Reference
1. http://solutionhacker.com/elasticsearch-architecture-overview/
2. https://github.com/batscars/advanced-java/blob/master/docs/high-concurrency/es-write-query-search.md
Elasticsearch是如何组织数据的
- Elasticsearch索引是组织数据的一个逻辑单位(类似数据库),保存在索引上的数据是一堆Json格式的相关文档
- 一个Elasticsearch索引包括一个或者多个分片,分布在不同的节点上(7.x版本后默认只有一个分片),主分片的数量在索引创建之后就确定了无法修改
- 每个分片可以拥有一个或者多个副本,默认为1。ES会保证主分片和副本分片不在同一个节点上。
- 每个分片就是个Lucene索引用来保存数据,且本身就是一个搜索引擎
- 一个Lucene索引包含多个分段,每个分段本身就是一个倒排索引
- 对于每一个搜索请求,索引中的每个分段都会被搜索,每个分段都需要消耗cpu,文件句柄和内存。所以分段数量越多,搜索的性能越低。lucene会在后台将小的分段合并成大的分段,将合并后的分段写入磁盘,删除旧的小分段。
- ES包含三种常见的节点类型: master,data和client。master节点主要负责协调集群任务,比如在节点间分配分片,添加和删除索引。data节点负责通过分片保存数据,创建索引,数据搜索,聚合等操作。client节点主要作为负载均衡的角色,帮助做创建索引和搜索请求的路由。
Elasticsearch搜索过程
分为两个阶段:
- 查询阶段:搜索请求首先到达协调节点,并将查询转发到索引中每个分片的副本(主副本或副本副本)。 每个分片将在本地执行查询,并将最相关的结果的文档ID(默认为10)传递回协调节点,协调节点将依次合并并排序以找到最相关的全局结果的文档ID。
- 提取阶段:在协调节点对所有结果进行排序以生成文档的全局排序列表之后,它随后从所有分片中请求原始文档。 所有分片将会获取所有需要获取的字段,然后将其返回到协调节点。 最后,最终的搜索结果被发送回客户端。
Index Refresh
提交文档索引请求后,它将添加到Translog并写入内存缓冲区。 下一次刷新索引时(默认情况下每秒进行一次),刷新过程将根据内存缓冲区的内容创建一个新的内存段,以便现在可以搜索文档。 然后它将清空内存缓冲区。 随着时间的流逝,会创建一堆分段。 随后,分段会在后台随时间合并在一起,以确保有效利用资源(每个段都使用文件句柄,内存和CPU)。 索引刷新是一项昂贵的操作,这就是为什么要定期进行刷新(默认设置),而不是在每次索引操作之后进行刷新。 如果您打算索引很多文档,而又不需要立即获取新信息以进行搜索,则可以通过减少刷新频率直到索引完成,或者甚至通过禁用索引来优化索引性能而不是搜索性能。如下图所示
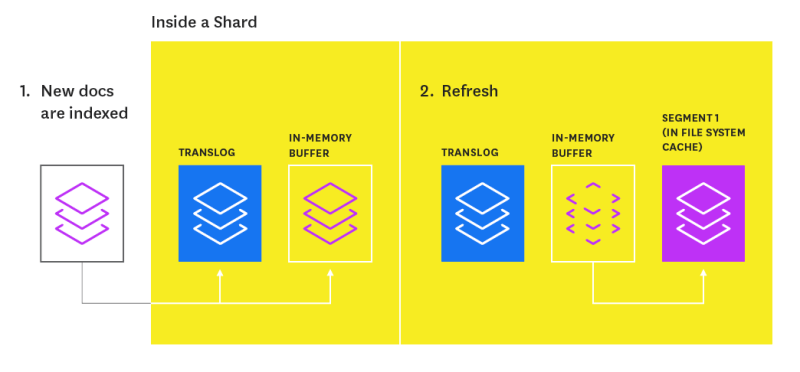
Index Flush
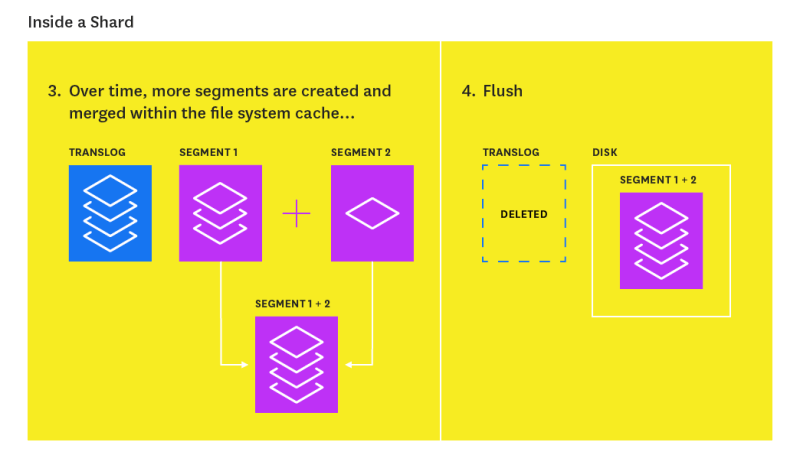
在上面的索引刷新过程中创建的内存中段不持久且不安全。 如果由于任何原因该节点关闭,它们将消失。 由于存在Translog,因此仍可以通过重播来恢复更改。 该日志每5秒或在每次成功索引,删除,更新或批量请求(以先到者为准)后,都会提交到磁盘。 但是,Translog有其自身的大小限制。 因此,每隔30分钟,或者每当事务日志达到最大大小(默认情况下为512MB)时,就会触发刷新。 在刷新期间,将刷新内存缓冲区中的所有文档(存储在新段中),所有内存段都将提交到磁盘,并清除Translog。
删除/更新数据
如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。