网易云音乐火不火我不知道,但是评论很火,也见过很多的帖子抓取网易云音乐,今天自己抓一次,感觉有一点小坑,尤其是对初学者来说,今天正好把我抓取的过程和遇到的问题说一下。
找歌曲
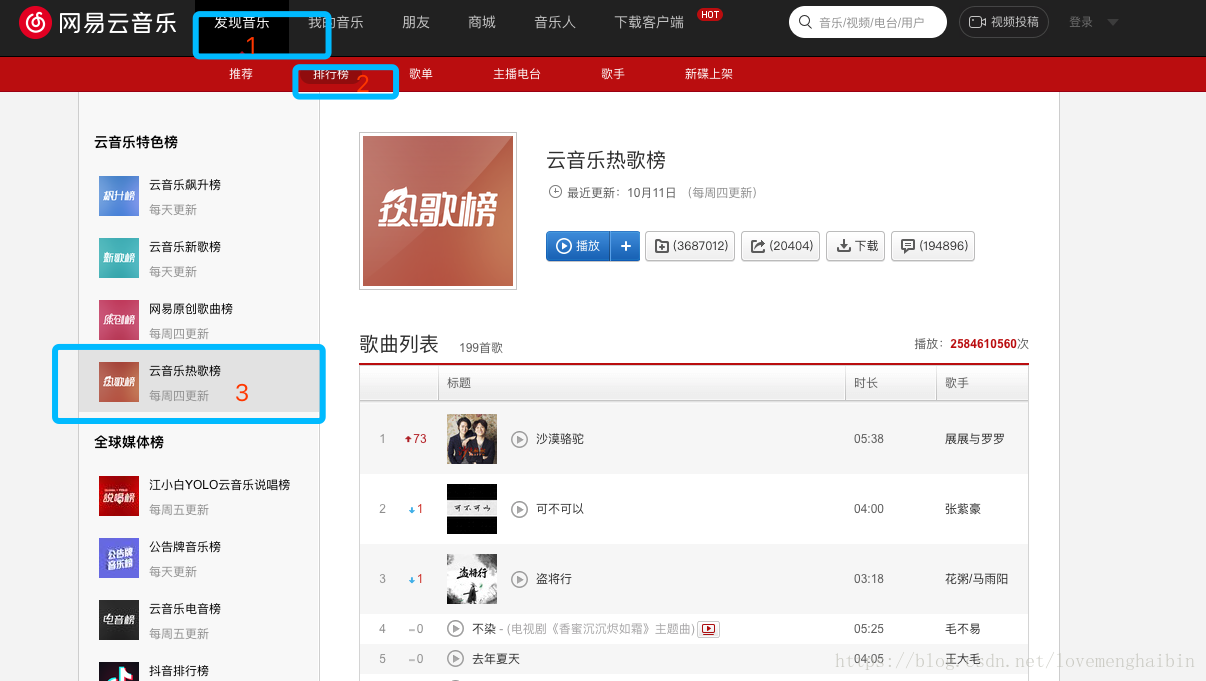
网易云音乐的网址是https://music.163.com/,打来连接我们选择如下信息
之所以找热门歌曲是评论多。这样抓到的数据也多。如果你是Chrome浏览器,F12打开调试工具,找到如下信息,用这个来访问歌曲列表,其他的浏览器自己查去吧,像什么firebug什么的,自己下载。
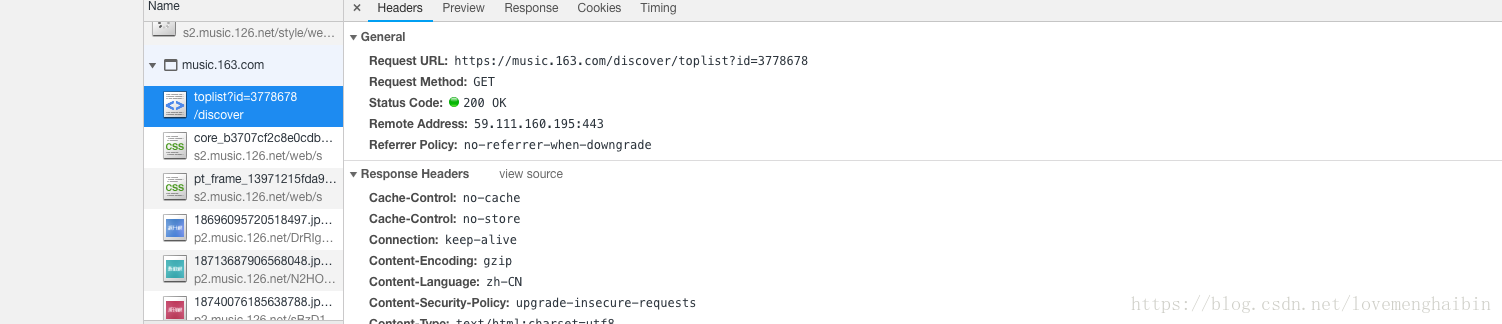
然后找到列表需要访问的url
用这个链接去访问,但是要注意的是,他的页面是嵌套了iframe的,所以如果用单存的xpath是找不到信息的,所以需要使用selenium,他也没什么,selenium这也没什么,就是模仿浏览器来爬虫,稍微慢一点,但是基本能满足所有的需求,这里要做的就是根据iframe来获取里边的html信息。解析这篇我们同样使用bs,下一篇再使用xpath来访问。
安装selenium
pip install selenium
安装 webdriver
下载:http://npm.taobao.org/mirrors/chromedriver/2.43/,直接下载你需要的版本,然后解压到你常用的目录。下边会用的到
获取soup
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
song_url = "https://music.163.com/discover/toplist?id=3778678"
# 获取驱动
driver_path = "/Users/menghaibin/Downloads/chromedriver"
chrome_options = Options()
chrome_options.add_argument('--headless')
drive = webdriver.Chrome(driver_path, chrome_options=chrome_options)
#头信息
headers = {
"Host": "music.163.com",
"Referer": "https://music.163.com/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
# 获取soup
def getSoup(url):
drive.get(url)
iframe = drive.find_elements_by_id('g_iframe')[0]
drive.switch_to.frame(iframe)
return BeautifulSoup(drive.page_source, "lxml")
主要就是利用selenium的驱动,获取iframe,然后从iframe中获取html,获取soup。
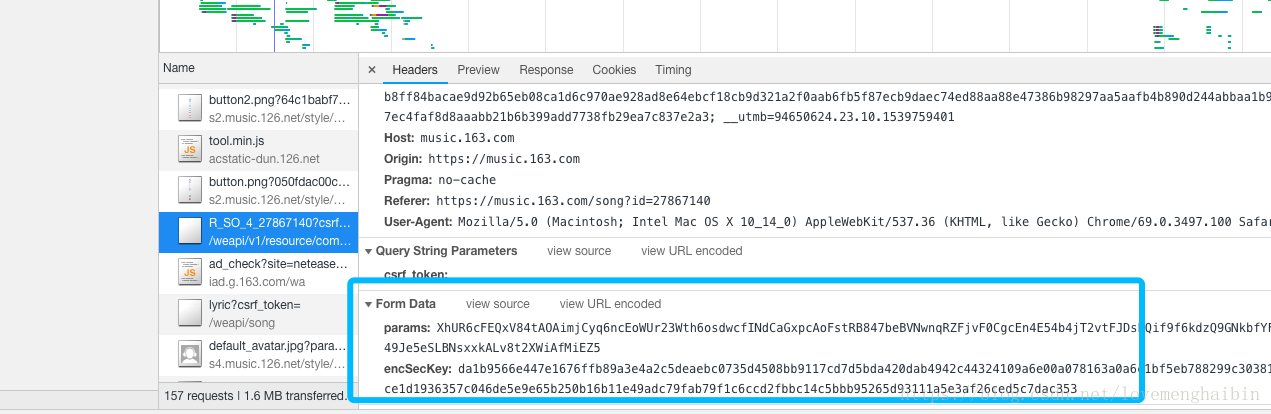
然后就是查询歌曲,查询页面了,这些和上一篇的东西类似,获取歌曲信息没什么大问题,但是我看了其他人抓取评论的时候,用的是这个:
这是一个post请求,看到这个参数,加密,好,上网查了一下,有大神居然解密了,牛逼,看了看大神解析的过程,牛逼,看不懂,所以我就干脆还是用老办法,直接用selenium的webdriver来生成chrome的驱动来获取信息吧。反正结果一样。
直接上代码
完整版
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
song_url = "https://music.163.com/discover/toplist?id=3778678"
# comment_url = "http://music.163.com/api/v1/resource/comments/R_SO_4_516997458?limit=20&offset=40"
driver_path = "/Users/menghaibin/Downloads/chromedriver"
chrome_options = Options()
chrome_options.add_argument('--headless')
drive = webdriver.Chrome(driver_path, chrome_options=chrome_options)
headers = {
"Host": "music.163.com",
"Referer": "https://music.163.com/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
def getSoup(url):
drive.get(url)
iframe = drive.find_elements_by_id('g_iframe')[0]
drive.switch_to.frame(iframe)
return BeautifulSoup(drive.page_source, "lxml")
# 获取歌曲信息
def getAllSong():
soup = getSoup(song_url)
nodes = soup.select(".m-table-rank tbody tr")
players = []
for node in nodes:
rank = node.select_one(".num").get_text()
song_href = "https://music.163.com" + node.select("td")[1].select_one("a")["href"]
song_name = node.select("td")[1].select_one("b")["title"]
song_id = node.select_one(".ply")["data-res-id"]
song_time = node.select("td")[2].select_one(".u-dur").get_text()
song_player = node.select("td")[3].select_one("span")["title"]
song_info = {
"rank": rank,
"song_href": song_href,
"song_name": song_name,
"song_id": song_id,
"song_time": song_time,
"song_player": song_player
}
players.append(song_info)
return players
def getComments(song_href):
soup = getSoup(song_href)
comment_nodes = soup.select(".cmmts .itm")
comments = []
for node in comment_nodes:
comment_user = node.select_one(".s-fc7").get_text()
comment_content = node.select_one(".f-brk").get_text()
comment_content_str = str(comment_content).split(":")[1]
comment_time = node.select_one("div .time").get_text()
comment_thumb_up = node.select_one("div .rp a").get_text()
comment_thumb_up_str = str(comment_thumb_up).replace("(", "").replace(")", "").strip()
if (comment_thumb_up_str.find("万") > 0 or (comment_thumb_up_str.strip() != '回复' and
comment_thumb_up_str.strip() != '' and int(
comment_thumb_up_str) > 1000)):
comment = {"user": comment_user,
"content": comment_content_str,
"time": comment_time,
"thumb_up": comment_thumb_up_str}
comments.append(comment)
return comments
if __name__ == '__main__':
list_songs = getAllSong()
for song in list_songs:
print(song)
print(getComments(song["song_href"]))
print("-" * 50)
drive.quit()
偷懒获取评论
但是在晚上看到了一个混迹大神,把获取评论的接口瞎改了一下,居然也可以获取评论,这里给大家贴出来http://music.163.com/api/v1/resource/comments/R_SO_4_516997458?limit=20&offset=40,真的是可以,也是厉害了,不过我没有直接用这种方法,还是老一套,这个借口获取的是json。还是挺方便的。
小结
以前都是小打小闹,都是一些简单的抓取,第一次遇到iframe,还是收获挺大的,刚刚学python抓取,暂时还没有找到替代selenium的更好的工具。
