pytorh 训练过程的坑
1、报错:input type (CUDAFloatTensor) and weight type (CPUFloatTensor) should be same.
先考虑:模型没有加载到GPU上,解决module.cuda()
其次:
假设网络模型是:
修改为如下: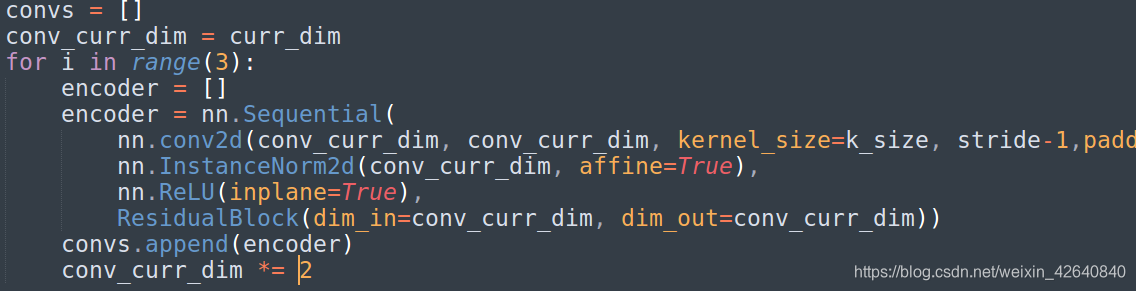 上面的图本身没有语法错误,而且在CPU上也能够正常运行,但是加载到GPU上的时候,在model = model.cuda()的作用下,网络其他部分已经被部署到GPU上,而encoder里面的结构还在cpu上面,所以需要改成下面的格式。经测试下面的结构可以正常运行。
上面的图本身没有语法错误,而且在CPU上也能够正常运行,但是加载到GPU上的时候,在model = model.cuda()的作用下,网络其他部分已经被部署到GPU上,而encoder里面的结构还在cpu上面,所以需要改成下面的格式。经测试下面的结构可以正常运行。
2、runtimeerror:one of variables needed for gradient computation has been modified by an inplace operation…
主要是我在搭建网络架构时,在考虑特征融合时采用add的方式,所以在卷积和BN之后没有直接加relu,而是在进入下一次的卷积的时候才加上了relu,所以不能像之前 nn.ReLU(inplace=True),而是直接nn.ReLU()。
inplace=True
意思是:是否将计算得到的值直接覆盖之前的值
计算结果不会有影响。利用in-place计算可以节省内(显)存,同时还可以省去反复申请和释放内存的时间。但是会对原变量覆盖,只要不带来错误就用。
3、pytorch 反向传播的时候,为了避免不必要的麻烦,不要使用 b = b…这种,
例如:a = f(a) 修改为: b = f(a)
a = d(a) c = d(b)
也不需要使用:a *= 2等等。直接写a = a *2
