目录
0.测试代码用例
package circledenydependency;
public class A {
private B b;
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
}
}
package circledenydependency;
public class B {
private C c;
public C getC() {
return c;
}
public void setC(C c) {
this.c = c;
}
}
package circledenydependency;
public class C {
private A a;
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
}
spring.xml配置
<!--spring-bean的循环依赖-->
<bean id="a" class="circledenydependency.A">
<property name="b" ref="b"></property>
</bean>
<bean id="b" class="circledenydependency.B">
<property name="c" ref="c"></property>
</bean>
<bean id="c" class="circledenydependency.C">
<property name="a" ref="a"></property>
</bean>
测试代码:
package circledenydependency;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
/**
* 1.构造函数的循环依赖无力回天
*/
public class BeanCircleDependencyTest {
public static void main(String[] args) {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
applicationContext.getBean("a");
}
}
1.什么是循环依赖?
循环依赖就是循环引用,就是两个或两个以上的Bean互相持有对方的对象,最后形成一个闭环。比如A依赖于B、B依赖于C、C又依赖于A。
2.怎么检测循环依赖?
检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。
3.Spring中的循环依赖?
- 构造器的循环依赖(无力回天)
- field属性的循环依赖
4.构造器循环依赖无法解决?
因为加入singletonFactories三级缓存的前提是执行了构造器才能暴漏出去,所以构造器的循环依赖没法解决。
5.Spring怎么解决循环依赖?
Spring的循环依赖的理论依据其实是基于Java的引用传递,当我们获取到对象的引用时,对象的field或则属性是可以延后设置的(但是构造器必须是在获取引用之前)。
Spring的单例对象的初始化主要分为三步:
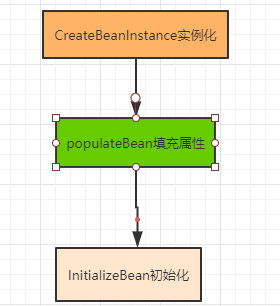
1.createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象。
2.populateBean:填充属性,这一步主要是多bean的依赖属性进行填充。
3.initializeBean:调用spring xml中的init 方法。
从初始化的过程可以知道循环依赖主要发生在实例化和填充属性这里(构造函数和属性循环依赖)。对于单例来说,在Spring容器的整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存。
源码中三级缓存
- singletonFactories 单例对象工厂的cache
- singletonObjects单例对象的cache
- earlySingletonObjects提前暴光的单例对象的Cache
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
我们在创建bean的时候,首先想到的是从cache中获取这个单例的bean,这个缓存就是singletonObjects。主要调用方法就就是:
doGetBean()方法中的getSingleton()方法
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
上面的代码需要解释两个参数:
- isSingletonCurrentlyInCreation()判断当前单例bean是否正在创建中,也就是没有初始化完成(比如A的构造器依赖了B对象所以得先去创建B对象, 或则在A的populateBean过程中依赖了B对象,得先去创建B对象,这时的A就是处于创建中的状态。)
- allowEarlyReference 是否允许从singletonFactories中通过getObject拿到对象
分析getSingleton()的整个过程,Spring首先从一级缓存singletonObjects中获取。如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取,如果获取到了则:
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
从singletonFactories中移除,并放入earlySingletonObjects中。其实也就是从三级缓存移动到了二级缓存。
从上面三级缓存的分析,我们可以知道,Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory,定义如下:
@FunctionalInterface
public interface ObjectFactory<T> {
/**
* Return an instance (possibly shared or independent)
* of the object managed by this factory.
* @return the resulting instance
* @throws BeansException in case of creation errors
*/
T getObject() throws BeansException;
}
addSingletonFactory
这个接口在AbstractAutowireCapableBeanFactory的doCreateBean()方法中被引用:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
这里就是解决循环依赖的关键,这段代码发生在createBeanInstance之后,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行初始化的第二步和第三步),但是已经能被人认出来了(根据对象引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来让大家认识,让大家使用。
这样做有什么好处呢?让我们来分析一下:
A的某个field依赖了B的实例对象,同时B的某个field依赖了A的实例对象”这种循环依赖的情况。
A首先完成了初始化的第一步(实例化),并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
知道了这个原理时候,肯定就知道为啥Spring不能解决“A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题了!因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
知道了这个原理时候,肯定就知道为啥Spring不能解决“A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题了!因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
原版:https://blog.csdn.net/u010853261/article/details/77940767
