关于track_running_stats用法的说明
添加BN来训练的过程中,我们更新running_mean和running_var,但是我们为了保证输入输出的一致性,我们不希望在验证的时候,还对输入的数据来更新running_mean和running_var,track_running_stats=True表示的是在训练的时候更新running_mean和running_var,而在测试的时候,只是使用训练时练好的running_mean和running_var,可以见参考[2]
如果track_running_stats=False那么训练的时候就用训练的batch来更新running_mean和running_var,测试的时候还会使用测试的batch数据从新算running_mean和running_var。可以参考[3]和[4]
学习率调整策略
Pytorch的学习率调整策略,可以看参考[5]和参考[12],特别是[12]中有很丰富的代码解释,如何具体应用这些学习率,特别是学习率衰减这方面。
权重初始化
权重初始化可以参考[6]
Batch Normalization和Instance Normalization
此图片来自于何凯明论文Group Normalization
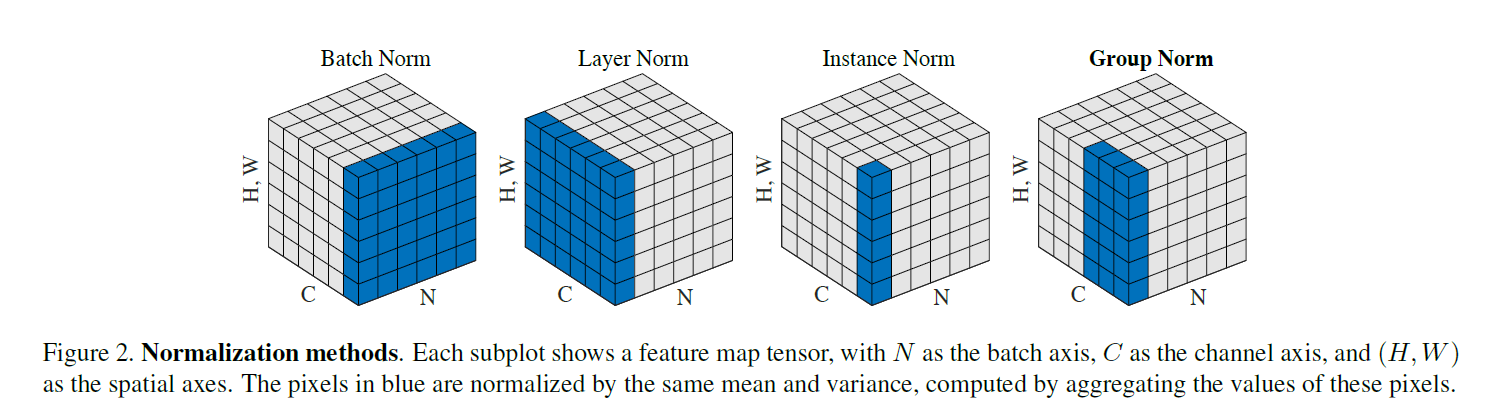
我们从图中可以比较明显的看到BN和IN之间的区别,BN是将每一个batch的每一个通道的每一组图片求mean和var,而IN是将单独一个图片的一个通道的数据求mean和var。区别就是一个是对batch求,一个是对一个图片求。
这样的区别也导致各自应用领域不同。对于BN而言,主要用在判别模型部分。在分类任务中,对每一个batch进行归一化可以更好地保证数据分布的一致性。特别是当batch size比较大的时候,batch的数据更容易代表总体。
IN主要用在生成模型部分。因为生成部分更多的是依赖单独一张图像的实例,对整个batch归一化不适合图像风格化,在风格迁移中使用Instance Normalization不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立。详情可以参考[7]和[8]
Gram矩阵
Gram矩阵简单解释可以看[9],此外,我还写了一篇如何用代码简单实现Gram矩阵的计算,可以参考[10]
Reference
[1]彻底明白Python partial
[2]Why track_running_stats is not set to False during eval
[3]知乎:BatchNorm2d增加的参数track_running_stats如何理解?
[4]BatchNorm2d: How to use the BatchNorm2d Module in PyTorch
[5]PyTorch学习之六个学习率调整策略
[6]Pytorch:参数初始化 笔记
[7]BN和IN的对比
[8]BatchNorm VS InstanceNorm
[9]风格迁移-风格损失函数(Gram矩阵)理解
[10]如何对batch的数据求Gram矩阵
[11]PatchGAN的理解和代码
[12]Pytorch中的学习率衰减方法
