Statistical Phrase-Based Translation
这是基于短语的统计机器翻译中很经典的一篇文章。
摘要
我们提出了一种新的基于短语的翻译模型和解码算法,使我们能够评估和比较几个以前提出的基于短语的翻译模型。在我们的框架内,我们进行了大量实验以更好地理解和解释基于短语的模型为何胜过基于单词的模型。我们的经验结果适用于所有已检查的语言对,表明可以通过相对简单的方法获得最高的性能:从基于单词的对齐方式启发式学习短语翻译以及短语翻译的词汇加权。令人惊讶的是,学习长度超过三个单词的短语以及从高精度单词级对齐模型中学习短语不会对性能产生很大影响。 仅学习基于语法的短语会降低系统的性能。
评估框架
为了比较不同的短语提取方法,我们设计了一个统一的框架。我们提供了一个短语翻译模型和可与任何短语翻译表一起使用的解码器。
2.1 模型
短语翻译模型基于噪声通道模型。 我们使用贝叶斯规则来重新定义将外国句子f转换为英语e的翻译概率,如下所示:

在解码期间,将外来输入句子f分割为I个短语序列
。我们假设在所有可能的分段上都有一个均匀的概率分布。
每一个 中的外国短语 被翻译为英语短语 。英语短语可能会重新排序,短语翻译是用概率分布 来建模的,回想一下,由于贝叶斯规则,从建模的角度来看,翻译方向是相反的。
英语输出短语的重新排序由相对失真概率分布 建模,其中, 表示翻译成第i个英语短语的外来短语的开始位置, 表示翻译成第 i-1 个英语短语的外来短语的结束位置。
在我们所有的实验中,使用联合概率模型训练失真概率分布 (见3.3节)。与此同时,我们还可以使用更简单的失真模型 ,为参数 设置适当的值。
为了校准输出长度,除了三字母语言模型 外,我们还为每个生成的英语单词引入了一个因子 。这是一种优化性能的简单方法。通常,这个因子大于1,使输出偏置更长。
总之,根据我们的模型,给定外来输入句子的最佳英语输出句子
是
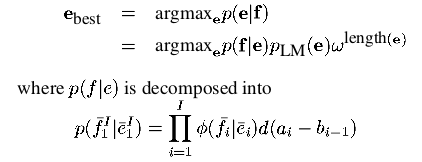
对于所有的实验,我们使用相同的训练数据,trigram语言模型和一个特殊的解码器。
2.2 解码器
我们为了比较不同的基于短语的翻译模型而开发的基于短语的译码器采用了一种波束搜索算法,类似于Jelinek[1998]的算法。英语输出句子以部分翻译(或假设)的形式从左到右生成。
我们从一个初始的空假设开始。通过对一个短语的翻译,在现有假设的基础上扩展一个新的假设:选择一个未翻译的外来词序列和一个可能的英语短语翻译。英语短语附加到现有的英语输出序列。将外来词标记为已翻译,并更新假设的概率成本。
没有未翻译的外国词的最高概率的最终假设是搜索的最终输出。
假设存储在堆栈中。堆栈sm包含所有已翻译的m个外国词的假设。我们重组了Och等人[2001]所做的搜索假设。 虽然这在一定程度上减少了每个堆栈中存储的假设的数量,但是堆栈大小相对于输入的句子长度是指数级的。这使得详尽的搜索不切实际。
因此,我们根据到目前为止所产生的成本和未来的成本估算值对弱假设进行修剪。对于每个堆栈,我们只保留最佳n个假设的波束。由于未来的成本估计并不完美,这就导致了搜索错误。我们未来的成本估算考虑了短语翻译的估算成本,但未考虑预期的失真成本。我们按以下方式计算此估计值:对于句子中任何位置的每种可能的短语翻译(我们称其为翻译选项),我们将其短语翻译概率乘以生成的英语短语的语言模型概率。 作为语言模型概率,我们对第一个单词使用单字母概率,对第二个单词使用双字母概率,对后面所有单词使用三字母概率。
给定翻译选项的成本,我们可以通过动态规划来计算任何连续的外国词序列的未来成本。注意,这是唯一可能的,因为我们忽略了失真成本。因为一个长度为n的外国输入句子只有n(n+1)/2个这样的序列。我们可以预先计算这些成本估算,并将它们存储在一个表中。
如果一个假设的未翻译外来词序列不完整,我们将查找每个序列的成本,并取其成本的乘积。光束尺寸例如每个堆栈中假设的最大数量固定为一定数量。翻译选项的数量与句子长度成线性关系。因此,波束搜索的时间复杂度与句子长度成二次关系,与波束大小成线性关系。由于光束大小限制了搜索空间,从而限制了搜索质量,因此我们必须在速度(低光束大小)和性能(高光束大小)之间找到适当的权衡。对于我们的实验,仅100的光束大小就足够了。 对于较大的波束,只有很少的句子会以不同的方式翻译。 使用我们的解码器,翻译1755个长度为5-15个字的句子,在2 GHz Linux系统上大约需要10分钟。换句话说,我们在确保高质量的同时实现了快速解码。
学习短语翻译的方法
我们进行了实验,以比较三种不同方法建立短语翻译概率表的性能。
我们还研究了许多变体。我们报告了德语-英语翻译任务的大部分实验结果,因为我们有足够的资源可用于该语言对。我们确认了其他语言对的实验重点。
作为第一种方法,我们从已由基于单词的翻译模型的培训工具包进行单词对齐的语料库中学习短语对齐:针对IBM模型的Giza ++ [Och and Ney,2000]工具包[Brown等, 1993]。提取试探法类似于Och等人 [1999]在比对模板工作中使用的方法。
许多研究人员建议着重研究具有语言动机的短语的翻译[Yamada and Knight,2001; 今村,2002]。如果它们是组成部分,即语法树中的子树(例如名词短语),则它们仅将单词序列视为短语。为了识别这些,我们使用单词对齐的语料库,该语料库带有统计语法分析器生成的语法分析树[Collins,1997; Schmidt和Schulte im Walde,2000年]。
第三种比较方法是Marcu和Wong [2002]提出的联合短语模型。
该模型直接学习并行语料库的短语级别对齐。
3.1 Phrases from Word-Based Alignments
开发Giza ++工具包是为了训练并行语料库中基于单词的翻译模型。
作为副产品,它会为此数据生成单词对齐。我们通过许多启发式方法来改善这种一致性,这将在第4.5节中详细介绍。
我们收集所有与单词对齐一致的对齐短语对:合法短语对中的单词仅彼此对齐,而不与外部单词对齐[Och et al。,1999]。
给定收集的短语对,我们通过相对频率估计短语翻译概率分布:
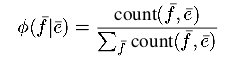
没有做平滑处理。
3.2 Syntactic Phrases(句法短语)
如果我们收集所有与单词对齐一致的短语对,则其中包括许多非直觉短语。例如,可以学习诸如“ house the”之类的短语的翻译。 直觉上,我们倾向于认为这样的短语没有帮助:将可能的短语限制为句法动机的短语可能会过滤掉这些非直觉的对。
评估仅包含语法短语的短语翻译模型的性能的另一个动机来自于最近构建语法翻译模型的努力[Yamada and Knight,2001; Wu,1997]。在这些模型中,单词的重排仅限于格式良好的语法分析树中的成分的重排。当用短语翻译来扩充这种模型时,通常只有跨整个句法子树的短语翻译才是可能的。重要的是要知道这是有用还是有害的限制。
与Imamura [2002]一致,我们将句法短语定义为被句法分析树中的单个子树覆盖的单词序列。我们收集如下语法短语对:对齐平行语料库,如第3.1节中所述。 我们然后用句法解析器解析语料库的两面[Collins,1997; Schmidt和Schulte im Walde,2000年]。对于与单词一致的所有短语对对齐方式,我们还要检查两个短语是否都是解析树中的子树。模型中仅包含这些短语。因此,学习了句法动机的短语对是在不了解语法的情况下学习的词组对的子集(第3.1节)。如第3.1节所述,词组翻译概率分布由相对频率估算。
3.3 Phrases from Phrase Alignments
Marcu和Wong [2002]提出了翻译模型假设不仅可以在单词级别,而且可以在短语级别建立词汇对应。为了学习这种对应关系,他们介绍了基于短语的联合概率模型,可在并行语料库中同时生成源句子和目标句子。
在Marcu和Wong的框架中进行的期望最大化学习既产生(i)联合概率分布
,又反映了短语
和
与翻译等价的概率; (ii)和联合分配d,这反映出位置i上的短语被翻译成位置j上的短语的概率。要在我们的框架中使用该模型,我们只需将Marcu和Wong [2002]估计的联合概率边缘化为条件概率。注意,该方法与Marcu和Wong自己采用的方法一致,后者在解码期间使用条件模型。
