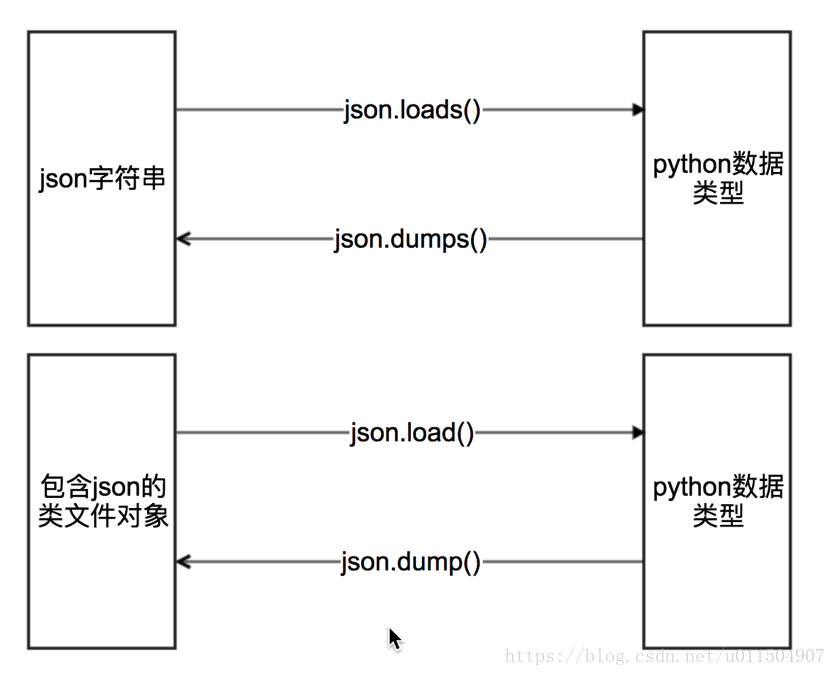
我们可以在Python中导入JSON库来解析.方法如下:
import json
json有四个方法供我们进行数据转换:
一般常用的就是前两种.
mydict = {'name': 'xiaoming', 'age': 18}
#json.dumps 实现python类型转化为json字符串
json_str = json.dumps(mydict)
#json.loads 实现json字符串转化为python的数据类型
my_dict = json.loads(json_str)
#json.dump 实现把python类型写入类文件对象
with open("temp.txt","w") as f:
json.dump(mydict,f,ensure_ascii=False,indent=2)
# json.load 实现类文件对象中的json字符串转化为python类型
with open("temp.txt","r") as f:
my_dict = json.load(f)
jsonpath模块
JsonPath 模块是用来解析多层嵌套的json数据;
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPath 对于 XML。
安装方法:pip install jsonpath
官方文档:http://goessner.net/articles/JsonPath
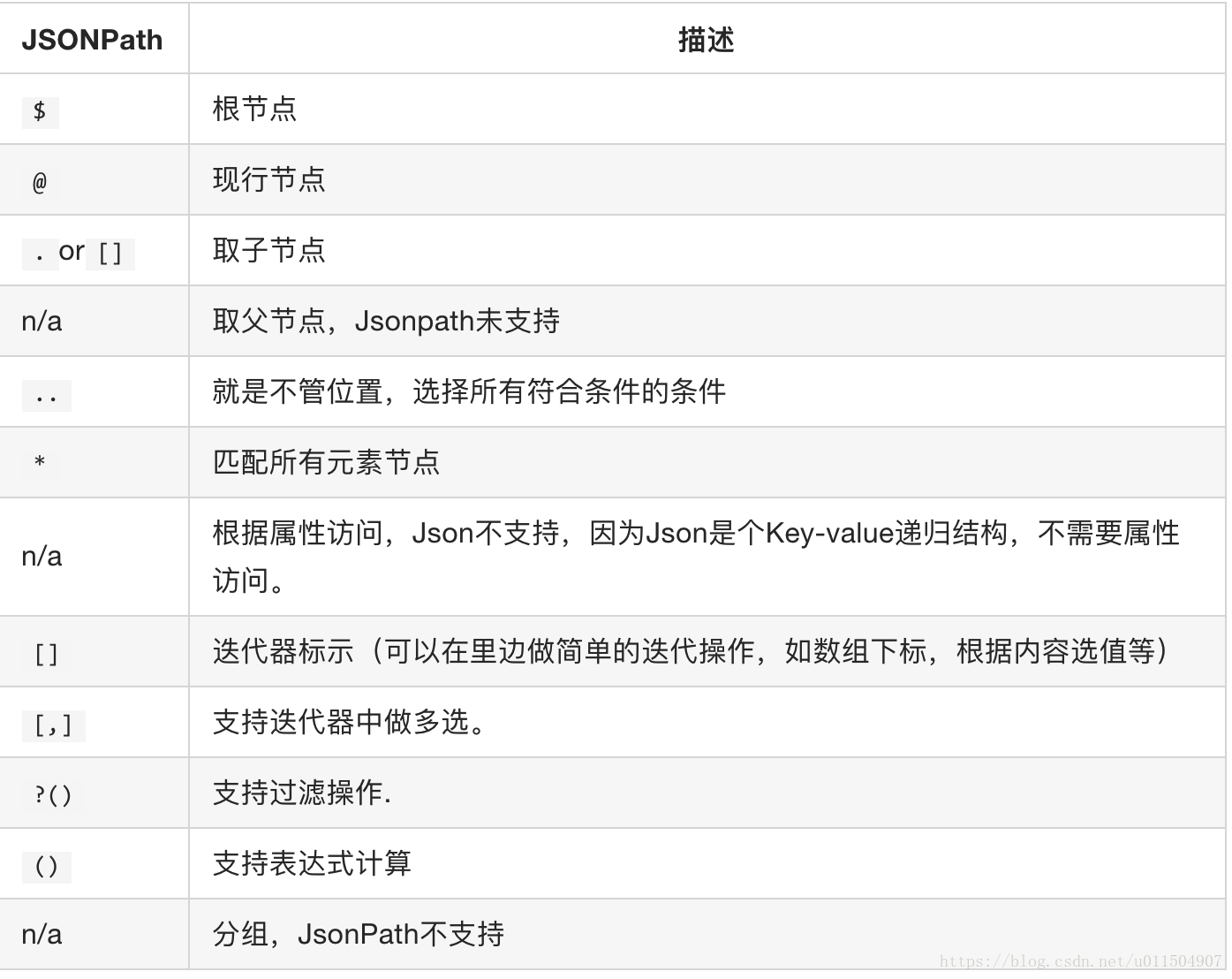
JsonPath与XPath语法对比:
代码示例:
我们以某钩网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市。
import requests
import jsonpath
import json
url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
response =requests.get(url)
html_str = response.content.decode()
# 把json格式字符串转换成python对象
jsonobj = json.loads(html_str)
# 从根节点开始,匹配name节点
citylist = jsonpath.jsonpath(jsonobj,'$..name')
fp = open('city.json','wb')
content = json.dumps(citylist, ensure_ascii=False)
fp.write(content.encode('utf-8'))
fp.close()
小练习:
爬取某钩网页面的招聘信息.https://www.lagou.com
源代码:
import requests
import jsonpath
import json
import time
class LaGou(object):
def __init__(self, work):
self.url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput='
}
self.proxies = {
'http': 'http://219.141.153.36'
}
self.work = work
self.file = open('work.json', 'w', encoding='utf-8')
def get_data(self, url, count):
session = requests.session()
data = {
'first': 'true',
'pn': str(count),
'kd': self.work
}
r = session.post(url, headers=self.headers, data=data)
print(r.status_code)
return r.content
def parse_data(self, data):
data_dict = json.loads(data.decode())
result = jsonpath.jsonpath(data_dict, '$..positionResult.result')
details_url = []
for res in result:
for content in res:
temp = dict()
temp['company'] = content['companyFullName']
temp['work'] = content['positionName']
temp['education'] = content['education']
temp['salary'] = content['salary']
temp['CreateTime'] = content['formatCreateTime']
temp['details_url'] = 'https://www.lagou.com/jobs/' + str(content['positionId']) + '.html'
details_url.append(temp)
return details_url
def save_data(self, work):
data = json.dumps(work, ensure_ascii=False) + ',\r'
self.file.write(data)
def __del__(self):
self.file.close()
def run(self):
url = self.url
count = 0
while True:
count += 1
time.sleep(4)
data = self.get_data(url, count)
work_list = self.parse_data(data)
print('正在保存第{}页数据!'.format(count))
for work in work_list:
self.save_data(work)
print('保存完毕')
print('--------------------------------')
if __name__ == '__main__':
lagou = LaGou('爬虫')
lagou.run()